Se você for imprimir esta página, escolha "Visualizar impressão" no seu navegador, ou clique em Versão para impressão, você irá ver esta página sem esse aviso, sem os elementos de navegação a esquerda ou acima, e sem as TOC's de cada página.
Atualize esta página para ter certeza de que está imprimindo a versão mais atual.
Para maiores informações sobre a versão para impressão, incluindo como fazer arquivos PDF realmente adequados para a impressão, veja Wikilivros:Versões para impressão.
Esta guia foi criado com a intenção de servir como referência a usuários Iniciantes e que estão tendo o primeiro contato com o sistema operacional GNU/Linux, Intermediários que já conhecem o básico sobre o funcionamento deste sistema operacional e já estão acostumados com os comandos, execução de programas e diretórios, Avançados que já dominam grande parte do sistema operacional e procuram aprender mais sobre os seus detalhes e configurações especiais ou como referência de consulta rápida.
A versão que esta lendo agora foi gerada com as seguintes opções:
Descrição detalhada de comandos
Opções usadas em comandos e programas
Observações
Exemplos para a melhor compreensão do assunto discutido.
Todas as marcas registradas citadas neste guia são propriedades de seus respectivos autores.
Gleydson Mazioli da Silva é Capixaba, nascido em Vila Velha. Amante de eletrônica desde criança, foi atraído para a informática através da curiosidade em funcionamento e reparo de hardware.
Se dedica ao sistema Linux desde 1997. Determinado na realização de testes de ferramentas e sistemas avaliando pontos fortes e fracos de cada uma. Logo que iniciou em Linux passou a estudar exaustivamente aspectos técnicos de distribuições e rede em Linux/BSD.
Entre coisas que gosta de fazer/implementar em Linux: possibilidade de pesquisa e atualização de conhecimento constante, níveis de segurança da informação (tanto físico e lógico), firewalls, virtualização, redes virtuais, integração de sistemas, forense computacional, documentação de processos, desenvolvimento de ferramentas GPL para a comunidade, depuração, desenvolvimento de documentações, etc.
Um dos desenvolvedores da distribuição Liberdade, CAETECT, Debian-BR e desenvolvedor oficial da distribuição Debian. Atuou como tradutor do LDP-BR, traduzindo vários HOW-TOs importantes para a comunidade Linux Brasileira. É um dos administradores do projeto CIPSGA, cuidando de uma infinidade de serviços que o projeto oferece a comunidade que deseja estrutura para hospedar, fortalecer e manter projetos em software livre.
Trabalhou para algumas empresas do Espírito Santo na implantação de sistemas em software livre e seu último trabalho foi atuando como consultor em servidores GNU/Linux para a companhia e processamento de dados de Campinas em São Paulo.
Não concorda totalmente com certificações, acreditando que a pessoa deva ter em mente procurar pontos fracos quando notar dificuldade na avaliação e melhorá-los. Mesmo assim possui certificação LPI nível 2 e um ISO9001 internacional em Administração Linux, como 1º lugar no ranking Brasileiro.
As seções sobre comandos/programas foram construídas após uso, teste e observação do comportamento das opções dos comandos/programas, help on line, páginas de manual, info pages e documentação técnica do sistema.
How-tos do Linux (principalmente o Networking Howto, Security-Howto) ajudaram a formar a base de desenvolvimento do guia e desenvolver algumas seções (versões Intermediário e Avançado somente).
Todos os exemplos e seções descritivas (da versão original do guia) foram inseridas pelo autor original .
Manual de Instalação da Debian GNU/Linux - Os capítulos contendo materiais extraídos do manual de instalação da Debian são muito úteis e explicativos, seria desnecessário reescrever um material como este. O texto é claro e didaticamente organizado, o documento aborda detalhes técnicos úteis sobre hardwares em geral e o Linux, ausentes nos manuais de outras distribuições Linux.
Wikificação, adaptação, esforços para o re-licenciamento e para o melhoramento da usabilidade do guia para o leitor (navegação, índices, categorização, etc.)
↑Citação: Gleydson Mazioli da Silva escreveu: «Estou muito feliz vendo o Foca GNU/Linux fazendo parte de um projeto tão positivo como o CIPSGA é para o crescimento e desenvolvimento do software livre nacional»
↑ 2,02,1Citação: Gleydson Mazioli da Silva escreveu: «entre eles(as) detalhes que passaram despercebidos durante muito tempo no guia»
↑Citação: Gleydson Mazioli da Silva escreveu: «Eles estão sendo muito úteis no desenvolvimento do guia»
↑Citação: Gleydson Mazioli da Silva escreveu: «Vale a pena destaca-lo por sua atual dedicação junto a distribuição Debian/GNU, sua tradução e a comunidade Open Source»
Bem vindo ao guia Foca GNU/Linux. O nome FOCA significa FOnte de Consulta e Aprendizado. Este guia é dividido em 3 níveis de aprendizado e a versão que esta lendo agora contém:
Iniciante
Intermediário
Entre o conteúdo do guia, você encontrará:
Textos explicativos falando sobre o sistema Linux, seus comandos, como manusear arquivos, diretórios, etc.
Explicações iniciais sobre as partes básicas do computador e periféricos
Comandos e Programas equivalentes entre o DOS/Windows e o GNU/Linux
Todos os materiais contidos na versão iniciante são ideais para quem está tendo o primeiro contato com computadores e/ou com o Linux. A linguagem usada é simples com o objetivo de explicar claramente o funcionamento de cada comando e evitando, sempre que possível, termos técnicos
Explicações necessárias para conhecer, operar, configurar, desenvolver, personalizar seu sistema Linux.
Uma lista de aplicativos clientes para serem usados em seu sistema GNU/Linux, com suas características, equipamento mínimo requerido e espaço em disco recomendado para instalação.
Particionamento de disco
Criação de partições e arquivos contendo o sistema de arquivos ext2, ext3, ext4, reiserfs ou xfs (para gravação de arquivos e diretórios) e swap (memória virtual) e as vantagens/desvantagens de se utilizar um arquivo ou partição para armazenamento de dados.
Compilação de programas/kernel, com explicações sobre cada uma das opções ajudando-o a decidir sobre a inclusão ou não.
Manipulação de módulos do kernel
Explicações sobre hardwares (Interrupções, DMA, Jumpers, Jumperless, Plug and Play) e como configurá-los no Linux, valores padrões e resolução de conflitos entre hardwares.
Dicas de como avaliar e comprar bons hardwares para que seu computador tenha o melhor desempenho (também válido para DOS, Windows e outras plataformas). Desta maneira você saberá porque alguns dispositivos de boa qualidade, como placas de rede, custam até 3 vezes mais caro que outras e o que a placa traz de especial para ter este diferencial.
Como modificar facilmente o idioma usado em seu sistema (localização) para o modo texto e modo gráfico.
Utilização de compactadores de arquivos
Mais opções para os comandos existentes na versão Iniciante do guia e novos comandos.
Conhecer os arquivos de configuração e arquivos básicos de segurança, entendendo para que eles servem e como usá-los.
Dicas de como saber escolher bons periféricos para uso no GNU/Linux e outros sistemas operacionais
Manutenção básica do computador (verificação do disco, desfragmentação) e manutenção automática feita através dos programas e scripts configurados.
Introdução à rede no Linux (com a configuração de dispositivos de rede, etc.).
Configurações básicas de segurança de Rede
Gerenciadores de inicialização (boot), o que são e como funcionam e como criar um arquivo de inicialização para inicializar o GNU/Linux pelo disco rígido ou mais de um Sistema Operacional.
Criação de Memória virtual no disco rígido e em arquivo.
Os materiais contidos na versão intermediário são ideais para quem já tem um conhecimento básico do sistema GNU/Linux mas que deseja se aprofundar neste sistema conhecendo os arquivos necessários para o funcionamento do GNU/Linux, como modificá-los e como estas modificações afetam o funcionamento do sistema.
Para melhor organização, dividi o guia em 3 versões: Iniciante, Intermediário e Avançado. Sendo que a versão Iniciante é voltada para o usuário que não tem nenhuma experiência no GNU/Linux. A última versão deste guia pode ser encontrada em: Página Oficial do guia Foca GNU/Linux.
Caso tiver alguma sugestão, correção, crítica para a melhoria deste guia, envie um e-mail para gleydson@guiafoca.org.
O Foca GNU/Linux é atualizado frequentemente, por este motivo recomendo que preencha a ficha do aviso de atualizações na página web em Página Oficial do guia Foca GNU/Linux no fim da página principal. Após preencher a ficha do aviso de atualizações, você receberá um e-mail sobre o lançamento de novas versões do guia e o que foi modificado, desta forma você poderá decidir em copiá-la, caso a nova versão contenha modificações que considera importantes.
Venho recebendo muitos elogios de pessoas do Brasil (e de países de fora também) elogiando o trabalho e a qualidade da documentação. Agradeço a todos pelo apoio, tenham certeza que este trabalho é desenvolvido pensando em repassar um pouco do conhecimento que adquiri ao começar o uso do Linux.
Também venho recebendo muitos e-mails de pessoas que passaram na prova LPI nível 1 e 2 após estudar usando o guia Foca GNU/Linux. Fico bastante feliz por saber disso, pois nunca tive a intenção de tornar o guia uma referência livre para estudo da LPI e hoje é usado para estudo desta difícil certificação que aborda comandos, serviços, configurações, segurança, empacotamento, criptografia, etc.
Os capítulos Introdução e Explicações básicas contém explicações teóricas sobre o computador, GNU/Linux, etc., você pode pular este capítulos caso já conheça estas explicações ou se desejar partir para a prática e quiser vê-los mais tarde, se lhe interessar.
Para quem está começando, muita teoria pode atrapalhar o aprendizado, é mais produtivo ver na prática o que o computador faz e depois por que ele faz isto. Mesmo assim, recomendo ler estes capítulos, pois seu conteúdo pode ser útil...
Coloquei abaixo algumas dicas para um bom começo:
Recomendo que faça a leitura deste guia e pratique imediatamente o que aprendeu. Isto facilita o entendimento do programa/comando/configuração.
É preciso ter interesse em aprender, se você tiver vontade em aprender algo, você terá menos dificuldade do que em algo que não gosta e está se obrigando a aprender.
Decorar não adianta, pelo contrário, só atrapalha no aprendizado. Você precisa entender o que o comando faz, deste modo você estará estimulando e desenvolvendo sua interpretação, e entenderá melhor o assunto (talvez até me de uma força para melhorar o guia ;-)
Curiosidade também é importante. Você talvez possa estar procurando um comando que mostre os arquivos que contém um certo texto, e isto fará você chegar até o comando grep, depois você conhecerá suas opções, etc.
Não desanime vendo outras pessoas que sabem mais que você, lembre-se que ninguém nasce sabendo :-). Uma pessoa pode ter mais experiência em um assunto no sistema como compilação de programas, configuração, etc., e você pode ter mais interesse em redes.
Ninguém pode saber tudo da noite para o dia, não procure saber tudo sobre o sistema de uma só vez senão não entenderá NADA. Caso tenha dúvidas sobre o sistema, procure ler novamente a seção do guia; e, caso ainda não tenha entendido, procure ajuda nas página de manual, (veja Páginas de Manual), ou nas listas de discussão, (veja Listas de discussão), ou me envie uma mensagem gleydson@guiafoca.org.
Certamente você buscará documentos na Internet que falem sobre algum assunto que este guia ainda não explica. Muito cuidado! O GNU/Linux é um sistema que cresce muito rapidamente, a cada semana uma nova versão é lançada, novos recursos são adicionados, seria maravilhoso se a documentação fosse atualizada com a mesma frequência.
Infelizmente a atualização da documentação não segue o mesmo ritmo (principalmente aqui no Brasil). É comum você encontrar na Internet documentos da época quando o kernel estava na versão 2.0.20, 2.2.30, 2.4.8, etc. Estes documentos são úteis para pessoas que por algum motivo necessitam operar com versões antigas do Kernel Linux, mas podem trazer problemas ou causarem má impressão do GNU/Linux em outras pessoas.
Por exemplo, você pode esbarrar pela Internet com um documento que diz que o Kernel não tem suporte aos "nomes extensos" da VFAT (Windows 95), isto é verdade para kernels anteriores ao 2.0.31, mas as versões mais novas do que a 2.0.31 reconhecem, sem problemas, os nomes extensos da partição Windows VFAT.
Uma pessoa desavisada pode ter receio de instalar o GNU/Linux em uma mesma máquina com Windows por causa de um documento como este. Para evitar problemas deste tipo, verifique a data de atualização do documento, se verificar que o documento está obsoleto, contacte o autor original e peça a ele que retire aquela seção na próxima versão que será lançada.
O GNU/Linux é considerado um sistema mais difícil do que os outros, mas isto é porque ele requer que a pessoa realmente aprenda e conheça computadores e seus periféricos antes de fazer qualquer coisa (principalmente se você é um técnico em manutenção, redes, instalações, etc., e deseja oferecer suporte profissional a este sistema).
Você conhecerá mais sobre computadores, redes, hardware, software, discos, saberá avaliar os problemas e a buscar a melhor solução, enfim as possibilidades de crescimento neste sistema operacional dependem do conhecimento, interesse e capacidade de cada um.
A interface gráfica existe, mas os melhores recursos e flexibilidade estão na linha de comando. Você pode ter a certeza de que o aprendizado no GNU/Linux o ajudará a ter sucesso e menos dificuldade em usar qualquer outro sistema operacional.
Peça ajuda a outros usuários do GNU/Linux quando estiver em dúvida ou não souber fazer alguma coisa no sistema. Você pode entrar em contato diretamente com outros usuários ou através de listas de discussão (veja Listas de discussão).
É assumido que você já tenha seu GNU/Linux instalado e funcionando. É assumido que você tenha entendido a função de boa parte dos comandos que consta na versão iniciante do Foca Linux, arquivos e permissões de acesso. Em resumo, que saiba decidir quando e qual(is) comando(s) deve usar em cada situação.
Caso não entenda as explicações da versão INTERMEDIÁRIO, recomendo que faça a leitura da versão INICIANTE do Foca Linux que pode ser encontrada em http://www.guiafoca.org.
Este guia não cobre a instalação do sistema. Para detalhes sobre instalação, consulte a documentação que acompanha sua distribuição GNU/Linux.
Kernel mais o conjunto de ferramentas GNU compõem o Sistema Operacional denominado GNU/Linux
O Sistema Operacional é o conjunto de programas que fazem a interface do usuário e seus programas com o computador. Ele é responsável pelo gerenciamento de recursos e periféricos (como memória, discos, arquivos, impressoras, CD-ROMs, etc.), interpretação de mensagens e a execução de programas.
No Linux, o Kernel mais o conjunto de ferramentas GNU compõem o Sistema Operacional. O kernel (que é a base principal de um sistema operacional) poderá ser construído de acordo com a configuração do seu computador e dos periféricos que possui.
O Linux é um kernel criado em 1991 por Linus Torvalds na universidade de Helsinki na Finlândia.É distribuído gratuitamente pela Internet. Seu código fonte é liberado como Free Software (software livre), sob licença GPL (General Public License), o aviso de copyright do kernel feito por Linus descreve detalhadamente isto e mesmo ele não pode fechar o sistema para que seja usado apenas comercialmente.
Isto quer dizer que você não precisa pagar nada para usar o Linux, e não é crime fazer cópias para instalar em outros computadores, nós inclusive incentivamos você a fazer isto. Ser um sistema de código aberto pode explicar a performance, estabilidade e velocidade em que novos recursos são adicionados ao sistema.
O Linux junto com os programas do projeto GNU formam o sistema operacional GNU/Linux, no entanto normalmente as pessoas falam Linux referindo-se ao GNU/Linux e possivelmente essa prática também ficará visível ao longo do livro.
Para rodar o Linux você precisa, no mínimo, de um computador 386 SX com 2 MB de memória (para um kernel até a série 2.2.x) ou 4MB (para kernels 2.4 e 2.6) e 100MB disponíveis em seu disco rígido para uma instalação básica e funcional.
O sistema segue o padrão POSIX que é o mesmo usado por sistemas UNIX e suas variantes. Assim, aprendendo o Linux você não encontrará muita dificuldade em operar um sistema do tipo UNIX, FreeBSD, HPUX, SunOS, etc., bastando apenas aprender alguns detalhes encontrados em cada sistema.
O código fonte aberto permite que qualquer pessoa veja como o sistema funciona (útil para aprendizado), corrija algum problema ou faça alguma sugestão sobre sua melhoria, esse é um dos motivos de seu rápido crescimento, do aumento da compatibilidade de periféricos (como novas placas sendo suportadas logo após seu lançamento) e de sua estabilidade.
Outro ponto em que ele se destaca é o suporte que oferece a placas, CD-Roms e outros tipos de dispositivos de última geração e mais antigos (a maioria deles já ultrapassados e sendo completamente suportados pelo sistema operacional). Este é um ponto forte para empresas que desejam manter seus micros em funcionamento e pretendem investir em avanços tecnológicos com as máquinas que possui.
Hoje o Linux é desenvolvido por milhares de pessoas espalhadas pelo mundo, cada uma fazendo sua contribuição ou mantendo alguma parte do kernel gratuitamente. Linus Torvalds ainda trabalha em seu desenvolvimento e na coordenação dos grupos de trabalho do kernel.
O suporte ao sistema também se destaca como sendo o mais eficiente e rápido do que qualquer programa comercial disponível no mercado. Existem centenas de consultores especializados espalhados ao redor do mundo. Você pode se inscrever em uma lista de discussão e relatar sua dúvida ou alguma falha, e sua mensagem será vista por centenas de usuários na Internet e algum irá te ajudar ou avisará as pessoas responsáveis sobre a falha encontrada para devida correção. Para detalhes, veja Listas de discussão.
É livre e desenvolvido voluntariamente por programadores experientes, hackers, e contribuidores espalhados ao redor do mundo que tem como objetivo a contribuição para a melhoria e crescimento deste sistema operacional.
Muitos deles estavam cansados do excesso de propaganda (Marketing) e da baixa qualidade de sistemas comerciais existentes
Também recebe apoio de grandes empresas como IBM, Sun, HP, etc. para seu desenvolvimento
Convivem sem nenhum tipo de conflito com outros sistemas operacionais (com o DOS, Windows, OS/2) no mesmo computador.
Multitarefa real
Multiusuário
Suporte a nomes extensos de arquivos e diretórios (255 caracteres)
Conectividade com outros tipos de plataformas como Apple, Sun, Macintosh, Sparc, Alpha, PowerPc, ARM, Unix, Windows, DOS, etc.
Utiliza permissões de acesso a arquivos, diretórios e programas em execução na memória RAM.
Proteção entre processos executados na memória RAM
Suporte a mais de 63 terminais virtuais (consoles)
Modularização - O Linux somente carrega para a memória o que é usado durante o processamento, liberando totalmente a memória assim que o programa/dispositivo é finalizado
Devido a modularização, os drivers dos periféricos e recursos do sistema podem ser carregados e removidos completamente da memória RAM a qualquer momento. Os drivers (módulos) ocupam pouco espaço quando carregados na memória RAM (cerca de 6Kb para a Placa de rede NE 2000, por exemplo)
Não há a necessidade de se reiniciar o sistema após modificar a configuração de qualquer periférico ou parâmetros de rede. Somente é necessário reiniciar o sistema no caso de uma instalação interna de um novo periférico, falha em algum hardware (queima do processador, placa mãe, etc.).
Não precisa de um processador potente para funcionar. O sistema roda bem em computadores 386Sx 25 com 4MB de memória RAM (sem rodar o sistema gráfico X, que é recomendado 32MB de RAM). Já pensou no seu desempenho em um Pentium, Xeon, ou Athlon? ;-)
Suporte nativo a múltiplas CPUs, assim processadores como Dual Core Athlon Duo, Quad Core tem seu poder de processamento integralmente aproveitado.
Suporte nativo a dispositivos SATA, PATA, Fiber Channel
Suporte nativo a virtualização, onde o Linux se destaca como plataforma preferida para execução de outros sistemas operacionais.
O crescimento e novas versões do sistema não provocam lentidão, pelo contrário, a cada nova versão os desenvolvedores procuram buscar maior compatibilidade, acrescentar recursos úteis e melhor desempenho do sistema (como o que aconteceu na passagem do kernel 2.0.x para 2.2.x, da 2.2.x para a 2.4.x).
Não é requerido pagamento de licença para usá-lo. O GNU/Linux é licenciado de acordo com os termos da GPL.
Acessa corretamente discos formatados pelo DOS, Windows, Novell, OS/2, NTFS, SunOS, Amiga, Atari, Mac, etc.
O LINUX NÃO É VULNERÁVEL A VÍRUS! Devido a separação de privilégios entre processos e respeitadas as recomendações padrão de política de segurança e uso de contas privilegiadas (como a de root, como veremos adiante), programas como vírus tornam-se inúteis pois tem sua ação limitada pelas restrições de acesso do sistema de arquivos e execução.
Qualquer programa (nocivo ou não) poderá alterar partes do sistema que possui permissões (será abordado como alterar permissões e tornar seu sistema mais restrito no decorrer do guia). Frequentemente são criados exploits que tentam se aproveitar de falhas existentes em sistemas desatualizados e usá-las para danificar o sistema. Erroneamente este tipo de ataque é classificado como vírus por pessoas mal informadas e são resolvidas com sistemas bem mantidos. Em geral, usando uma boa distribuição que tenha um bom sistema de atualização, 99.9% dos problemas com exploits são resolvidos.
Rede TCP/IP mais rápida que no Windows e tem sua pilha constantemente melhorada. O GNU/Linux tem suporte nativo a redes TCP/IP e não depende de uma camada intermediária como o WinSock. Em acessos via modem à Internet, a velocidade de transmissão é 10% maior.
Jogadores do Quake, ou de qualquer outro tipo de jogo via Internet, preferem o GNU/Linux por causa da maior velocidade do Jogo em rede. É fácil rodar um servidor Quake em seu computador e assim jogar contra vários adversários via Internet.
Roda aplicações DOS através do DOSEMU, QEMU, BOCHS. Para se ter uma ideia, é possível dar o boot em um sistema DOS qualquer dentro dele e ao mesmo tempo usar a multitarefa deste sistema.
Roda aplicações Windows através do WINE.
Suporte a dispositivos infravermelho.
Suporte a rede via rádio amador.
Suporte a dispositivos Plug-and-Play.
Suporte a dispositivos USB.
Suporte nativo a cartões de memória
Suporte nativo a dispositivos I2C
Integração com gerenciamento de energia ACPI e APM
Suporte a Fireware.
Dispositivos Wireless.
Vários tipos de firewalls de alta qualidade e com grande poder de segurança de graça.
Roteamento estático e dinâmico de pacotes.
Ponte entre Redes, proxy arp
Proxy Tradicional e Transparente.
Possui recursos para atender a mais de um endereço IP na mesma placa de rede, sendo muito útil para situações de manutenção em servidores de redes ou para a emulação de "mais computadores" virtualmente.
O servidor WEB e FTP podem estar localizados no mesmo computador, mas o usuário que se conecta tem a impressão que a rede possui servidores diferentes.
Os sistemas de arquivos usados pelo GNU/Linux (Ext2, Ext3, Ext4, reiserfs, xfs, jfs) organizam os arquivos de forma inteligente evitando a fragmentação e fazendo-o um poderoso sistema para aplicações multi-usuárias exigentes e gravações intensivas.
Permite a montagem de um servidor de publicação Web, E-mail, News, etc. com um baixo custo e alta performance. O melhor servidor Web do mercado, o Apache, é distribuído gratuitamente junto com a maioria das distribuições Linux. O mesmo acontece com o Sendmail.
Por ser um sistema operacional de código aberto, você pode ver o que o código fonte (instruções digitadas pelo programador) faz e adaptá-lo as suas necessidades ou de sua empresa. Esta característica é uma segurança a mais para empresas sérias e outros que não querem ter seus dados roubados (você não sabe o que um sistema sem código fonte faz na realidade enquanto está processando o programa).
Suporte a diversos dispositivos e periféricos disponíveis no mercado, tanto os novos como obsoletos.
Pode ser executado em 16 arquiteturas diferentes (Intel, Macintosh, Alpha, Arm, etc.) e diversas outras sub-arquiteturas.
Empresas especializadas e consultores especializados no suporte ao sistema espalhados por todo o mundo.
Entre muitas outras características que você descobrirá durante o uso do sistema.
TODOS OS ÍTENS DESCRITOS ACIMA SÃO VERDADEIROS E TESTADOS PARA QUE TIVESSE PLENA CERTEZA DE SEU FUNCIONAMENTO
Só o kernel GNU/Linux não é suficiente para se ter uma sistema funcional, mas é o principal.
Existem grupos de pessoas, empresas e organizações que decidem "distribuir" o Linux junto com outros programas essenciais (como por exemplo editores gráficos, planilhas, bancos de dados, ambientes de programação, formatação de documentos, firewalls, etc).
Este é o significado básico de distribuição. Cada distribuição tem sua característica própria, como o sistema de instalação, o objetivo, a localização de programas, nomes de arquivos de configuração, etc. A escolha de uma distribuição é pessoal e depende das necessidades de cada um.
Algumas distribuições bastante conhecidas são: Slackware, Debian, Red Hat, Mandriva, Suse, Monkey, todas usando o SO Linux como kernel principal (a Debian é uma distribuição independente de kernel e pode ser executada sob outros kernels, como o GNU hurd e GNU Kfreebsd ).
A escolha de sua distribuição deve ser feita com muita atenção, não adianta muita coisa perguntar em canais de IRC sobre qual é a melhor distribuição, ser levado pelas propagandas, pelo vizinho, etc. O melhor caminho para a escolha da distribuição, acredito eu, seria perguntar as características de cada uma e porque essa pessoa gosta dela ao invés de perguntar qual é a melhor, porque quem lhe responder isto estará usando uma distribuição que se encaixa de acordo com suas necessidade e esta mesma distribuição pode não ser a melhor para lhe atender.
Segue abaixo as características de algumas distribuições seguidas do site principal e endereço ftp:
Debian
http://www.debian.org/ - Distribuição desenvolvida e atualizada através do esforço de voluntários espalhados ao redor do mundo, seguindo o estilo de desenvolvimento GNU/Linux. Por este motivo, foi adotada como a distribuição oficial do projeto GNU. Possui suporte a língua Portuguesa, é a única que tem suporte a 14 arquiteturas diferentes (i386, Alpha, Sparc, PowerPc, Macintosh, Arm, etc.) e aproximadamente 15 sub-arquiteturas. A instalação da distribuição pode ser feita tanto através de Disquetes, CD-ROM, Tftp, Ftp, NFS ou através da combinação de vários destes em cada etapa de instalação.
Acompanha mais de 18730 programas distribuídos em forma de pacotes divididos em 10 CDs binários e 8 de código fonte, cada um destes programas são mantidos e testados pela pessoa responsável por seu empacotamento. Os pacotes são divididos em diretórios de acordo com sua categoria e gerenciados através de um avançado sistema de gerenciamento de pacotes (o dpkg) facilitando a instalação e atualização de pacotes. Possui tanto ferramentas para administração de redes e servidores quanto para desktops, estações multimídia, jogos, desenvolvimento, web, etc.
A atualização da distribuição ou de pacotes individuais pode ser feita facilmente através de 2 comandos, não requerendo adquirir um novo CD para usar a última versão da distribuição. É a única distribuição não comercial onde todos podem contribuir com seu conhecimento para o seu desenvolvimento. Para gerenciar os voluntários, conta com centenas de listas de discussão envolvendo determinados desenvolvedores das mais diversas partes do mundo.
São feitos extensivos testes antes do lançamento de cada versão para atingir um alto grau de confiabilidade. As falhas encontradas nos pacotes podem ser relatados através de um sistema de tratamento de falhas que encaminha a falha encontrada diretamente ao responsável para avaliação e correção. Qualquer um pode receber a lista de falhas ou sugestões sobre a distribuição cadastrando-se em uma das lista de discussão que tratam especificamente da solução de falhas encontradas na distribuição (disponível na página principal da distribuição).
Os pacotes podem ser instalados através de Tarefas contendo seleções de pacotes de acordo com a utilização do computador (servidor Web, desenvolvimento, TeX, jogos, desktop, etc.), Perfis contendo seleções de pacotes de acordo com o tipo de usuário (programador, operador, etc.), ou através de uma seleção individual de pacotes, garantindo que somente os pacotes selecionados serão instalados fazendo uma instalação enxuta.
Existe um time de desenvolvedores com a tarefa específica de monitorar atualizações de segurança em serviços (apache, sendmail, e todos os outros 8000 pacotes)que possam comprometer o servidor, deixando-o vulnerável a ataques. Assim que uma falha é descoberta, é enviado uma alerta (DSA - Debian Security Alert) e disponibilizada uma atualização para correção das diversas versões da Debian. Isto é geralmente feito em menos de 48 horas desde a descoberta da falha até a divulgação da correção. Como quase todas as falhas são descobertas nos programas, este método também pode ser usado por administradores de outras distribuições para manterem seu sistema seguro e atualizado.
O suporte ao usuário e desenvolvimento da distribuição são feitos através de listas de discussões e canais IRC. Existem uma lista de consultores habilitados a dar suporte e assistência a sistemas Debian ao redor do mundo na área consultores do site principal da distribuição.
http://www.slackware.com/ - Distribuição desenvolvida por Patrick Volkerding, desenvolvida para alcançar facilidade de uso e estabilidade como prioridades principais. Foi a primeira distribuição a ser lançada no mundo e costuma trazer o que há de mais novo enquanto mantém uma certa tradição, provendo simplicidade, facilidade de uso e com isso flexibilidade e poder.
Desde a primeira versão lançada em Abril de 1993, o Projeto Slackware Linux tem buscado produzir a distribuição Linux mais UNIX-like, ou seja, mais parecida com UNIX. O Slackware segue os padrões Linux como o Linux File System Standard, que é um padrão de organização de diretórios e arquivos para as distribuições.
Enquanto as pessoas diziam que a Red Hat era a melhor distribuição para o usuário iniciante, o Slackware é o melhor para o usuário mais "velho", ou seja programadores, administradores, etc.
http://www.suse.com/ - Distribuição comercial Alemã com a coordenação sendo feita através dos processos administrativos dos desenvolvedores e de seu braço norte-americano. O foco da Suse é o usuário com conhecimento técnico no Linux (programador, administrador de rede, etc.) e não o usuário iniciante no Linux (até a versão 6.2).
A distribuição possui suporte ao idioma e teclado Português, mas não inclui (até a versão 6.2) a documentação em Português. Eis a lista de idiomas suportados pela distribuição: English, Deutsch, Français, Italiano, Espanholñ, Português, Português Brasileiro, Polski, Cesky, Romanian, Slovensky, Indonésia.
Possui suporte as arquiteturas Intel x86 e Alpha. Sua instalação pode ser feita via CD-ROM ou CD-DVD (é a primeira distribuição com instalação através de DVD).
Uma média de 1500 programas acompanham a versão 6.3 distribuídos em 6 CD-ROMs. O sistema de gerenciamento de pacotes é o RPM padronizado. A seleção de pacotes durante a instalação pode ser feita através da seleção do perfil de máquina (developer, estação kde, gráficos, estação gnome, servidor de rede, etc.) ou através da seleção individual de pacotes.
A atualização da distribuição pode ser feita através do CD-ROM de uma nova versão ou baixando pacotes de ftp://ftp.suse.com/. Usuários registrados ganham direito a suporte de instalação via e-mail. A base de dados de suporte também é excelente e está disponível na web para qualquer usuário independente de registro.
http://www.redhat.com/ - Distribuição comercial suportada pela Red Hat e voltada a servidores de grandes e medias empresas. Também conta com uma certificação chamada RHCE específica desta distro.
Ela não está disponível para download, apenas vendida a custos a partir de 179 dólares (a versão workstation) até 1499 dólares (advanced server).
Fedora
http://fedora.redhat.com/ - O Fedora Linux é a distribuição de desenvolvimento aberto patrocinada pela RedHat e pela comunidade, originada em 2002 e baseada em versão da antiga linha de produtos RedHat Linux, a distribuição mais utilizada do mundo. Esta distribuição não é suportada pela Red Hat como distribuição oficial (ela suporta apenas a linha Red Hat Enterprise Linux), devendo obter suporte através da comunidade ou outros meios.
A distribuição Fedora dá prioridade ao uso do computador como estação de trabalho. Além de contar com uma ampla gama de ferramentas de escritório possui funções de servidor e aplicativos para produtividade e desenvolvimento de softwares. Considerado um dos sistemas mais fáceis de instalar e utilizar, inclui tradução para português do Brasil e suporte às plataformas Intel e 64 bits.
Por basear-se no RedHat. o Fedora conta com um o up2date, um software para manter o sistema atualizado e utiliza pacotes de programas no formato RPM, um dos mais comuns. Por outro lado, não possui suporte a MP3, Video Players ou NTFS (Discos do Windows) em virtude de problemas legais sendo necessário o download de alguns plugins para a utilização destas funções.
O Fedora não é distribuído oficialmente através de mídias ou CDs, se você quiser obtê-lo terá de procurar distribuidores independentes ou fazer o download dos 4 CDs através do site oficial.
http://www.mandriva.com/ - Uma distribuição surgida a partir da fusão da francesa Mandrake e da brasileira Conectiva, que se instala praticamente sozinha. Boa auto-detecção de periféricos, inclusive web-cams.
http://guiadohardware.net/kurumin/index.php/ - Uma distribuição baseada em Debian que roda diretamente a partir do CD, sendo ideal para quem deseja testar uma distribuição Linux. Caso gosto, pode ser instalada diretamente no disco rígido. Distribuída a partir do CD, é maravilhosa e suporta boa quantidade de hardwares disponíveis. A versão instalada possui suporte a maioria dos winmodens mais encontrados no Brasil.
(tradução do texto Linux e o Sistema GNU de Richard Stallman obtido no site do CIPSGA: http://www.cipsga.org.br/). O projeto GNU começou em 1983 com o objetivo de desenvolver um sistema operacional Unix-like totalmente livre. Livre se refere à liberdade, e não ao preço; significa que você está livre para executar, distribuir, estudar, mudar e melhorar o software.
Um sistema Unix-like consiste de muitos programas diferentes. Nós achamos alguns componentes já disponíveis como softwares livres—por exemplo, X Window e TeX. Obtemos outros componentes ajudando a convencer seus desenvolvedores a tornarem eles livres—por exemplo, o Berkeley network utilities. Outros componentes nós escrevemos especificamente para o GNU—por exemplo, GNU Emacs, o compilador GNU C, o GNU C library, Bash e Ghostscript. Os componentes desta última categoria são "software GNU". O sistema GNU consiste de todas as três categorias reunidas.
O projeto GNU não é somente desenvolvimento e distribuição de alguns softwares livres úteis. O coração do projeto GNU é uma ideia: que software deve ser livre, e que a liberdade do usuário vale a pena ser defendida. Se as pessoas têm liberdade mas não a apreciam conscientemente, não irão mantê-la por muito tempo. Se queremos que a liberdade dure, precisamos chamar a atenção das pessoas para a liberdade que elas têm em programas livres.
O método do projeto GNU é que programas livres e a ideia da liberdade dos usuários ajudam-se mutuamente. Nós desenvolvemos software GNU, e conforme as pessoas encontrem programas GNU ou o sistema GNU e comecem a usá-los, elas também pensam sobre a filosofia GNU. O software mostra que a ideia funciona na prática. Algumas destas pessoas acabam concordando com a ideia, e então escrevem mais programas livres. Então, o software carrega a ideia, dissemina a ideia e cresce da ideia.
Em 1992, nós encontramos ou criamos todos os componentes principais do sistema exceto o kernel, que nós estávamos escrevendo. (Este kernel consiste do microkernel Mach mais o GNU HURD. Atualmente ele está funcionando, mas não está preparado para os usuários. Uma versão alfa deverá estar pronta em breve.)
Então o kernel do Linux tornou-se disponível. Linux é um kernel livre escrito por Linus Torvalds compatível com o Unix. Ele não foi escrito para o projeto GNU, mas o Linux e o quase completo sistema GNU fizeram uma combinação útil. Esta combinação disponibilizou todos os principais componentes de um sistema operacional compatível com o Unix, e, com algum trabalho, as pessoas o tornaram um sistema funcional. Foi um sistema GNU variante, baseado no kernel do Linux.
Ironicamente, a popularidade destes sistemas desmerece nosso método de comunicar a ideia GNU para as pessoas que usam GNU. Estes sistemas são praticamente iguais ao sistema GNU—a principal diferença é a escolha do kernel. Porém as pessoas normalmente os chamam de "sistemas Linux (Linux systems)". A primeira impressão que se tem é a de que um "sistema Linux" soa como algo completamente diferente de "sistema GNU", e é isto que a maioria dos usuários pensam que acontece.
A maioria das introduções para o "sistema Linux" reconhece o papel desempenhado pelos componentes de software GNU. Mas elas não dizem que o sistema como um todo é uma variante do sistema GNU que o projeto GNU vem compondo por uma década. Elas não dizem que o objetivo de um sistema Unix-like livre como este veio do projeto GNU. Daí a maioria dos usuários não saber estas coisas.
Como os seres humanos tendem a corrigir as suas primeiras impressões menos do que as informações subsequentes tentam dizer-lhes, estes usuários que depois aprendem sobre a relação entre estes sistemas e o projeto GNU ainda geralmente o subestima.
Isto faz com que muitos usuários se identifiquem como uma comunidade separada de "usuários de Linux", distinta da comunidade de usuários GNU. Eles usam todos os softwares GNU; de fato, eles usam quase todo o sistema GNU; mas eles não pensam neles como usuários GNU, e frequentemente não pensam que a filosofia GNU está relacionada a eles.
Isto leva a outros problemas também—mesmo dificultando cooperação com a manutenção de programas. Normalmente quando usuários mudam um programa GNU para fazer ele funcionar melhor em um sistema específico, eles mandam a mudança para o mantenedor do programa; então eles trabalham com o mantenedor explicando a mudança, perguntando por ela, e às vezes re-escrevendo-a para manter a coerência e mantenebilidade do pacote, para ter o patch instalado.
Mas as pessoas que pensam nelas como "usuários Linux" tendem a lançar uma versão "Linux-only" do programa GNU, e consideram o trabalho terminado. Nós queremos cada e todos os programas GNU que funcionem "out of the box" em sistemas baseados em Linux; mas se os usuários não ajudarem, este objetivo se torna muito mais difícil de atingir.
Como deve o projeto GNU lidar com este problema? O que nós devemos fazer agora para disseminar a ideia de que a liberdade para os usuários de computador é importante?
Nós devemos continuar a falar sobre a liberdade de compartilhar e modificar software—e ensinar outros usuários o valor destas liberdades. Se nós nos beneficiamos por ter um sistema operacional livre, faz sentido para nós pensar em preservar estas liberdades por um longo tempo. Se nós nos beneficiamos por ter uma variedade de software livres, faz sentido pensar sobre encorajar outras pessoas a escrever mais software livre, em vez de software proprietário.
Nós não devemos aceitar a ideia de duas comunidades separadas para GNU e Linux. Ao contrário, devemos disseminar o entendimento de que "sistemas Linux" são variantes do sistema GNU, e que os usuários destes sistemas são tanto usuários GNU como usuários Linux (usuários do kernel do Linux). Usuários que têm conhecimento disto irão naturalmente dar uma olhada na filosofia GNU que fez estes sistemas existirem.
Eu escrevi este artigo como um meio de fazer isto. Outra maneira é usar os termos "sistema GNU baseado em Linux (Linux-based GNU system)" ou "sistema GNU/Linux (GNU/Linux system)", em vez de "sistema Linux", quando você escreve sobre ou menciona este sistema.
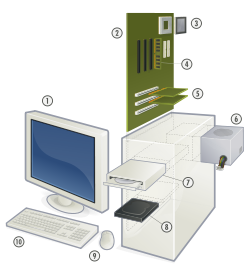
É uma máquina eletrônica que processa e armazena os dados e pode executar diversos programas para realizar uma série de tarefas e assim atender a necessidade do seu utilizador. O computador não é uma máquina inteligente, ele apenas executa as instruções dos programas que foram escritos pelo programador.
Esta página é um esboço de informática. Ampliando-a você ajudará a melhorar o Wikilivros.
Esta explica para que serve cada botão do painel do computador e monitor de vídeo. Se você já sabe para que cada um serve, recomendo pular esta parte, é o BE-A-BA. :-)
Todo computador possuem funções que são usados em outros tipos e modelos. Você pode ter um modelo de computador e um amigo seu outro tipo e mesmo tendo aparência diferente, terão as mesmas funções.
Quanto ao tipo, o gabinete pode ser Desktop, Mini-torre e Torre.
Desktop
É usado na posição Horizontal (como o vídeo cassete). Sua característica é que ocupa pouco espaço em uma mesa, pois pode ser colocado sob o monitor. A desvantagem é que normalmente possui pouco espaço para a colocação de novas placas e periféricos. Outra desvantagem é a dificuldade na manutenção deste tipo de equipamento (hardware).
Míni-Torre
É usado na posição Vertical (torre). É o modelo mais usado. Sua característica é o espaço interno para expansão e manipulação de periféricos. A desvantagem é o espaço ocupado em sua mesa :-).
Torre
Possui as mesmas características do Míni-torre, mas tem uma altura maior e mais espaço para colocação de novos periféricos. Muito usado em servidores de rede e placas que requerem uma
O painel frontal do computador tem os botões que usamos para ligar, desligar, e acompanhar o funcionamento do computador. Abaixo o significado de cada um:
Botão POWER
Liga/Desliga o computador.
Botão TURBO
Se ligado, coloca a placa mãe em operação na velocidade máxima (o padrão). Desligado, faz o computador funcionar mais lentamente (depende de cada placa mãe). Deixe sempre o TURBO ligado para seu computador trabalhar na velocidade máxima de processamento.
Botão RESET
Reinicia o computador. Quando o computador é reiniciado, uma nova partida é feita (é como se nós ligássemos novamente o computador). Este botão é um dos mais usados por usuários Windows dentre os botões localizados no painel do microcomputador. No GNU/Linux é raramente usado (com menos frequência que a tecla Scroll Lock.
É recomendado se pressionar as teclas Ctrl + Alt + Del para reiniciar o computador e o botão RESET somente em último caso, pois o Ctrl + Alt + Del avisa ao Linux que o usuário pediu para o sistema ser reiniciado assim ele poderá salvar os arquivos, fechar programas e tomar outras providências antes de resetar o computador.
KEYLOCK
Permite ligar/desligar o teclado. É acionado por uma chave e somente na posição "Cadeado Aberto" permite a pessoa usar o teclado (usar o computador). Alguns computadores não possuem Key Lock
LED POWER
Led (normalmente verde) no painel do computador que quando aceso, indica que o computador está ligado. O led é um diodo emissor de luz (light emission diode) que emite luz fria.
LED TURBO
Led (normalmente amarelo) no painel do computador. Quando esta aceso, indica que a chave turbo está ligada e o computador funcionando a toda velocidade.
Raramente as placas mãe Pentium e acima usam a chave turbo. Mesmo que exista no gabinete do micro, encontra-se desligada.
LED HDD
Led (normalmente vermelho) no painel do computador. Acende quando o disco rígido (ou discos) do computador esta sendo usado.
Também acende quando uma unidade de CD-ROM está conectada na placa mãe e for usado.
Capacidade de mostrar 4 cores simultâneas em modo gráfico. Uma das primeiras usadas em computadores PCs, com baixa qualidade de imagem, poucos programas funcionavam em telas CGA, quase todos em modo texto. Ficou muito conhecida como "tela verde" embora existem modelos CGA preto e branco.
Hércules
Semelhante ao CGA. Pode mostrar 2 cores simultâneas em modo gráfico. A diferença é que apresenta uma melhor qualidade para a exibição de gráficos mas por outro lado, uma grande variedade de programas para monitores CGA não funcionam com monitores Hércules por causa de seu modo de vídeo. Também é conhecido por sua imagem amarela.
Dependendo da placa de vídeo, você pode configurar um monitor Hércules monocromático para trabalhar como CGA.
EGA - Enhanced Graphics Adapter
Capacidade de mostrar 16 cores simultâneas em modo gráfico. Razoável melhora da qualidade gráfica, mais programas rodavam neste tipo de tela. Ficou mais conhecida após o lançamento dos computadores 286, mas no Brasil ficou pouco conhecida pois logo em seguida foi lançada o padrão VGA.
VGA - Video Graphics Array
Capacidade de mostrar 256 cores simultâneas. Boa qualidade gráfica, este modelo se mostrava capaz de rodar tanto programas texto como gráficos com ótima qualidade de imagem. Se tornou o padrão mínimo para rodar programas em modo gráfico.
É a placa principal do sistema onde estão localizados o Processador, Memória RAM, Memória Cache, BIOS, CMOS, RTC, etc. A placa mãe possui encaixes onde são inseridas placas de extensão (para aumentar as funções do computador). Estes encaixes são chamados de "SLOTS".
Abaixo a descrição de alguns tipos de componentes eletrônicos que estão presentes na placa mãe. Não se preocupe se não entender o que eles significam agora:
RAM - Memória de Acesso Aleatório (Randomic Access Memory). É uma memória de armazenamento temporário dos programas e depende de uma fonte de energia para o armazenamento dos programas. É uma memória eletrônica muito rápida assim os programas de computador são executados nesta memória. Seu tamanho é medido em Kilobytes ou Megabytes.
Os chips de memória RAM podem ser independentes (usando circuitos integrados encaixados em soquetes na placa mãe) ou agrupados placas de 30 pinos, 72 pinos e 168 pinos.
Quanto maior o tamanho da memória, mais espaço o programa terá ao ser executado. O tamanho de memória RAM pedido por cada programa varia, o GNU/Linux precisa de no mínimo 2 MB de memória RAM para ser executado pelo processador.
PROCESSADOR - É a parte do computador responsável pelo processamentos das instruções matemáticas/lógicas e programas carregados na memória RAM.
CO-PROCESSADOR - Ajuda o Processador principal a processar as instruções matemáticas. É normalmente embutido no Processador principal em computadores a partir do 486 DX2-66.
CACHE - Memória de Armazenamento Auxiliar do Processador. Possui alta velocidade de funcionamento, normalmente a mesma que o processador. Serve para aumentar o desempenho de processamento. A memória Cache pode ser embutida na placa mãe ou encaixada externamente através de módulos L2.
BIOS - É a memória ROM que contém as instruções básicas para a inicialização do computador, reconhecimento e ativação dos periféricos conectados a placa mãe. As BIOS mais modernas (a partir do 286) também trazem um programa que é usado para configurar o computador modificando os valores localizados na CMOS.
As placas controladoras SCSI possuem sua própria BIOS que identificam automaticamente os periféricos conectados a ela. Os seguintes tipos de chips podem ser usados para gravar a BIOS:
ROM - Memória Somente para Leitura (Read Only Memory). Somente pode ser lida. É programada de fábrica através de programação elétrica ou química.
PROM - Memória Somente para Leitura Programável (Programable Read Only Memory) idêntica a ROM mas que pode ser programada apenas uma vez por máquinas "Programadoras PROM". É também chamada de MASK ROM.
EPROM - Memória semelhante a PROM, mas seu conteúdo pode ser apagado através raios ultravioleta.
EEPROM - Memória semelhante a PROM, mas seu conteúdo pode ser apagado e regravado. Também é chamada de Flash.
CMOS - É uma memória temporária alimentada por uma Bateria onde são lidas/armazenadas as configurações do computador feitas pelo programa residente na BIOS.
A memória é a parte do computador que permitem o armazenamento de dados. A memória é dividida em dois tipos: Principal e Auxiliar. Normalmente quando alguém fala em "memória de computador" está se referindo a memória "Principal". Veja abaixo as descrições de Memória Principal e Auxiliar.
É um tipo de memória eletrônica que depende de uma fonte de energia para manter os dados armazenados e perde os dados quando a fonte de energia é desligada. A memória RAM do computador (Randomic Access Memory - Memória de Acesso aleatório) é o principal exemplo de memória de armazenamento Principal.
Os dados são armazenados em circuitos integrados ("chips") e enquanto você está usando seu computador, a RAM armazena e executa seus programas. Os programas são executados na memória RAM porque a memória eletrônica é muito rápida. As memórias EDO, DIMM, DDR, DDR2, DDR3 são exemplos de memória RAM.
Se desligarmos o computador ou ocorrer uma queda de energia, você perderá os programas que estiverem em execução ou o trabalho que estiver fazendo. Por esse motivo é necessário o uso de uma memória auxiliar (veja Memória Auxiliar).
São dispositivos que não dependem de uma fonte de energia para manter os dados armazenados, os dados não são perdidos quando a fonte de energia é desligada. As Memórias Auxiliares são muito mais lentas que as Memórias Principais porque utilizam mecanismos mecânicos e elétricos (motores e eletroímãs) para funcionar e fazer a leitura/gravação dos dados.
Um exemplo de dispositivos de armazenamento auxiliar são os pen drives, disquetes, cartões SD, discos rígidos, unidades de fita, Zip Drives, CD-ROM, etc.
A Memória Auxiliar resolve o problema da perda de dados causado pela Memória Principal quando o computador é desligado, desta forma podemos ler nossos arquivos e programas da memória Auxiliar e copia-los para a Memória Principal (memória RAM) para que possam ser novamente usados.
Um exemplo simples é de quando estiver editando um texto e precisar salva-lo, o que você faz é simplesmente salvar os dados da memória RAM que estão sendo editados para o disco rígido, desta forma você estará guardando seu documento na Memória Auxiliar.
Este tipo de memória é mais lento que a memória principal, é por este motivo que os programas somente são carregados e executados na Memória Principal.
Os discos são memórias de armazenamento Auxiliares. Entre os vários tipos de discos existentes, posso citar os Flexíveis, Rígidos e CDs. Veja as explicações sobre cada um deles abaixo.
São discos usados para armazenar e transportar pequenas quantidades de dados. Este tipo de disco é normalmente encontrado no tamanho 3 1/2 (1.44MB) polegadas e 5 1/4 polegadas (360Kb ou 1.2MB). Hoje os discos de 3 1/2 são os mais utilizados por terem uma melhor proteção por causa de sua capa plástica rígida, maior capacidade e o menor tamanho o que facilita seu transporte.
Os disquetes são inseridos em um compartimento chamado de "Unidade de Disquetes" ou "Drive" que faz a leitura/gravação do disquete.
Sua característica é a baixa capacidade de armazenamento e baixa velocidade no acesso aos dados mas podem ser usados para transportar os dados de um computador a outro com grande facilidade. Os disquetes de computador comuns são discos flexíveis.
É um disco localizado dentro do computador. É fabricado com discos de metal recompostos por material magnético onde os dados são gravados através de cabeças e revestido externamente por uma proteção metálica que é preso ao gabinete do computador por parafusos. Também é chamado de HD (Hard Disk) ou Winchester. É nele que normalmente gravamos e executamos nossos programas mais usados.
A característica deste tipo de disco é a alta capacidade de armazenamento de dados e alta velocidade no acesso aos dados.
É um tipo de disco que permite o armazenamento de dados através de um compact disc e os dados são lidos através de uma lente ótica. A Unidade de CD é localizada no gabinete do computador e pode ler CDs de músicas, arquivos, interativos, etc. Existem diversos tipos de CDs no mercado, entre eles:
CD-R - CD gravável, pode ser gravado apenas uma vez. Possui sua capacidade de armazenamento entre 600MB e 740MB dependendo do formato de gravação usado. Usa um formato lido por todas as unidades de CD-ROM disponíveis no mercado.
CD-RW - CD regravável, pode ser gravado várias vezes, ter seus arquivos apagados, etc. Seu uso é semelhante ao de um disquete de alta capacidade. Possui capacidade de armazenamento de normalmente 640MB mas isto depende do fabricante. Usa um formato que é lido apenas por unidades leitoras e gravadoras multi seção.
DVD-ROM - CD ROM de alta capacidade de armazenamento. Pode armazenar mais de 17GB de arquivos ou programas. É um tipo de CD muito novo no mercado e ainda em desenvolvimento. É lido somente por unidades próprias para este tipo de disco.
Pen Drive ou Memória USB Flash Drive é um dispositivo de armazenamento de dados que inclui memória flash (EEPROM) e possui uma interface USB (tipo A) integrada, permitindo uma conexão a uma porta USB de um computador. A velocidade de transferência de dados pode variar dependendo do tipo de entrada. São mais compactos, rápidos, têm grande capacidade de armazenamento e resistência devido à ausência de peças móveis.
Unidade de estado sólido (em inglês: solid-state drive, ou SSD) é um tipo de dispositivo, sem partes móveis, para armazenamento não volátil de dados digitais. São, tipicamente, construídos em torno de um circuito integrado semicondutor[1], responsável por armazenamento, diferindo de sistemas magnéticos (como os HDDs e fitas LTO) ou óticos (discos como CDs e DVDs). Os dispositivos utilizam memória flash (tecnologia semelhante as utilizadas em cartões de memória e pendrives).
O tempo de acesso à memória é muito menor e pela eliminação de partes móveis eletromecânicas, reduz as vibrações, tornando-os completamente silenciosos outra vantagem é o consumo reduzido de energia.
Abaixo uma lista de cuidados básicos para garantir uma melhor conservação e funcionamento de seu computador e disquetes.
Não deixe seu computador em locais expostos a umidade ou sol. O mesmo se aplica a discos magnéticos, como os disquetes.
Limpe o Gabinete e o Monitor com um pano levemente umedecido em água com sabão neutro ou solução de limpeza apropriada para micros. Não use Álcool, querosene, acetona ou qualquer outro tipo de produto abrasivo. O uso de um destes podem estragar o gabinete de seu computador e se um destes produtos atingir a parte interna pode causar problemas nas placas ou até um incêndio!
Não retire o Pino central da tomada do computador, ele não veio sobrando e tem utilidade! Este pino é ligado a carcaça do computador (chassis) e deve ser ligado ao terra de sua rede elétrica. As descargas elétricas vindas da fonte e componentes do micro são feitas no chassis e se este pino for retirado você poderá tomar choques ao tocar em alguma parte metálica do micro e queimar componentes sensíveis como o disco rígido, placa mãe, etc.
Se estiver em dúvida consulte um eletricista.
Não instale seu computador muito perto de campos magnéticos com televisores, aparelhos de som, motores, etc. Estes aparelhos geram ruídos elétricos e/ou magnéticos que podem prejudicar o bom funcionamento de seu micro. OBS: As caixas de som de kits multimídia possuem os ímãs revestidos de metais em seus auto-falantes para não causar nenhuma interferência ao computador.
Não use a bandeja da unidade de CD-ROM como porta copos!
Não coloque objetos dentro da unidade de disquetes.
Antes de desligar seu computador, utilize o comando : shutdown -h now para finalizar os programas, salvar os dados, desmontar os sistemas de arquivos em seu sistema GNU/Linux. Para detalhes veja Desligando o computador
Não deixe o computador próximo a regiões com fumaça, a fumaça pode prejudicar o disco rigido.
Entrada - Permite a comunicação do usuário com o computador. São dispositivos que enviam dados ao computador para processamento. Exemplos: Teclado, mouse, caneta ótica, scanner.
O dispositivo de entrada padrão (stdin) em sistemas GNU/Linux é o teclado.
Saída - Permite a comunicação do computador com o usuário. São dispositivos que permitem o usuário visualizar o resultado do processamento enviado ao computador. Exemplos: Monitor, Impressora, Plotter.
O dispositivo de saída padrão (stdout) em sistemas GNU/Linux é o Monitor.
Para ligar o computador pressione o botão POWER ou I/O localizado em seu painel frontal do micro.
Imediatamente entrará em funcionamento um programa residente na memória ROM (Read Only Memory - memória somente para leitura) da placa mãe que fará os testes iniciais para verificar se os principais dispositivos estão funcionando em seu computador (memória RAM, discos, processador, portas de impressora, memória cache, etc).
Quando o ROM termina os testes básicos, ele inicia a procura do setor de boot nos discos do computador que será carregado na memória RAM do computador. Após carregar o setor de boot, o sistema operacional será iniciado (veja Sistema Operacional). O setor de boot contém a porção principal usada para iniciar o sistema operacional.
No GNU/Linux, o setor de boot normalmente é criado por um gerenciador de inicialização (um programa que permite escolher qual sistema operacional será iniciado). Deste modo podemos usar mais de um sistema operacional no mesmo computador (como o DOS e Linux). O gerenciador de inicialização mais usado em sistemas GNU/Linux na plataforma Intel X86 é o LILO.
Caso o ROM não encontre o sistema operacional em nenhum dos discos, ele pedirá que seja inserido um disquete contendo o Sistema Operacional para partida.
Para desligar o computador primeiro digite (como root): shutdown -h now, halt ou poweroff, o GNU/Linux finalizará os programas e gravará os dados em seu disco rígido, quando for mostrada a mensagem "power down", pressione o botão POWER em seu gabinete para desligar a alimentação de energia do computador.
NUNCA desligue diretamente o computador sem usar o comando shutdown, halt ou poweroff, pois podem ocorrer perda de dados ou falhas no sistema de arquivos de seu disco rígido devido a programas abertos e dados ainda não gravados no disco.
Salve seus trabalhos para não correr o risco de perde-los durante o desligamento do computador.
Reiniciar quer dizer iniciar novamente o sistema. Não é recomendável desligar e ligar constantemente o computador pelo botão ON/OFF, por este motivo existem recursos para reiniciar o sistema sem desligar o computador. No GNU/Linux você pode usar o comando reboot, shutdown -r now e também pressionar simultaneamente as teclas Ctrl+Alt+Del para reiniciar de uma forma segura.
Observações:
Salve seus trabalhos para não correr o risco de perdê-los durante a reinicialização do sistema.
O botão reset do painel frontal do computador também reinicia o computador, mas de uma maneira mais forte, pois está ligado diretamente aos circuitos da placa mãe e o sistema será reiniciado imediatamente, não tendo nenhuma chance de finalizar corretamente os programas, gravar os dados da memória no disco e desmontar os sistemas de arquivos. O uso indevido da tecla reset pode causar corrompimentos em seus arquivos e perdas.
Prefira o método de reinicialização explicado acima e use o botão reset somente em último caso.
É onde gravamos nossos dados. Um arquivo pode conter um texto feito por nós, uma música, programa, planilha, etc.
Cada arquivo deve ser identificado por um nome, assim ele pode ser encontrado facilmente quando se desejar usá-lo. Se estiver fazendo um trabalho de história, nada melhor que salvá-lo com o nome história. Um arquivo pode ser binário ou texto (para detalhes veja Arquivo texto e binário).
O GNU/Linux é Case Sensitive ou seja, ele diferencia letras maiúsculas e minúsculas nos arquivos. O arquivo história é completamente diferente de História. Esta regra também é válido para os comandos e diretórios.
O nome do arquivo pode ser qualquer string, inclusive com espaços em branco, acentos ou outros caracteres não-alfanuméricos. Não é recomendável, porém, usar espaços nem acentos ou caracteres especiais: espaços e caracteres especiais dificultam na hora de escrever scripts, e acentos dificultam a portabilidade do arquivo para outros sistemas e para gravar em CDs, DVDs ou pen-drives. Prefira, sempre que possível, usar letras minúsculas, dígitos (0-9), underscore e o sinal de menos (-) para identificar seus arquivos, pois quase todos os comandos do sistema estão em minúsculas.
Um arquivo oculto no GNU/Linux é identificado por um "." no início do nome (por exemplo, .bashrc). Arquivos ocultos não aparecem em listagens normais de diretórios, deve ser usado o comando ls -a para também listar arquivos ocultos.
A extensão serve para identificar o tipo do arquivo. A extensão são as letras após um "." no nome de um arquivo, explicando melhor:
relatório.txt - O .txt indica que o conteúdo é um arquivo texto.
script.sh - Arquivo de Script (interpretado por /bin/sh).
system.log - Registro de algum programa no sistema.
arquivo.gz - Arquivo compactado pelo utilitário gzip.
index.html - Página de Internet (formato Hypertexto).
A extensão de um arquivo também ajuda a saber o que precisamos fazer para abri-lo. Por exemplo, o arquivo relatório.txt é um texto simples e podemos ver seu conteúdo através do comando cat, já o arquivo index.html contém uma página de Internet e precisaremos de um navegador para poder visualizá-lo (como o lynx, Firefox ou o Konqueror).
A extensão (na maioria dos casos) não é requerida pelo sistema operacional GNU/Linux, mas é conveniente o seu uso para determinarmos facilmente o tipo de arquivo e que programa precisaremos usar para abri-lo.
A unidade de medida padrão nos computadores é o bit. A um conjunto de 8 bits nós chamamos de byte. Cada arquivo/diretório possui um tamanho, que indica o espaço que ele ocupa no disco e isto é medido em bytes. O byte representa uma letra. Assim, se você criar um arquivo vazio e escrever o nome Linux e salvar o arquivo, este terá o tamanho de 5 bytes. Espaços em branco e novas linhas também ocupam bytes.
Além do byte existem as medidas Kbytes, Mbytes, Gbytes. Os prefixos K (quilo), M (mega), G (giga), T (tera) etc. vêm da matemática. O "K" significa multiplicar por 103, o "M" por 106, e assim por diante. Esta letras servem para facilitar a leitura em arquivos de grande tamanho. Um arquivo de 1K é a mesma coisa de um arquivo de 1024 bytes. Uma forma que pode inicialmente lhe ajudar a lembrar: K vem de Kilo que é igual a 1000 - 1Kilo é igual a 1000 gramas certo?.
Da mesma forma 1Mb (ou 1M) é igual a um arquivo de 1024K ou 1.048.576 bytes
1Gb (ou 1G) é igual a um arquivo de 1024Mb ou 1048576Kb ou 1.073.741.824 bytes (1 Gb é igual a 1.073.741.824 bytes, são muitos números!). Deu pra notar que é mais fácil escrever e entender como 1Gb do que 1.073.741.824 bytes :-)
A lista completa em ordem progressiva das unidades de medida é a seguinte:
Quanto ao tipo, um arquivo pode ser de texto ou binário:
texto
Seu conteúdo é compreendido pelas pessoas. Um arquivo texto pode ser uma carta, um script, um programa de computador escrito pelo programador, arquivo de configuração, etc.
binário
Seu conteúdo somente pode ser entendido por computadores. Contém caracteres incompreensíveis para pessoas normais. Um arquivo binário é gerado através de um arquivo de programa (formato texto) através de um processo chamado de compilação. Compilação é basicamente a conversão de um programa em linguagem humana para a linguagem de máquina.
Diretório é o local utilizado para armazenar conjuntos de arquivos para melhor organização e localização. O diretório, como o arquivo, também é "Case Sensitive" (diretório /teste é completamente diferente do diretório /Teste).
Não podem existir dois arquivos com o mesmo nome em um diretório, ou um sub-diretório com um mesmo nome de um arquivo em um mesmo diretório.
Um diretório, nos sistemas Linux/UNIX, é especificado por uma "/" e não uma "\" como é feito no DOS. Para detalhes sobre como criar um diretório, veja o comando mkdir (mkdir, Seção 8.4).
Este é o diretório principal do sistema. Dentro dele estão todos os diretórios do sistema. O diretório Raiz é representado por uma "/", assim se você digitar o comando cd / você estará acessando este diretório.
Nele estão localizados outros diretórios como o /bin, /sbin, /usr, /usr/local, /mnt, /tmp, /var, /home, etc. Estes são chamados de sub-diretórios pois estão dentro do diretório "/". A estrutura de diretórios e sub-diretórios pode ser identificada da seguinte maneira:
/
/bin
/sbin
/usr
/usr/local
/mnt
/tmp
/var
/home
A estrutura de diretórios também é chamada de Árvore de Diretórios porque é parecida com uma árvore de cabeça para baixo. Cada diretório do sistema tem seus respectivos arquivos que são armazenados conforme regras definidas pela FHS (FileSystem Hierarchy Standard - Hierarquia Padrão do Sistema de Arquivos) versão 2.0, definindo que tipo de arquivo deve ser armazenado em cada diretório.
É o diretório em que nos encontramos no momento. Você pode digitar pwd (veja pwd, Seção 8.3) para verificar qual é seu diretório atual.
O diretório atual também é identificado por um "." (ponto). O comando ls . pode ser usado para listar seus arquivos (é claro que isto é desnecessário porque se não digitar nenhum diretório, o comando ls listará o conteúdo do diretório atual).
Também chamado de diretório de usuário. Em sistemas GNU/Linux, cada usuário (inclusive o root) possui seu próprio diretório onde poderá armazenar seus programas e arquivos pessoais.
Este diretório está localizado em /home/[login], neste caso se o seu login for "joao" o seu diretório home será /home/joao. O diretório home também é identificado por um ~(til), você pode digitar tanto o comando ls /home/joao como ls ~ para listar os arquivos de seu diretório home.
O diretório home do usuário root (na maioria das distribuições GNU/Linux) está localizado em /root.
Dependendo de sua configuração e do número de usuários em seu sistema, o diretório de usuário pode ter a seguinte forma: /home/[1letra_do_nome]/[login], neste caso se o seu login for "joao" o seu diretório home será /home/j/joao.
O diretório superior (Upper Directory) é identificado por .. (2 pontos).
Caso estiver no diretório /usr/local e quiser listar os arquivos do diretório /usr você pode digitar, ls .. Este recurso também pode ser usado para copiar, mover arquivos/diretórios, etc.
São os diretórios que teremos que percorrer até chegar no arquivo ou diretório que procuramos. Se desejar ver o arquivo /usr/doc/copyright/GPL você tem duas opções:
Mudar o diretório padrão para /usr/doc/copyright com o comando cd /usr/doc/copyright e usar o comando cat GPL
Usar o comando "cat" especificando o caminho completo na estrutura de diretórios e o nome de arquivo: cat /usr/doc/copyright/GPL.
As duas soluções acima permitem que você veja o arquivo GPL. A diferença entre as duas é a seguinte:
Na primeira, você muda o diretório padrão para /usr/doc/copyright (confira digitando pwd) e depois o comando cat GPL. Você pode ver os arquivos de /usr/doc/copyright com o comando "ls".
/usr/doc/copyright é o caminho de diretório que devemos percorrer para chegar até o arquivo GPL.
Na segunda, é digitado o caminho completo para o "cat" localizar o arquivo GPL: cat /usr/doc/copyright/GPL. Neste caso, você continuará no diretório padrão (confira digitando pwd). Digitando ls, os arquivos do diretório atual serão listados.
O caminho de diretórios é necessário para dizer ao sistema operacional onde encontrar um arquivo na "árvore" de diretórios.
Um exemplo de diretório é o seu diretório de usuário, todos seus arquivos essenciais devem ser colocadas neste diretório. Um diretório pode conter outro diretório, isto é útil quando temos muitos arquivos e queremos melhorar sua organização. Abaixo um exemplo de uma empresa que precisa controlar os arquivos de Pedidos que emite para as fábricas:
/pub/vendas - diretório principal de vendas /pub/vendas/mes01-99 - diretório contendo vendas do mês 01/1999 /pub/vendas/mes02-07 - diretório contendo vendas do mês 02/2007 /pub/vendas/mes01-08 - diretório contendo vendas do mês 01/2008
mes01-99, mes02-07, mes01-08 são diretórios usados para armazenar os arquivos de pedidos do mês e ano correspondente. Isto é essencial para a organização, pois se todos os pedidos fossem colocados diretamente no diretório vendas, seria muito difícil encontrar o arquivo do cliente "João" do mês 01/2007.
Você deve ter reparado que usei a palavra sub-diretório para mes01-99, mes02-07 e mes03-08, porque eles estão dentro do diretório vendas. Da mesma forma, vendas é um sub-diretório de pub.
O sistema GNU/Linux possui a seguinte estrutura básica de diretórios, organizados segundo o FHS (Filesystem Hierarchy Standard):
/bin
Contém arquivos programas do sistema que são usados com frequência pelos usuários.
/boot
Contém arquivos necessários para a inicialização do sistema.
/cdrom
Ponto de montagem da unidade de CD-ROM.
/media
Ponto de montagem de dispositivos diversos do sistema (rede, pen-drives, CD-ROM em distribuições mais novas).
/dev
Contém arquivos usados para acessar dispositivos (periféricos) existentes no computador.
/etc
Arquivos de configuração de seu computador local.
/floppy
Ponto de montagem de unidade de disquetes
/home
Diretórios contendo os arquivos dos usuários.
/lib
Bibliotecas compartilhadas pelos programas do sistema e módulos do kernel.
/lost+found
Local para a gravação de arquivos/diretórios recuperados pelo utilitário fsck.ext2. Cada partição possui seu próprio diretório lost+found.
/mnt
Ponto de montagem temporário.
/proc
Sistema de arquivos do kernel. Este diretório não existe em seu disco rígido, ele é colocado lá pelo kernel e usado por diversos programas que fazem sua leitura, verificam configurações do sistema ou modificam o funcionamento de dispositivos do sistema através da alteração em seus arquivos.
/root
Diretório do usuário root.
/sbin
Diretório de programas usados pelo superusuário (root) para administração e controle do funcionamento do sistema.
/tmp
Diretório para armazenamento de arquivos temporários criados por programas.
/usr
Contém maior parte de seus programas. Normalmente acessível somente como leitura.
/var
Contém maior parte dos arquivos que são gravados com frequência pelos programas do sistema, e-mails, spool de impressora, cache, etc.
No GNU/Linux, os arquivos e diretórios podem ter o tamanho de até 255 letras. Você pode identificá-lo com uma extensão (um conjunto de letras separadas do nome do arquivo por um ".").
Os programas executáveis do GNU/Linux, ao contrário dos programas de DOS e Windows, não são executados a partir de extensões .exe, .com ou .bat. O GNU/Linux (como todos os sistemas POSIX) usa a permissão de execução de arquivo para identificar se um arquivo pode ou não ser executado.
No exemplo anterior, nosso trabalho de história poderia ser identificado mais facilmente caso fosse gravado com o nome trabalho.text ou trabalho.txt. Também é permitido gravar o arquivo com o nome Trabalho de Historia.txt mas não é recomendado gravar nomes de arquivos e diretórios com espaços. Porque será necessário colocar o nome do arquivo entre "aspas" para acessá-lo (por exemplo, cat "Trabalho de Historia.txt"). Ao invés de usar espaços, considere capitalizar o arquivo (usar letras maiúsculas e minúsculas para identificá-lo, TrabalhodeHistoria.txt) ou usar o underscore (trabalho_de_historia.txt). Não é proibido usar acentos (trabalho_de_história.txt ou TrabalhodeHistória.txt), mas isto pode causar problemas de portabilidade do arquivo.
Comandos são ordens que passamos ao sistema operacional para executar uma determinada tarefa.
Cada comando tem uma função específica, devemos saber a função de cada comando e escolher o mais adequado para fazer o que desejamos, por exemplo:
ls - Mostra arquivos de diretórios
cd - Para mudar de diretório
Este guia tem uma lista de vários comandos organizados por categoria com a explicação sobre o seu funcionamento e as opções aceitas (incluindo alguns exemplos).
É sempre usado um espaço depois do comando para separá-lo de uma opção ou parâmetro que será passado para o processamento. Um comando pode receber opções e parâmetros:
opções
As opções são usadas para controlar como o comando será executado, por exemplo, para fazer uma listagem mostrando o dono, grupo, tamanho dos arquivos você deve digitar ls -l.
Opções podem ser passadas ao comando através de um "-" ou "--":
-
Opção identificada por uma letra. Podem ser usadas mais de uma opção com um único hífen. O comando ls -l -a é a mesma coisa de ls -la—Opção identificada por um nome. Também chamado de opção extensa. O comando ls—all é equivalente a ls -a.
Pode ser usado tanto "-" como "--", mas há casos em que somente parâmetros "-" ou "--" esta disponível.
Um parâmetro identifica o caminho, origem, destino, entrada padrão ou saída padrão que será passada ao comando.
Se você digitar: ls /usr/share/doc/copyright, /usr/share/doc/copyright será o parâmetro passado ao comando ls, neste caso queremos que ele liste os arquivos do diretório /usr/share/doc/copyright.
É normal errar o nome de comandos, mas não se preocupe, quando isto acontecer o sistema mostrará a mensagem command not found (comando não encontrado) e voltará ao aviso de comando. As mensagens de erro não fazem nenhum mal ao seu sistema, somente dizem que algo deu errado para que você possa corrigir e entender o que aconteceu. No GNU/Linux, você tem a possibilidade de criar comandos personalizados usando outros comandos mais simples (isto será visto mais adiante). Os comandos se encaixam em duas categorias: Comandos Internos e Comandos Externos.
Por exemplo: "ls -la /usr/share/doc", ls é o comando, -la é a opção passada ao comando, e /usr/share/doc é o diretório passado como parâmetro ao comando ls.
São comandos que estão localizados dentro do interpretador de comandos (normalmente o Bash) e não no disco. Eles são carregados na memória RAM do computador junto com o interpretador de comandos.
Quando executa um comando, o interpretador de comandos verifica primeiro se ele é um Comando Interno caso não seja é verificado se é um Comando Externo.
Exemplos de comandos internos são: cd, exit, echo, bg, fg, source, help
Aviso de comando (ou Prompt), é a linha mostrada na tela para digitação de comandos que serão passados ao interpretador de comandos para sua execução.
A posição onde o comando será digitado é marcado um "traço" piscante na tela chamado de cursor. Tanto em shells texto como em gráficos é necessário o uso do cursor para sabermos onde iniciar a digitação de textos e nos orientarmos quanto a posição na tela.
O aviso de comando do usuário root é identificado por uma "#" (tralha), e o aviso de comando de usuários é identificado pelo símbolo "$". Isto é padrão em sistemas UNIX.
Você pode retornar comandos já digitados pressionando as teclas Seta para cima / Seta para baixo.
A tela pode ser rolada para baixo ou para cima segurando a tecla SHIFT e pressionando PGUP ou PGDOWN. Isto é útil para ver textos que rolaram rapidamente para cima.
Abaixo algumas dicas sobre a edição da linha de comandos (não é necessário se preocupar em decorá-los):
Pressione a tecla Back Space (" <-- ") para apagar um carácter à esquerda do cursor.
Pressione a tecla Del para apagar o carácter acima do cursor.
Pressione CTRL+A para mover o cursor para o inicio da linha de comandos.
Pressione CTRL+E para mover o cursor para o fim da linha de comandos.
Pressione CTRL+U para apagar o que estiver à esquerda do cursor. O conteúdo apagado é copiado para uso com CTRL+y.
Pressione CTRL+K para apagar o que estiver à direita do cursor. O conteúdo apagado é copiado para uso com CTRL+y.
Pressione CTRL+L para limpar a tela e manter o texto que estiver sendo digitado na linha de comando (parecido com o comando clear).
Pressione CTRL+Y para colocar o texto que foi apagado na posição atual do cursor.
Também conhecido como "shell". É o programa responsável em interpretar as instruções enviadas pelo usuário e seus programas ao sistema operacional (o kernel). Ele que executa comandos lidos do dispositivo de entrada padrão (teclado) ou de um arquivo executável. É a principal ligação entre o usuário, os programas e o kernel. O GNU/Linux possui diversos tipos de interpretadores de comandos, entre eles posso destacar o bash, ash, csh, tcsh, sh, etc. Entre eles o mais usado é o bash. O interpretador de comandos do DOS, por exemplo, é o command.com.
Os comandos podem ser enviados de duas maneiras para o interpretador: interativa e não-interativa.
Interativa
Os comandos são digitados no aviso de comando e passados ao interpretador de comandos um a um. Neste modo, o computador depende do usuário para executar uma tarefa, ou o próximo comando.
Não-interativa
São usados arquivos de comandos criados pelo usuário (scripts) para o computador executar os comandos na ordem encontrada no arquivo. Neste modo, o computador executa os comandos do arquivo um por um e dependendo do término do comando, o script pode checar qual será o próximo comando que será executado e dar continuidade ao processamento.
Este sistema é útil quando temos que digitar por várias vezes seguidas um mesmo comando ou para compilar algum programa complexo.
O shell Bash possui ainda outra característica interessante: a completação dos nomes. Isto é feito pressionando-se a tecla TAB. Por exemplo, se digitar "ls tes" e pressionar <tab>, o Bash localizará todos os arquivos que iniciam com "tes" e completará o restante do nome. Caso a completação de nomes encontre mais do que uma expressão que satisfaça a pesquisa, ou nenhuma, é emitido um beep. Se você apertar novamente a tecla TAB imediatamente depois do beep, o interpretador de comandos irá listar as diversas possibilidades que satisfazem a pesquisa, para que você possa escolher a que lhe interessa. A completação de nomes funciona sem problemas para comandos internos.
Exemplo: ech (pressione TAB). ls /vm(pressione TAB)
O interpretador de comandos, quando é chamado, herda algumas variáveis do processo que o invocou. Analogamente, o interpretador de comandos pode chamar outros interpretadores de comando (por exemplo, chamando scripts); neste caso, algumas variáveis são herdadas e outras não.
Uma variável é definida usando-se simplesmente o sinal de igual:
x=10
Neste caso, definiu-se uma variável local, ou seja, esta variável não será herdada pelos processos filhos. Para que x seja herdada, é necessário escrever:
Terminal (ou console) é o teclado e tela conectados em seu computador. O GNU/Linux faz uso de sua característica multi-usuária usando os "terminais virtuais". Um terminal virtual é uma segunda seção de trabalho completamente independente de outras, que pode ser acessada no computador local ou remotamente via telnet, rsh, rlogin, etc.
No GNU/Linux, em modo texto, você pode acessar outros terminais virtuais segurando a tecla ALT e pressionando F1 a F6. Cada tecla de função corresponde a um número de terminal do 1 ao 6 (o sétimo é usado por padrão pelo ambiente gráfico X). O GNU/Linux possui mais de 63 terminais virtuais, mas apenas 6 estão disponíveis inicialmente por motivos de economia de memória RAM (cada terminal virtual ocupa aproximadamente 350 Kb de memória RAM, desative a quantidade que não estiver usando para liberar memória RAM para uso de outros programas!) .
Se estiver usando o modo gráfico, você deve segurar CTRL+ ALT enquanto pressiona uma tela de <F1> a <F6>. Para voltar ao modo gráfico, pressione CTRL+ALT+ <F7>.
Um exemplo prático: Se você estiver usando o sistema no Terminal 1 com o nome "joao" e desejar entrar como "root" para instalar algum programa, segure ALT enquanto pressiona <F2> para abrir o segundo terminal virtual e faça o login como "root". Será aberta uma nova seção para o usuário "root" e você poderá retornar a hora que quiser para o primeiro terminal pressionando ALT+<F1>.
Curingas (ou referência global) é um recurso usado para especificar um ou mais arquivos ou diretórios do sistema de uma só vez. Este é um recurso permite que você faça a filtragem do que será listado, copiado, apagado, etc. São usados 4 tipos de curingas no GNU/Linux:
"*" - Faz referência a um nome completo/restante de um arquivo/diretório.
"?" - Faz referência a uma letra naquela posição.
[padrão] - Faz referência a uma faixa de caracteres de um arquivo/diretório. Padrão pode ser:
[a-z][0-9] - Faz referência a caracteres de a até z seguido de um caracter de 0 até 9.
[a,z][1,0] - Faz a referência aos caracteres a e z seguido de um caracter 1 ou 0 naquela posição.
[a-z,1,0] - Faz referência a intervalo de caracteres de a até z ou 1 ou 0 naquela posição.
A procura de caracteres é "Case Sensitive" assim se você deseja que sejam localizados todos os caracteres alfabéticos você deve usar [a-zA-Z].
Caso a expressão seja precedida por um ^, faz referência a qualquer caracter exceto o da expressão. Por exemplo [^abc] faz referência a qualquer caracter exceto a, b e c.
{padrões} - Expande e gera strings para pesquisa de padrões de um arquivo/diretório.
X{ab,01} - Faz referência a seqüencia de caracteres Xab ou X01
X{a-z,10} Faz referencia a seqüencia de caracteres Xa-z e X10.
O que diferencia este método de expansão dos demais é que a existência do arquivo/diretório é opcional para geração do resultado. Isto é útil para a criação de diretórios. Lembrando que os 4 tipos de curingas ("*", "?", "[]", "{}") podem ser usados juntos. Para entender melhor vamos a prática:
Vamos dizer que tenha 5 arquivo no diretório /usr/teste: teste1.txt, teste2.txt, teste3.txt, teste4.new, teste5.new.
Caso deseje listar todos os arquivos do diretório /usr/teste você pode usar o coringa "*" para especificar todos os arquivos do diretório:
cd /usr/teste e ls * ou ls /usr/teste/*.
Não tem muito sentido usar o comando ls com "*" porque todos os arquivos serão listados se o ls for usado sem nenhum Coringa.
Agora para listar todos os arquivos teste1.txt, teste2.txt, teste3.txt com exceção de teste4.new, teste5.new, podemos usar inicialmente 3 métodos:
Usando o comando ls *.txt que pega todos os arquivos que começam com qualquer nome e terminam com .txt.
Usando o comando ls teste?.txt, que pega todos os arquivos que começam com o nome teste, tenham qualquer caracter no lugar do coringa ? e terminem com .txt. Com o exemplo acima teste*.txt também faria a mesma coisa, mas se também tivéssemos um arquivo chamado teste10.txt este também seria listado.
Usando o comando ls teste[1-3].txt, que pega todos os arquivos que começam com o nome teste, tenham qualquer caracter entre o número 1-3 no lugar da 6a letra e terminem com .txt. Neste caso se obtém uma filtragem mais exata, pois o coringa ? especifica qualquer caracter naquela posição e [] especifica números, letras ou intervalo que será usado.
Agora para listar somente teste4.new e teste5.new podemos usar os seguintes métodos:
ls *.new que lista todos os arquivos que terminam com .new
ls teste?.new que lista todos os arquivos que começam com teste, contenham qualquer caracter na posição do coringa ? e terminem com .new.
ls teste[4,5].* que lista todos os arquivos que começam com teste contenham números de 4 e 5 naquela posição e terminem com qualquer extensão.
Existem muitas outras formas de se fazer a mesma coisa, isto depende do gosto de cada um. O que pretendi fazer aqui foi mostrar como especificar mais de um arquivo de uma só vez. O uso de curingas será útil ao copiar arquivos, apagar, mover, renomear, e nas mais diversas partes do sistema. Alias esta é uma característica do GNU/Linux: permitir que a mesma coisa possa ser feita com liberdade de várias maneiras diferentes.
Hardware é tudo que diz respeito a parte física do computador. Nesta seção serão abordados assuntos relacionados com a configuração de hardwares, escolha de bons hardwares, dispositivos for Windows, etc.
Seria terrível se, ao configurarmos CADA programa que utilize o mouse ou o modem, precisássemos nos referirmos a ele pela IRQ, I/O, etc... Para evitarmos isto, usamos os nomes de dispositivos.
Os nomes de dispositivos no sistema GNU/Linux são acessados através do diretório /dev. Após configurarmos corretamente o modem, com sua porta I/O 0x2F8 e IRQ 3, ele é identificado automaticamente por /dev/ttyS1 (equivalente a COM2 no DOS). Daqui para frente, bastará nos referirmos a /dev/ttyS1 para fazermos alguma coisa com o modem.
Você também pode fazer um link de /dev/ttyS1 para um arquivo chamado /dev/modem, usando: ln -s /dev/ttyS1 /dev/modem. Para isso, faça a configuração dos seus programas usando /dev/modem ao invés de /dev/ttyS1 e, se precisar reconfigurar o seu modem e a porta serial, mude para /dev/ttyS3. Será necessário somente apagar o link /dev/modem antigo e criar um novo que aponte para a porta serial /dev/ttyS3.
Não será necessário reconfigurar os programas que usam o modem, pois eles estão usando /dev/modem que está apontando para a localização correta. Isto é muito útil para um bom gerenciamento do sistema.
Abaixo uma tabela com o nome do dispositivo no GNU/Linux, portas I/O, IRQ, DMA e o nome do dispositivo no DOS (os nomes de dispositivos estão localizados no diretório /dev):
Dispos. Linux
Dispos. DOS
IRQ
DMA
I/O
ttyS0
COM1
4
-
0x3F8
ttyS1
COM2
3
-
0x2F8
ttyS2
COM3
4
-
0x3E8
ttyS3
COM4
3
-
0x2E8
lp0
LPT1
7
3(ECP)
0x378
lp1
LPT2
5
3(ECP)
0x278
/dev/hda1
C:*
14
-
0x1F0,0x3F6
/dev/hda2
D:*
14
-
0x1F0,0x3F6
/dev/hdb1
D:*
15
-
0x170,0x376
A designação de letras de unidade do DOS não segue o padrão do GNU/Linux e depende da existência de outras unidades físicas/lógicas no computador.
A configuração de hardware consiste em ajustar as opções de funcionamento dos dispositivos (periféricos) para que se comuniquem com a placa mãe, bem como a configuração do software correspondente para propocrcionar acesso ao hardware. Um sistema bem configurado consiste em cada dispositivo funcionando com suas portas I/O, IRQ, DMA bem definidas, não existindo conflitos com outros dispositivos. Isto também permitirá a adição de novos dispositivos ao sistema sem problemas.
Dispositivos PCI, PCI Express, AMR, CNR possuem configuração automática de recursos de hardware, podendo apenas ser ligados na máquina para serem reconhecidos pela placa mãe. Após isso, deverá ser feita a configuração do módulo do kernel para que o hardware funcione corretamente.
Os parâmetros dos módulos do kernel, usados para configurar dispositivos de hardware, são a IRQ, DMA e I/O. Para dispositivos plug and play, como hardwares PCI, basta carregar o módulo para ter o hardware funcionando.
Existem dois tipos básicos de interrupções: as usadas por dispositivos (para a comunicação com a placa mãe) e programas (para obter a atenção do processador). As interrupções de software são mais usadas por programas, incluindo o sistema operacional, e as interrupções de hardware são mais usadas por periféricos. Daqui para frente, serão explicados somente os detalhes sobre as interrupções de hardware.
Os antigos computadores 8086/8088 (XT) usavam somente 8 interrupções de hardware, operando a 8 bits. Com o surgimento do AT, foram incluídas 8 novas interrupções, operando a 16 bits. Os computadores 286 e superiores tem 16 interrupções de hardware, numeradas de 0 a 15. No kernel 2.4 e superiores do Linux, a função APIC (Advanced Programmable Interruption Controller) permite gerenciar de forma avançada mais de 15 interrupções no sistema operacional. Estas interrupções oferecem ao dispositivo associado a capacidade de interromper o que o processador estiver fazendo, pedindo atenção imediata.
As interrupções do sistema podem ser visualizadas no kernel com o comando cat /proc/interrupts. Abaixo um resumo do uso mais comum das 16 interrupções de hardware:
Nº
Interrupções de hardware
0
Timer do Sistema - Fixa
01
Teclado - Fixa
02
Controlador de Interrupção Programável - Fixa.
Esta interrupção é usada como ponte para a IRQ 9 e vem dos
antigos processadores 8086/8088 que somente tinham 8 IRQs.
Assim, para tornar processadores 8088 e 80286 comunicáveis,
a IRQ 2 é usada como um redirecionador quando se utiliza uma
interrupção acima da 8.
03
Normalmente usado por /dev/ttyS1, mas seu uso depende dos
dispositivos instalados no sistema (como fax-modem,
placas de rede 8 bits, etc).
04
Normalmente usado por /dev/ttyS0 e, quase sempre, usada pelo mouse
serial, a não ser que um mouse PS2 esteja instalado no sistema.
05
Normalmente a segunda porta paralela. Muitos micros não tem a segunda
porta paralela, assim é comum encontrarmos placas de som e outros
dispositivos usando esta IRQ.
06
Controlador de Disquete - Esta interrupção pode ser compartilhada
com placas aceleradoras de disquete, usadas em tapes (unidades de fita).
07
Primeira porta de impressora. Pessoas tiveram sucesso compartilhando
esta porta de impressora com a segunda porta de impressora.
Muitas impressoras não usam IRQs.
08
Relógio em tempo real do CMOS - Não pode ser usado por nenhum
outro dispositivo.
09
Esta é uma ponte para IRQ2 e deve ser a última IRQ a ser
utilizada. No entanto, pode ser usada por dispositivos.
10
Interrupção normalmente livre para dispositivos. O controlador
USB utiliza essa interrupção quando presente, mas não é regra.
11
Interrupção livre para dispositivos
12
Interrupção normalmente livre para dispositivos. O mouse PS/2,
quando presente, utiliza esta interrupção.
13
Processador de dados numéricos - Não pode ser usada ou compartilhada
14
Esta interrupção é usada pela primeira controladora de discos
rígidos e não pode ser compartilhada.
15
Esta é a interrupção usada pela segunda controladora de discos
e não pode ser compartilhada. Pode ser usada caso a segunda
controladora esteja desativada.
Dispositivos ISA, VESA, EISA, SCSI não permitem o compartilhamento de uma mesma IRQ, talvez isto ainda seja possível caso não haja outras opções disponíveis e/ou os dois dispositivos não acessem a IRQ ao mesmo tempo, mas isto é uma solução precária.
Conflitos de IRQ ocorriam nesse tipo de hardware acima, ocasionando a parada ou mal funcionamento de um dispositivo e/ou de todo o sistema. Para resolver um conflito de IRQs, deve-se conhecer quais IRQs estão sendo usadas e por quais dispositivos (usando cat /proc/interrupts) e configurar as interrupções de forma que uma não entre em conflito com outra. Isto normalmente é feito através dos jumpers de placas ou através de software (no caso de dispositivos jumperless ou plug-and-play).
Dispositivos PCI, PCI Express são projetados para permitir o compartilhamento de interrupções. Se for necessário usar uma interrupção normal, o chipset (ou BIOS) mapeará a interrupção para uma interrupção normal do sistema (normalmente usando alguma interrupção entre a IRQ 9 e IRQ 12) ou usando APIC (se estiver configurado).
Cada IRQ no sistema tem um número que identifica a prioridade que será atendida pelo processador. Nos antigos sistemas XT, as prioridades eram identificadas em sequência de acordo com as interrupções existentes:
IRQ
0
1
2
3
4
5
6
7
8
PRI
1
2
3
4
5
6
7
8
9
Com o surgimento do barramento AT (16 bits), as interrupções passaram a ser identificadas da seguinte forma:
IRQ
0 1 2 (9 10 11 12 13 14 15) 3 4 5 6 7 8
PRI
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Note que a prioridade segue em sequência através da ponte da IRQ 2 para IRQ 9. Os dispositivos com prioridade mais baixa são atendidos primeiro, mas é uma diferença de desempenho praticamente imperceptível de ser notada nos sistemas atuais.
A DMA é usada para permitir a transferência de dados entre dispositivos I/O e a memória sem precisar do processador fazê-lo. Ela livra desta carga o processador e resulta em uma rápida transferência de dados.
O PC padrão tem dois controladores de DMA. O primeiro controla os canais 0, 1, 2, 3 e o segundo os canais 4, 5, 6, 7, assim temos 8 canais. No entanto, o canal 4 é perdido porque é usado pelo controlador de acesso direto a memória. Os canais 0-3 são chamados de canais baixos porque podem somente mover um byte (8 bits) por transferência enquanto canais altos movem 2 bytes (16 bits) por transferência.
Os dados movidos usando a DMA não são movidos através do controlador de DMA. Isto oferece uma limitação porque a DMA somente pode mover dados entre os dispositivos (portas I/O) e a memória. Não é possível mover dados entre as portas ou entre a memória.
Existem dois controladores de DMA nos computadores AT e superiores. Ao contrário do que acontece com os dois controladores de IRQ, o primeiro controlador é ligado ao segundo e não o segundo ao primeiro. Os canais de DMA altos (5 ao 7) somente podem ser acessados por dispositivos de 16 bits (aqueles que utilizam a segunda parte do slot AT). Como resultado temos 8 canais de DMA, de 0 a 7, sendo que a DMA 4 é usada como ligação entre eles.
Os canais de DMA em uso no sistema podem ser visualizados com cat /proc/dma. Abaixo uma listagem de usos mais comuns dos canais de DMA.
DMA
Barram.
Uso
0
-
Usada pelo circuito de refresh da memória DRAM
1
8/16 bits
Normalmente usado por placas de som (canal 8 bits),
porta paralela ECP, adaptadoras SCSI, placas de rede ou
controladora de scanner.
2
8/16 bits
Normalmente usado pela controladora de disquetes ou
controladoras de tapes.
3
8/6 bits
Usado pela porta paralela ECP, placa de som,
controladoras de tapes, controladoras SCSI ou
controladora de scanner antiga.
4
-
Usada como ponte para a outra controladora de DMA (0-3)
5
16 bits
Normalmente usada pela placa de som (canal 16 bits),
placas controladoras SCSI, placas de rede ou
controladora de scanner.
6
16 bits
Placa de som (canal 16 bits), controladora de scanner
ou placa de rede.
7
16 bits
Placa de som (canal 16 bits), controladora de scanner
ou placa de rede.
Somente dispositivos ISA e derivados deles, como o EISA e VESA, usam os canais de DMA padrão. Os atuais dispositivos de alta taxa de transferência (normalmente PCI) possuem seu próprio controlador de DMA embutido, muito mais rápido do que a DMA padrão. Este controlador de DMA é chamado de Bus Mastering, muito usado nos discos rígidos atuais, e pode atingir taxas de 33,3MB/s (no modo 2) e 66MB/s (no modo 4 - requer um cabo IDE com aterramento para evitar interferências de ruídos externos).
Um canal de DMA não pode ser compartilhado entre dispositivos. Ainda é possível configurar dois dispositivos para usarem um mesmo canal de DMA, desde que ele não seja usado ao mesmo tempo. Isto acontece com Scanners paralelos que compartilham a mesma porta paralela com a impressora. Se você for uma pessoa que explora os recursos de multitarefa de seu Linux e seu desempenho, evite estes tipos de dispositivos, prefira aqueles que utilizam seus próprios recursos.
Quando ocorre um conflito de DMA, os dados podem ser misturados e ocorrerem coisas estranhas até o travamento total do sistema. Este tipo de conflito é difícil de se diagnosticar, a não ser que o técnico seja experiente o bastante e tenha desconfiado de que problema se trata...
Cada dispositivo possui um endereço de porta. O endereço é uma localização da memória, usada pelo computador para enviar dados ao dispositivo, e de onde o dispositivo envia dados ao computador. Ao contrários da IRQ e DMA, o dispositivo pode usar mais de uma porta de Entrada/Saída ou uma faixa de endereços. Por exemplo, uma placa de som padrão usa as portas 0x220, 0x330 e 0x388, respectivamente: áudio digital, midi e opl3.
As placas de rede normalmente transferem grandes quantidades de dados, assim ocupam uma faixa de endereços. Uma NE2000, por exemplo, ocupa a faixa de endereços 0x260 a 0x27F (0x260-0x27F). O tamanho da faixa de endereços varia de acordo com o tipo de dispositivo.
Os endereços de I/O, em uso no sistema, podem ser visualizados com o comando cat /proc/ioports.
Endereços das portas de entrada/saída não podem ser compartilhados.
Hardwares configuráveis por jumpers, dip-switches, jumperless e Plug-and-Play.
Hardwares configuráveis por jumpers (pinos metálicos protegidos por uma capa plástica) tem sua configuração alterada através da colocação, retirada ou mudança de posição física do pino. Este tipo de hardware, antigamente presente em placas ISA e VESA, não é mais usado atualmente devido a configuração Plug and Play de dispositivos PCI, PCI express, etc.
As disposições dos jumpers são normalmente definidas em fechado/aberto e multi-posição. Na disposição fechado/aberto, o jumper pode ou não ser colocado, definindo a configuração do dispositivo:
::|::
Esta disposição é facilmente encontrada na seleção de IRQ e I/O em placas de fax-modem.
Na disposição multi-posição, os pinos de encaixe são numerados de 1 a 3 (ou 1 a 4, 1 a 5, etc) e os pinos podem ou não ser colocados na placa e a posição em que são colocados também influencia os valores escolhidos para o funcionamento do dispositivo (as posições 1-2 especificam um valor enquanto 2-3 especificam outro). A associação entre a posição dos jumpers e a configuração desejada é feita consultando o mapa desenhado no circuito impresso da placa ou o manual de instruções da placa.
A configuração de jumper através de multi-posição é normalmente usada em placas mãe para definir a frequência de operação do barramento, a frequência de multiplicação ou o tipo do processador.
Se não possuir o mapa de configuração de sua placa e/ou o manual de instruções, será necessário fazer um mapeamento manual da placa, mas para isto você precisará conhecer detalhadamente a configuração de portas I/O, DMA, IRQ usadas na máquina que será usada e anotar as diferenças obtidas através da modificação da pinagem do dispositivo. Isto não é fácil, mas técnicos de informática experientes conhecerão as armadilhas encontradas pelo mapeamento manual de placas e farão o esquema de configuração completo do dispositivo, obtendo um excelente manual de instruções. Nesta hora, a experiência conta mais do que o uso de programas de diagnóstico.
Outra característica de hardwares configurados através de jumpers é que raramente apresentam problemas de funcionamento, a não ser que seus parâmetros como IRQ, DMA, ou I/O estejam em conflito com outro dispositivo, mas isso não é culpa do fabricante e nem mesmo do dispositivo...
É a mesma coisa que os hardwares configuráveis por jumpers exceto que são usados dip-switches no lugar de jumpers. O dip-switches é um conjunto de chaves numeradas que podem ser colocadas para cima ou para baixo (como um disjuntor ou vários interruptores LIGA/DESLIGA colocados um ao lado do outro) para se modificar a configuração do dispositivo.
Os hardwares jumperless não possuem jumpers e são configurados através de um programa que acompanha a própria placa. Neste programa é escolhida a IRQ, DMA, I/O e a configuração é salva na própria placa ou restaurada após cada inicialização por um programa carregado na memória. Devido a configuração via software, se obtém uma configuração fixa com muito mais facilidade do que via jumpers (por não haver a necessidade de se retirar a placa).
A maioria das placas jumperless podem funcionar também como Plug-and-Play. Existem muitas placas de rede, fax-modem, scanner jumperless no mercado.
O Plug-and-Play é um protocolo que lê os valores de operação disponíveis para a placa e permitem que o usuário possa especificar facilmente qual será sua IRQ, DMA, I/O. Hardwares PCI possuem configuração Plug-and-Play nativa, registrando suas interrupções, portas e dma na tabela de hardwares PCI do sistema.
A diferença em relação ao modo jumperless é que toda a configuração do hardware (IRQ, DMA e I/O) é feita pelo kernel do Linux, onde ele passa a configuração detectada durante a inicialização do sistema para os módulos carregados, garantindo o perfeito funcionamento do dispositivos e evitando conflitos. Na época de hardwares ISA e VESA, o programa isapnp era a preferência para a configuração de placas ISA Plug and Play.
Veja a próxima seção para entender como funciona o arquivo de configuração isapnp.conf e assim poder ativar seu dispositivo Plug-and-Play.
Listando as placas e outros hardwares em um computador
Administradores e técnicos ao configurar uma máquina precisarão saber quais os hardwares ela possui, periféricos e até mesmo a revisão de dispositivos e clock para configurar as coisas e ver a necessidade de atualizações de dispositivos atuais.
Dispositivos PCI/AMR/CNR podem ser listados executando o comando cat /proc/pci. Outra forma de listar tais dispositivos é usando o lspci, se você precisa de mais detalhes como o mapeamento de memória, use lspci -vv.
O mapeamento de memória de dispositivos podem ser mostrados com o comando cat /proc/ioports, ou usando o comando lsdev.
O barramento USB e dispositivos conectados a ele podem ser listados com o comando lsusb ou com cat /proc/bus/usb/devices.
Hardwares disponíveis na máquina, como placa mãe, clock multiplicador, discos, placas diversas, versões e números seriais de dispositivos podem ser mostrados através do comando lshw. Use lshw -html para produzir a listagem em formato HTML, bem interessante para relatórios :-)
Ocorre quando um ou mais dispositivos usam a mesma IRQ, I/O ou DMA. Um sistema com configurações de hardware em conflito tem seu funcionamento instável, travamentos constantes, mal funcionamento de um ou mais dispositivos e até mesmo, em casos mais graves, a perda de dados. Conflitos geralmente ocorriam em placas ISA, VESA onde era necessário conhecer e usar uma tabela de valores padrões para a configuração de periféricos (como a mostrada no inicio desse capítulo).
Para resolver conflitos de hardware é necessário conhecer a configuração de cada dispositivo em seu sistema. Os comandos cat /proc/interrupts, cat /proc/dma e cat /proc/ioports podem ser úteis para se verificar as configurações usadas.
O tipo de slot varia de acordo com o barramento usado no sistema, que pode ser um(s) do(s) seguinte(s):
ISA 8 Bits
Industry Standard Architecture - É o padrão mais antigo, encontrado em computadores PC/XT.
ISA 16 Bits
Evolução do padrão ISA 8 Bits, possui um conector maior e permite a conexão de placas de 8 bits. Sua taxa de transferência chega a 2MB/s.
VESA
Video Electronics Standard Association - É uma interface feita inicialmente para placas de vídeo rápidas. O barramento VESA é basicamente um ISA com um encaixe extra no final. Sua taxa de transferência pode chegar a 132MB/s.
EISA
Enhanced Industry Standard Architecture - É um barramento mais encontrado em servidores. Tem a capacidade de bus mastering, que possibilita a comunicação das placas sem a interferência da CPU.
MCA
Micro Channel Architecture - Barramento 32 bits proprietário da IBM. Você não pode usar placas ISA nele, possui a característica de bus mastering, mas pode procurar por dispositivos conectados a ele, procurando configuração automática.
Este barramento estava presente no PS/1 e PS/2, hoje não é mais usado.
PCI
Peripheral Component Interconnect - É outro barramento rápido produzido pela Intel com a mesma velocidade que o VESA. O barramento possui um chipset de controle que faz a comunicação entre os slots PCI e o processador. O barramento se configura automaticamente (através do Plug-and-Play). O PCI é o barramento mais usado por Pentiums e está se tornando um padrão em PC.
PCI Express
Peripheral Component Interconnect Express - Idêntico ao barramento PCI, funcionando nativamente no clock de 64 bits.
AGP
Accelerated Graphics Port - É um novo barramento criado exclusivamente para a ligação de placas de vídeo. É um slot marrom (em sua maioria) que fica mais separado do ponto de fixação das placas no chassis (comparado ao PCI). Estas placas permitem obter um desempenho elevado de vídeo se comparado as placas onboards com memória compartilhada e mesmo PCI externas. O consumo de potência em placas AGP x4 podem chegar até a 100W, portanto é importante dimensionar bem o sistema e ter certeza que a fonte de alimentação pode trabalhar com folga.
PCMCIA
Personal Computer Memory Card International Association - É um slot especial usado para conexões de placas externas (normalmente revestidas de plástico) e chamadas de cartões PCMCIA. Estes cartões podem adicionar mais memória ao sistema, conter um fax-modem, placa de rede, disco rígido, etc.
Os cartões PCMCIA são divididos em 3 tipos:
Tipo 1
Tem a espessura de 3.3 milímetros, e podem conter mais memória RAM ou memória Flash.
Tipo 2
Tem a espessura de 5 milímetros e capacidade de operações I/O. É um tipo usado para placas de fax-modem, rede, som. Computadores que aceitam cartões PCMCIA do tipo 2, mantém a compatibilidade com o tipo 1.
Tipo 3
Tem a espessura de 10.5 milímetros e normalmente usado para discos rígidos PCMCIA. Slots PCMCIA do tipo 3 mantém a compatibilidade com o tipo 2 e 1.
AMR
Audio Modem Raise - Pequeno barramento criado pela Intel para a conexão de placas de som e modem. Placas de som e modem AMR usam o HSP (host signal processor) e são como as Placas on-board e todo o processamento é feito pela CPU do computador (veja detalhes em Placas on-board / off-boardHardwares específicos ou "For Windows"
Sua vantagem é o preço: um modem ou placa de som AMR custa em torno de R$ 25,00.
CNR
Communication and Networking Rise - Pequeno barramento criado pela Intel para a conexão de placas de som, modens e placas de rede. Este é um pequenino slot marrom que é localizado no ponto de fixação das placas no chassis do gabinete. Elas são como as Placas on-board e todo o processamento é feito pela CPU do computador (veja detalhes em Placas on-board / off-board e Hardwares específicos ou "For Windows"
O tipo de slot varia de acordo com o barramento usado no sistema, que pode ser um(s) do(s) seguinte(s):
ISA 8 Bits
Industry Standard Architecture - É o padrão mais antigo, encontrado em computadores PC/XT.
ISA 16 Bits
Evolução do padrão ISA 8 Bits, possui um conector maior e permite a conexão de placas de 8 bits. Sua taxa de transferência chega a 2MB/s.
VESA
Video Electronics Standard Association - É uma interface feita inicialmente para placas de vídeo rápidas. O barramento VESA é basicamente um ISA com um encaixe extra no final. Sua taxa de transferência pode chegar a 132MB/s.
EISA
Enhanced Industry Standard Architecture - É um barramento mais encontrado em servidores. Tem a capacidade de bus mastering, que possibilita a comunicação das placas sem a interferência da CPU.
MCA
Micro Channel Architecture - Barramento 32 bits proprietário da IBM. Você não pode usar placas ISA nele, possui a característica de bus mastering, mas pode procurar por dispositivos conectados a ele, procurando configuração automática.
Este barramento estava presente no PS/1 e PS/2, hoje não é mais usado.
PCI
Peripheral Component Interconnect - É outro barramento rápido produzido pela Intel com a mesma velocidade que o VESA. O barramento possui um chipset de controle que faz a comunicação entre os slots PCI e o processador. O barramento se configura automaticamente (através do Plug-and-Play). O PCI é o barramento mais usado por Pentiums e está se tornando uma padrão no PC.
PCI Express
Peripheral Component Interconnect Express - Identico ao barramento PCI, funcionando nativamente no clock de 64 bits.
AGP
Accelerated Graphics Port - É um novo barramento criado exclusivamente para a ligação de placas de video. É um slot marrom (em sua maioria) que fica mais separado do ponto de fixação das placas no chassis (comparado ao PCI). Estas placas permitem obter um desempenho elevado de vídeo se comparado as placas onboards com memória compartilhada e mesmo PCI externas. O consumo de potência em placas AGP x4 podem chegar até a 100W, portanto é importante dimensionar bem o sistema e ter certeza que a fonte de alimentação pode trabalhar com folga.
PCMCIA
Personal Computer Memory Card International Association - É um slot especial usado para conexões de placas externas (normalmente revestivas de plástico) e chamadas de cartões PCMCIA. Estes cartões podem adicionar mais memória ao sistema, conter um fax-modem, placa de rede, disco rígido, etc.
Os cartões PCMCIA são divididos em 3 tipos:
Tipo 1
Tem a espessura de 3.3 milímetros, e podem conter mais memória RAM ou memória Flash.
Tipo 2
Tem a espessura de 5 milímetros e capacidade de operações I/O. É um tipo usado para placas de fax-modem, rede, som. Computadores que aceitam cartões PCMCIA do tipo 2, mantém a compatibilidade com o tipo 1.
Tipo 3
Tem a espessura de 10.5 milímetros e normalmente usado para discos rígidos PCMCIA. Slots PCMCIA do tipo 3 mantém a compatibilidade com o tipo 2 e 1.
AMR
Audio Modem Raise - Pequeno barramento criado pela Intel para a conexão de placas de som e modem. Placas de som e modem AMR usam o HSP (host signal processor) e são como as Placas on-board e todo o processamento é feito pela CPU do computador (veja detalhes em [#s-hard-onoffboard Placas on-board / off-board, Seção 3.8] e [#s-hard-forwindows Hardwares específicos ou "For Windows", Seção 3.9].
Sua vantagem é o preço: um modem ou placa de som AMR custa em torno de R$ 25,00.
CNR
Communication and Networking Rise - Pequeno barramento criado pela Intel para a conexão de placas de som, modens e placas de rede. Este é um pequenino slot marrom que é localizado no ponto de fixação das placas no chassis do gabinete. Elas são como as Placas on-board e todo o processamento é feito pela CPU do computador (veja detalhes em [#s-hard-onoffboard Placas on-board / off-board, Seção 3.8] e [#s-hard-forwindows Hardwares específicos ou "For Windows", Seção 3.9].
Esta seção foi retirada do manual de instalação da Debian GNU/Linux. Uma tendência que perturba é a proliferação de Modens e impressoras específicos para Windows. Em muitos casos estes são especialmente fabricados para operar com o Sistema Operacional Microsoft Windows e costumam ter a legenda WinModem, for Windows, ou Feito especialmente para computadores baseados no Windows.
Geralmente estes dispositivos são feitos retirando os processadores embutidos daquele hardware e o trabalho deles são feitos por drivers do Windows que são executados pelo processador principal do computador. Esta estratégia torna o hardware menos caro, mas o que é poupado não é passado para o usuário e este hardware pode até mesmo ser mais caro do que dispositivos equivalentes que possuem inteligência embutida.
Você deve evitar o hardware baseado no Windows por duas razões:
A primeira é que aqueles fabricantes não tornam os recursos disponíveis para criar um driver para Linux. Geralmente, o hardware e a interface de software para o dispositivo é proprietária, e a documentação não é disponível sem o acordo de não revelação, se ele estiver disponível. Isto impede seu uso como software livre, desde que os escritores de software livre descubram o código fonte destes programas.
A segunda razão é que quando estes dispositivos tem os processadores embutidos removidos, o sistema operacional deve fazer o trabalho dos processadores embutidos, frequentemente em prioridade de tempo real, e assim a CPU não esta disponível para executar programas enquanto ela esta controlando estes dispositivos.
Assim, o usuário típico do Windows não obtém um multi-processamento tão intensivo como um usuário do Linux, o fabricante espera que aquele usuário do Windows simplesmente não note a carga de trabalho que este hardware põe naquela CPU. No entanto, qualquer sistema operacional de multi-processamento, até mesmo Windows 9X, XP e Vista, são prejudicados quando fabricantes de periféricos retiram o processador embutido de suas placas e colocam o processamento do hardware na CPU.
Você pode ajudar a reverter esta situação encorajando estes fabricantes a lançarem a documentação e outros recursos necessários para nós desenvolvermos drivers para estes hardwares, mas a melhor estratégia é simplesmente evitar estes tipos de hardwares até que eles estejam listados no HOWTO de hardwares compatíveis com Linux.
Note que hoje já existem muitos drivers para WinModems e outros hardwares for Windows para o Linux. Veja a lista de hardwares compatíveis no HARDWARE-HOWTO ou procure o driver no site do fabricante de seu dispositivo. Mesmo assim a dica é evitar hardwares for Windows e comprar hardwares inteligentes onde cada um faz sua função sem sobrecarregar a CPU.
Esta seção foi retirada do manual de instalação da Debian GNU/Linux. Existem diversos vendedores, agora, que vendem sistemas com a Debian ou outra distribuição do GNU/Linux pré-instaladas. Você pode pagar mais para ter este privilégio, mas compra um nível de paz de mente, desde então você pode ter certeza que seu hardware é bem compatível com GNU/Linux. Praticamente todas as placas que possuem processadores próprios funcionam sem nenhum problema no Linux (algumas placas da Turtle Beach e mwave tem suporte de som limitado).
Se você tiver que comprar uma máquina com Windows instalado, leia cuidadosamente a licença que acompanha o Windows; você pode rejeitar a licença e obter um desconto de seu vendedor.
Se não estiver comprando um computador com GNU/Linux instalado, ou até mesmo um computador usado, é importante verificar se os hardwares existentes são suportados pelo kernel do GNU/Linux. Verifique se seu hardware é listado no Hardware Compatibility HOWTO, na documentação do código fonte do kernel no diretório Documentation/sound ou consulte um técnico de GNU/Linux experiente.
Deixe seu vendedor (se conhecer) saber que o que está comprando é para um sistema GNU/Linux. Desta forma isto servirá de experiência para que ele possa recomendar o mesmo dispositivo a outras pessoas que procuram bons dispositivos para sistemas GNU/Linux. Apoie vendedores de hardwares amigos do GNU/Linux.
O site da Free Software Foundation mantém uma lista de hardwares com sua respectivas compatibilidades com sistemas GNU/Linux aqui <https://www.h-node.org/> que talvez facilite sua busca. Em caso de tablets, o projeto Replicant OS mantém uma lista de aparelhos com suas respectivas compatibilidades aqui: <http://redmine.replicant.us/projects/replicant/wiki/ReplicantStatus> .
As seções abaixo explicam como fazer configurações em dispositivos diversos no sistema Linux como placas de rede, som, gravador de CD entre outras.
Como regra geral, para um hardware funcionar adequadamente, deve-se:
Identificar o nome (marca, fabricante, versão, etc) do hardware. Provavelmente esta informação está no manual do computador ou pode ser obtida via software. Um programa que pode ajudar é o lshw[1]
Descobrir quais são os módulos que fazem este hardware funcionar. Neste ponto, uma busca por palavras-chave na Internet pode ser útil.[2]
Baixar, instalar e carregar este(s) módulo(s).
Configurar o hardware. Normalmente, este é o passo mais complicado, já que cada hardware tem opções peculiares e exóticas.
Baixar e instalar o software aplicativo que usa o hardware.
Os subcapítulos abaixo procuram seguir este caminho para diversos hardwares diferentes.
Para configurar sua placa de rede no Linux siga os passos a seguir:
Identifique se sua placa de rede é ISA ou PCI. Uma forma de verificar isso é rodar o comando lspci (que lista os dispositivos PCI). Se a placa nã aparece, provavelmente ela é ISA; neste caso pode ser preciso alterar a configuração de jumpers ou plug-and-play, evitando conflitos de hardware ou o não funcionamento da placa (veja como configura-la em [#s-hardw-metodoscfg Hardwares configuráveis por jumpers, dip-switches, jumperless e Plug-and-Play., Seção 3.4].
Identifique a marca/modelo de sua placa. O programa lshw é útil para isto. Caso sua placa seja PCI ou CNR, execute o comando lspci e veja a linha "Ethernet".
Em último caso, abra a máquina e procure a marca na própria placa. Quase todos os fabricantes colocam a marca da placa no próprio circuito impresso ou no CI principal da placa (normalmente é o maior).
Depois de identificar a placa, será preciso carregar o módulo correspondente para ser usada no Linux. Em algumas instalações padrões o suporte já pode estar embutido no kernel, neste caso, você poderá pular este passo.
Para carregar um módulo, digite o comando modprobe modulo (Veja [ch-kern.html#s-kern-modprobe modprobe, Seção 16.8]) . Em placas ISA, geralmente é preciso passar a IRQ e porta de I/O como argumentos para alocar os recursos corretamente. O modprobe tentará auto-detectar a configuração em placas ISA, mas ela poderá falhar por algum motivo. Por exemplo, para uma NE 2000: modprobe ne io=0x300 irq=10.
Para evitar a digitação destes parâmetros toda vez que a máquina for iniciada é recomendável coloca-lo no arquivo /etc/modules.conf da seguinte forma:
options ne io=0x300 irq=10
A partir de agora, você pode carregar o módulo de sua placa NE 2000 apenas com o comando modprobe ne. O parâmetro io=0x300 irq=10 será automaticamente adicionado. Em sistemas Debian, o local correto para colocar as opções de um módulo é em arquivos separados localizados dentro de /etc/modutils. Crie um arquivo chamado /etc/modutils/ne e coloque a linha:
options ne io=0x300 irq=10
Depois disso, execute o comando update-modules para o sistema gerar um novo arquivo /etc/modules.conf com todos os módulos de /etc/modutils e substituir o anterior.
Após carregar o módulo de sua placa de rede, resta apenas configurar seus parâmetros de rede para coloca-la em rede. Veja [ch-rede.html#s-rede-interfaces-c Atribuindo um endereço de rede a uma interface (ifconfig), Seção 15.4.2].
A configuração de dispositivos de audio no Linux é simples, bastando carregar o módulo da placa e ajustar o mixer. Atualmente existem 2 padrões de som no sistema Linux: OSS (Open Sound System) e ALSA (Advanced Linux Sound Architecture).
O OSS foi o primeiro padrão adotado em sistemas Linux, que tinha como grande limitação a dificuldade em usar diversas placas e a impossibilidade dos programas utilizaram ao mesmo tempo a placa de som. O ALSA é mais novo, suporta full duplex e outros recursos adicionais, além de manter a compatibilidade com OSS. O ALSA é um padrão mais moderno e garante mais performance para a CPU da máquina, principalmente para a exibição de vídeos, etc.
OSS é o presente por padrão desde que o suporte a som foi incluído no kernel. Para configurar uma placa de som para usar este sistema de som, primeiro compile seu kernel com o suporte ao módulo de sua placa de som. Caso seja uma placa ISA, você provavelmente terá que habilitar a seção "Open Sound System" para ver as opções disponíveis (entre elas, a Sound Blaster e compatíveis). Uma olhada na ajuda de cada módulo deve ajuda-lo a identificar quais placas cada opção do kernel suporta.
Caso seu kernel seja o padrão de uma distribuição Linux, provavelmente terá o suporte a todas as placas de som possíveis. Siga o passo a passo abaixo para configurar sua placa de som no sistema:
Primeiro descubra se sua placa de som é ISA. Caso seja, verifique se os seus recursos estão alocados corretamente (veja [#s-hardw-conflitos Conflitos de hardware, Seção 3.6]). Caso seja PCI, AMR, execute o comando lspci, procure pela linha "Multimedia" e veja o nome da placa. Você também poderá executar o comando lshw para descobrir qual placa você possui (veja [#s-hardw-findhw Listando as placas e outros hardwares em um computador, Seção 3.5]) para detalhes.
Carregue o módulo da placa de som com o comando modprobe módulo (veja [ch-kern.html#s-kern-modprobe modprobe, Seção 16.8]). Na Debian, você pode executar o comando modconf para navegar visualmente entre os módulos disponíveis e carregar os módulos necessários.
Algumas placas (principalmente ISA) requerem que seja especificado o recurso de hardware sejam passados para seu módulo, ou simplesmente você quer especificar isto para manter o uso de hardware sobre seu controle. Alguns dos parâmetros mais usados em placas Sound Blaster são os seguintes:
Assim, quando der o comando modprobe sb ele será carregado com as opções acima. Na distribuição Debian, você deverá criar um arquivo chamado /etc/modutils/sb contendo a linha acima, depois execute o update-modules para "juntar" todos os arquivos do /etc/modutils e criar o /etc/modules.conf.
Após carregar o módulo correto de sua placa de som, seu sistema de som deverá estar funcionando. Se você utiliza uma distribuição Linux, os dispositivos de som como /dev/audio, /dev/dsp, /dev/mixer estarão criados e então poderá passar para o próximo passo. Caso não existam, entre no diretório /dev e execute o comando MAKEDEV audio.
O próximo passo consiste em instalar um programa para controle de volume, tonalidade e outros recursos de sua placa de som. O recomendado é o aumix por ser simples, pequeno e funcional, e permitindo restaurar os valores dos níveis de volumes na inicialização (isso evita que tenha que ajustar o volume toda vez que iniciar o sistema).
Caso o aumix apareça na tela, sua placa de som já está funcionando! Caso acesse o sistema como usuário, não se esqueça de adicionar seu usuário ao grupo audio para ter permissão de usar os dispositivos de som: adduser usuario audio .
Caso seu gravador seja IDE, veja [#s-hardw-cfgdisp-cdwritter-ide Configurando o suporte a um gravador IDE, Seção 3.11.3.1] caso seja um autêntico gravador com barramento SCSI, vá até [#s-hardw-cfgdisp-cdwritter-scsi Configurando o suporte a um gravador SCSI, Seção 3.11.3.2].
Caso tenha um gravador IDE e use um kernel 2.6 ou superior, não é necessário fazer qualquer configuração, pois seu gravador já está pronto para ser usado, sendo acessado através de seu dispositivo tradicional (/dev/hdc, /dev/hdd, etc). De qualquer forma, você poderá realizar a configuração da unidade IDE com emulação SCSI, assim como utilizava no kernel 2.4 e inferiores seguindo as instruções abaixo.
Para configurar seu gravador de CD/DVD IDE para ser usado no Linux usando o método para o kernel 2.4 e inferiores, siga os seguintes passos:
Tenha certeza que compilou o suporte as seguintes características no kernel:
Em "ATA/IDE/MFM/RLL support" marque as opções:
* Include IDE/ATAPI CDROM support
* SCSI emulation support
Depois em "SCSI support" marque as opções:
* SCSI support
M SCSI CD-ROM Support
M SCSI Generic Support
As opções marcadas como "*" serão embutidas no kernel e as "M" como módulos. Note que ambas as opções "IDE/ATAPI CDROM" e "SCSI Emulation" foram marcadas como embutidas. Isto faz com que o driver ATAPI tenha prioridade em cima do SCSI, mas vou explicar mais adiante como dizer para o kernel para carregar o suporte a SCSI para determinada unidade. Isto é útil quando temos mais de 1 unidade de CD IDE no sistema e queremos configurar somente o gravador para SCSI, pois alguns aplicativos antigos não se comunicam direito tanto com gravadores SCSI como emulados.
Você também pode marcar somente a opção "SCSI Emulation" para que sua(s) unidade(s) seja(m) automaticamente emulada(s) como SCSI. Caso tenha usado esta técnica, vá até a seção [#s-hardw-cfgdisp-cdwritter-teste Testando o funcionamento, Seção 3.11.3.3].
O próximo passo é identificar o dispositivo de CD/DVD. Isto é feito através do comando dmesg. Supondo que sua unidade de CD é "hdc" (primeiro disco na segunda controladora IDE) e que compilou ambos o suporte a "IDE ATAPI" e "SCSI emulation" no kernel, adicione o argumento "hdc=ide-scsi" no /etc/lilo.conf ou no grub:
# Lilo
vmlinuz=/vmlinuz
append="hdc=ide-scsi"
Isto diz para o kernel que a unidade "hdc" usará emulação "ide-scsi". Caso tenha outras unidades de CD no sistema, estas ainda utilização ATAPI como protocolo de comunicação padrão. Execute o lilo para gerar novamente o setor de inicialização com as modificações e reinicie o computador.
OBS: Cuidado ao colocar um disco rígido IDE como hdc! A linha hdc=ide-scsi deverá ser retirada, caso contrário, seu disco rígido não será detectado.
Agora, siga até [#s-hardw-cfgdisp-cdwritter-teste Testando o funcionamento, Seção 3.11.3.3].
Caso tenha um autentico gravador SCSI, não será preciso fazer qualquer configuração de emulação, a unidade estará pronta para ser usada, desde que seu suporte esteja no kernel. As seguintes opções do kernel são necessárias para funcionamento de gravadores SCSI:
Depois em "SCSI support" marque as opções:
* SCSI support
M SCSI CD-ROM Support
M SCSI Generic Support
Além disso, deve ser adicionado o suporte EMBUTIDO no kernel a sua controladora SCSI. Se o seu disco rígido também é SCSI, e seu CD está ligado na mesma controladora SCSI, ela já está funcionando e você poderá seguir para o passo [#s-hardw-cfgdisp-cdwritter-teste Testando o funcionamento, Seção 3.11.3.3]. Caso contrário carregue o suporte da sua placa adaptadora SCSI antes de seguir para este passo.
Para testar se o seu gravador, instale o pacote wodim e execute o comando: wodim -scanbus para verificar se sua unidade de CD-ROM é detectada.
Você deverá ver uma linha como:
O que significa que sua unidade foi reconhecida perfeitamente pelo sistema e já pode ser usada para gravação. Vá até a seção [ch-tasks.html#s-tasks-cdwriting Gravando CDs e DVDs no Linux, Seção 24.1] para aprender como gravar CDs no Linux. Note que gravadores IDE nativos, não são listados com esse comando.
Configurando o gerenciamento de energia usando o APM
O APM (Advanced Power Management - Gerenciamento Avançado de Energia) permite que sistemas gerenciem características relacionadas com o uso e consumo de energia do computador. Ele opera a nível de BIOS e tenta reduzir o consumo de energia de várias formas quando o sistema não estiver em uso (como reduzindo o clock da CPU, desligar o HD, desligar o monitor, etc.).
O uso de advanced power management também permite que computadores com fonte de alimentação ATX sejam desligados automaticamente quando você executa o comando halt. Caso sua máquina tenha suporte a ACPI, este deverá ser usado como preferência ao invés do APM por ter recursos mais sofisticados (veja [#s-hardw-cfgdisp-acpi Configurando o gerenciamento de energia usando ACPI, Seção 3.11.5]).
Para ativar o suporte a APM no Linux, compile seu kernel com o suporte embutido a APM e também a "Advanced Power Management" (senão sua máquina não desligará sozinha no halt). Caso deseje compilar como módulo, basta depois carregar o módulo apm adicionando no arquivo /etc/modules. Depois disso instale o daemon apmd para gerenciar as características deste recurso no sistema.
Você pode desativar o uso de APM de 3 formas: removendo seu suporte do kernel, passando o argumento apm=off (quando compilado estaticamente no kernel) ou removendo o nome do módulo do arquivo /etc/modules (quando compilado como módulo). Depois disso remova o daemon apmd.
Configurando o gerenciamento de energia usando ACPI
O ACPI (Advanced Configuration and Power Interface - Interface de Configuração e Gerenciamento de Energia Avançado) é uma camada de gerenciamento de energia que opera a nível de sistema operacional. Apresenta os mesmos recursos que o APM, e outros como o desligamento da máquina por teclas especiais de teclado, controle de brilho e contraste de notebooks, suspend para RAM, suspend para disco, redução de velocidade de CPU manualmente, monitoramento de periféricos, temperatura, hardwares, etc.
Desta forma, o ACPI varia de sistema para sistema em questões relacionadas com suporte a recursos especiais, estes dados são armazenados em tabelas chamadas DSDT. O Linux inclui suporte a recursos ACPI genéricos entre placas mãe, recursos específicos devem ser extraídos diretamente da BIOS e disassemblados manualmente para a construção de um kernel com suporte específico a tabela DSDT do hardware (não falarei das formas de se fazer disso aqui, somente do suporte genérico).
Quanto mais nova a versão do kernel, maiores as chances do seu hardware ser suportado plenamente pelo ACPI, principalmente no caso de notebooks. Para compilar estaticamente, marque com Y a opção ACPI, depois marque os módulos que você quer que ele monitore: button (botão power), fan (ventoinhas), etc. Se compilou como módulo, adicione o nome do módulo acpi no arquivo /etc/modules. Não há problema em compilar também o suporte a APM, pois não causará problemas com um kernel com ACPI também compilado.
Caso não saiba quais módulos ACPI seu sistema aceita, marque o suporte a todos e carregue-os. Após isto, entre no diretório /proc/acpi e de um ls entrando nos diretórios e vendo se existem arquivos dentro deles. Remova o módulo correspondente daqueles que não tiver conteúdo.
Após isto, instale o daemon acpid e configure-o para monitorar algumas características do seu sistema. Por padrão o acpid monitora o botão POWER, assim se você pressionar o power, seu sistema entrará automaticamente em run-level 0, fechando todos os processos e desligando sua máquina.
O suporte a ACPI pode ser desativado de 3 formas: Removendo seu suporte do kernel, passando o argumento acpi=off ao kernel (caso esteja compilado estaticamente) ou removendo o módulo de /etc/modules (caso tenha compilado como módulo. Após isto, remova o daemon acpid do seu sistema.
Algumas placas mãe ATX possuem suporte a este interessante recurso, que permite que sua máquina seja ligada através de uma rede. Isto é feito enviando-se uma sequência especial de pacotes diretamente para o MAC (endereço físico) da placa de rede usando um programa especial.
Para usar este recurso, seu sistema deverá ter as seguintes características:
Placa mãe ATX
Fonte de alimentação ATX compatível com o padrão 2.0, com fornecimento de pelo menos 720ma de corrente na saída 3v.
Placa de rede com suporte a WakeUP-on-Lan (WOL), você poderá confirmar isto vendo um conector branco de 3 terminais instalado na placa que é o local onde o cabo wake-up é conectado.
Suporte na BIOS também deverá ter a opção para WakeUP-on-Lan.
Com todos esses ítens existentes, instale em uma máquina da rede o pacote etherwake. Depois disso, pegue o MAC address a placa de rede da máquina que tem o wakeup on lan e na máquina da rede onde instalou o pacote execute o seguinte comando:
ether-wake AA:BB:CC:DD:EE:FF
Onde AA:BB:CC:DD:EE:FF é o endereço MAC da placa de rede. A máquina deverá ligar e realizar o procedimento padrão de POST normalmente.
Algumas das situações onde o WOL não funciona é quando sua rede é controlada por Switches (devido a natureza de funcionamento deste equipamentos) ou caso esteja atrás de um roteador que não faz proxy arp.
Pode acontecer que um dispositivo tenha um programa de instalação para Linux, mas este programa pode não estar corretamente costumerizado. Neste caso, é possível que após os comandos de construção do módulo, normalmente:
./configure
make
make install
o módulo compilado não seja usado, e o sistema esteja ainda utilizando uma versão antiga e errada do módulo. Para verificar isto, usar a função [[../../Kernel e módulos/modinfo/]] junto com a função [[../../Como obter ajuda no sistema/locate/]]:
modinfo nome-do-módulo # mostra onde está o módulo instalado
locate nome-do-módulo # mostra se existem outras versões
Este capítulo explica as diferenças e particularidades do sistema GNU/Linux comparado ao Windows, DOS e uma lista de equivalência entre comandos e programas executados no CMD do Windows/DOS e GNU/Linux, que pode servir de comparação para que o usuário possa conhecer e utilizar os comandos/programas GNU/Linux que tem a mesma função no ambiente DOS/Windows.
Quando entrar pela primeira vez no GNU/Linux (ou qualquer outro UNIX, a primeira coisa que verá será a palavra login: escrita na tela.
A sua aventura começa aqui, você deve ser uma pessoa cadastrada no sistema (ter uma conta) para que poder entrar. No login você digita seu nome (por exemplo, gleydson) e pressiona Enter. Agora será lhe pedida a senha, repare que a senha não é mostrada enquanto é digitada, isto serve de segurança e para enganar pessoas que estão próximas de você "tocando" algumas teclas a mais enquanto digita a senha e fazendo-as pensar que você usa uma grande senha ;-) (com os asteriscos aparecendo isto não seria possível).
Caso cometa erros durante a digitação da senha, basta pressionar a tecla Back Space para apagar o último caracter digitado e terminar a entrada da senha.
Pressione Enter, se tudo ocorrer bem você estará dentro do sistema e será presenteado com o símbolo # (caso tenha entrado como usuário root) ou $ (caso tenha entrado como um usuário normal).
Existe um mecanismo de segurança que te alerta sobre eventuais tentativas de entrada no sistema por intrusos usando seu login, faça um teste: entre com seu login e digite a senha errada, na segunda vez entre com a senha correta no sistema. Na penúltima linha das mensagens aparece uma mensagem "1 failure since last login", o que quer dizer "1 falha desde o último login". Isto significa que alguém tentou entrar 1 vez com seu nome e senha no sistema, sem sucesso.
A conta root não tem restrições de acesso ao sistema e pode fazer tudo o que quiser, é equivalente ao usuário normal do DOS e Windows. Use a conta root somente para manutenções no sistema e instalação de programas, qualquer movimento errado pode comprometer todo o sistema. Para detalhes veja [ch-perm.html#s-perm-root A conta root, Seção 13.6].
No GNU/Linux os diretório são identificados por uma / e não por uma \ como acontece no DOS. Para entrar no diretório /bin, você deve usar cd /bin.
Os comandos são case-sensitive, o que significa que ele diferencia as letras maiúsculas de minúsculas em arquivos e diretórios. O comando ls e LS são completamente diferentes.
A multitarefa lhe permite usar vários programas simultaneamente (não pense que multitarefa somente funciona em ambientes gráficos, pois isto é errado!). Para detalhes veja [ch-run.html Execução de programas, Capítulo 7].
Os dispositivos também são identificados e uma forma diferente que no DOS por exemplo:
Os recursos multiusuário lhe permite acessar o sistema de qualquer lugar sem instalar nenhum driver, ou programa gigante, apenas através de conexões TCP/IP, como a Internet. Também é possível acessar o sistema localmente com vários usuários (cada um executando tarefas completamente independente dos outros) através dos Terminais Virtuais. Faça um teste: pressione ao mesmo tempo a tecla ALT e F2 e você será levado para o segundo Terminal Virtual, pressione novamente ALT e F1 para retornar ao anterior.
Para reiniciar o computador, você pode pressionar CTRL ALT DEL (como usuário root) ou digitar shutdown -r now. Veja [ch-intro.html#s-introducao-reiniciando Reiniciando o computador, Seção 1.17] para detalhes .
Para desligar o computador, digite shutdown -h now e espere o aparecimento da mensagem Power Down para apertar o botão LIGA/DESLIGA do computador. Veja [ch-intro.html#s-introducao-desligando Desligando o computador, Seção 1.16] para detalhes.
Comandos equivalentes entre DOS/CMD do Windows e o Linux
Esta seção contém os comandos equivalentes entre estes dois sistemas e a avaliação entre ambos. Grande parte dos comandos podem ser usados da mesma forma que no DOS, mas os comandos Linux possuem avanços para utilização neste ambiente multiusuário/multitarefa.
O objetivo desta seção é permitir as pessoas com experiência em DOS fazer rapidamente no GNU/Linux as tarefas que fazem no DOS. A primeira coluna tem o nome do comando no DOS, a segunda o comando que possui a mesma função no GNU/Linux e na terceira coluna as diferenças.
DOS Linux Diferenças
-------- ------------ --------------------------------------------------
cls clear Sem diferenças.
dir ls -la A listagem no Linux possui mais campos (as
permissões de acesso) e o total de espaço ocupado
no diretório e livre no disco deve ser visto
separadamente usando o comando du e df.
Permite também listar o conteúdo de diversos
diretórios com um só comando (ls /bin /sbin /...).
dir/s ls -lR Sem diferenças.
dir/od ls -tr Sem diferenças.
cd cd Poucas diferenças. cd sem parâmetros retorna ao
diretório de usuário e também permite o uso
de "cd -" para retornar ao diretório anteriormente
acessado.
del rm Poucas diferenças. O rm do Linux permite
especificar diversos arquivos que serão apagados
(rm arquivo1 arquivo2 arquivo3). Para ser mostrados
os arquivos apagados, deve-se especificar o
parâmetro "-v" ao comando, e "-i" para pedir
a confirmação ao apagar arquivos.
md mkdir Uma só diferença: No Linux permite que vários
diretórios sejam criados de uma só vez
(mkdir /tmp/a /tmp/b...).
copy cp Poucas diferenças. Para ser mostrados os arquivos
enquanto estão sendo copiados, deve-se usar a
opção "-v", e para que ele pergunte se deseja
substituir um arquivo já existente, deve-se usar
a opção "-i".
echo echo Sem diferenças.
path path No Linux deve ser usado ":" para separar os
diretórios e usar o comando
"export PATH=caminho1:/caminho2:/caminho3:"
para definir a variável de ambiente PATH.
O path atual pode ser visualizado através
do comando "echo $PATH".
ren mv Poucas diferenças. No Linux não é possível
renomear vários arquivos de uma só vez
(como "ren *.txt *.bak"). É necessário usar
um shell script para fazer isto.
type cat Sem diferenças.
ver uname -a Poucas diferenças (o uname tem algumas opções
a mais).
date date No Linux mostra/modifica a Data e Hora do sistema.
time date No Linux mostra/modifica a Data e Hora do sistema.
attrib chmod O chmod possui mais opções por tratar as permissões
de acesso de leitura, gravação e execução para
donos, grupos e outros usuários.
chkdsk fsck.ext2 O fsck é mais rápido e a checagem mais abrangente.
scandisk fsck.ext2 O fsck é mais rápido e a checagem mais abrangente.
doskey ----- A memorização de comandos é feita automaticamente pelo
bash.
edit vi, ae, O edit é mais fácil de usar, mas usuários
emacs, mcedit, experientes apreciarão os recursos do vi ou
nano, pico, joe o emacs (programado em lisp).
fdisk fdisk, cfdisk Os particionadores do Linux trabalham com
praticamente todos os tipos de partições de
diversos sistemas de arquivos diferentes.
format mkfs.ext2 Poucas diferenças, precisa apenas que seja
especificado o dispositivo a ser formatado
como "/dev/fd0" ou "/dev/hda10" (o
tipo de identificação usada no Linux), ao
invés de "A:" ou "C:".
help man, info Sem diferenças.
interlnk plip O plip do Linux permite que sejam montadas
redes reais a partir de uma conexão via Cabo
Paralelo ou Serial. A máquina pode fazer tudo
o que poderia fazer conectada em uma rede
(na realidade é uma rede e usa o TCP/IP como
protocolo) inclusive navegar na Internet, enviar
e-mails, irc, etc.
intersvr plip Mesmo que o acima.
keyb loadkeys Sem diferenças (somente que a posição das
teclas do teclado pode ser editada.
Desnecessário para a maioria dos usuários).
label e2label É necessário especificar a partição que terá
o nome modificado.
mem cat /proc/meminfo Mostra detalhes sobre a quantidade de dados
top em buffers, cache e memória virtual (disco).
more more, less O more é equivalente a ambos os sistemas, mas
o less permite que sejam usadas as setas para
cima e para baixo, o que torna a leitura do
texto muito mais agradável.
move mv Poucas diferenças. Para ser mostrados os arquivos
enquanto estão sendo movidos, deve-se usar a
opção "-v", e para que ele pergunte se deseja
substituir um arquivo já existente deve-se usar
a opção "-i".
scan ----- Não existem vírus no Linux devido as
restrições do usuário durante execução de
programas.
backup tar O tar permite o uso de compactação (através do
parâmetro -z) e tem um melhor esquema de
recuperação de arquivos corrompidos que já
segue evoluindo há 30 anos em sistemas UNIX.
print lpr O lpr é mais rápido e permite até mesmo
impressões de gráficos ou arquivos compactados
diretamente caso seja usado o programa
magicfilter. É o programa de Spool de
impressoras usados no sistema Linux/Unix.
vol e2label Sem diferenças.
xcopy cp -R Pouca diferença, requer que seja usado a
opção "-v" para mostrar os arquivos que
estão sendo copiados e "-i" para pedir
confirmação de substituição de arquivos.
Os arquivos config.sys e autoexec.bat são equivalentes aos arquivos do diretório /etc especialmente o /etc/inittab e arquivos dentro do diretório /etc/init.d .
Você pode usar os comandos do pacote mtools para simular os comandos usados pelo DOS no GNU/Linux, a diferença básica é que eles terão a letra m no inicio do nome. Os seguintes comandos são suportados:
mattrib - Ajusta modifica atributos de arquivos
mcat - Mostra os dados da unidade de disquete em formato RAW
mcd - Entra em diretórios
mcopy - Copia arquivos/diretórios
mdel - Exclui arquivos
mdeltree - Exclui arquivos, diretórios e sub-diretórios
mdir - Lista arquivos e diretórios
mdu - Mostra o espaço ocupado pelo diretório do DOS
mformat - Formatador de discos
minfo - Mostra detalhes sobre a unidade de disquetes
mlabel - Cria um volume para unidades DOS
mmd - Cria diretórios
mmount - Monta discos DOS
mmove - Move ou renomeia arquivos/subdiretórios
mpartition - Particiona um disco para ser usado no DOS
mrd - Remove um diretório
mren - Renomeia arquivos
mtype - Visualiza o conteúdo de arquivos (equivalente ao cat)
mtoolstest - Exibe a configuração atual do mtools
mshowfat - Mostra a FAT da unidade
mbadblocks - Procura por setores defeituosos na unidade
mzip - Altera modo de proteção e ejeta discos em unidades Jaz/ZIP
mkmanifest - Cria um shell script para restaurar nomes extensos usados no UNIX
mcheck - Verifica arquivos na unidade
Programas equivalentes entre Windows/DOS e o Linux
Esta seção contém programas equivalentes para quem está vindo do DOS e Windows e não sabe o que usar no GNU/Linux. Esta seção também tem por objetivo permitir ao usuário que ainda não usa GNU/Linux decidir se a passagem vale a pena, vendo se o sistema tem os programas que precisa. Lembre-se que a instalação desses programas variará de acordo com a distribuição GNU/Linux que você estiver usando.
Note que esta listagem mostra os programas equivalentes entre o DOS/Windows e o GNU/Linux cabendo a você a decisão final de migrar ou não. Lembrando que é possível usar o Windows, OS/2, DOS, OS/2 e GNU/Linux no mesmo disco rígido sem qualquer tipo de conflito. A listagem abaixo provavelmente está incompleta, portanto, se encontrar algum programa que não esteja listado aqui, por favor adicione referenciando.
Essa sessão é especialmente dedicada a quem quer migrar do DOS para o GNU/Linux; e também auxiliar a quem deseja manter-se utilizando mais a linha de comando em detrimento da interface gráfica.
Visto que servidores GNU/Linux geralmente não possuem interface gráfica disponível para uso do sys/admin, é interessante ter à disposição programas que façam as mesmas tarefas que seriam feitas através da interface gráfica.
Lembrando que o sistema GNU/Linux fez uma evolução gradual e independente, tanto de seu terminal de comandos quanto de sua interface gráfica, resultando em ambos os ambientes serem bastante poderosos.
E se por acaso você não encontrou um programa com exatamente as mesmas características de um que usa no DOS, é sempre possível executar o programa original via DOSBOX (uma camada de compatibilidade para jogos, mas que roda vários programas também) ou FreeDOS (uma implementação livre do próprio DOS, o que exige um pouco mais da máquina), que com uma layer adicional (DOSEMU) é executado inteiro sobre o Linux, embora seja preferível encontrar o programa nativo do pinguim.
DOSLinuxDiferenças
----------- ---------- -----------------------------------------------
MinEd, MEdit vim, emacs, O GNU/Linux possui várias opções de
nano, joe, editores de texto em modo texto.
mcedit, LateX vim e emacs são para usuários avançados
Os demais são mais amigáveis. LateX
é um sistema de macros para formatação
de texto; use com qualquer desses outros
editores de texto acima mencionados. ;)
VisiCalc, oleo, Planilhas eletrônicas em modo texto.
Lotus1-2-3 sc-im,
teapot
Sem equivalente Impressive Apresentação de slides
em modo texto.
Sem equivalente poppler-utils, Ferramentas de manipulação
less, fbgs de arquivos pdf. Usando
pdftohtml ou pdftotext
(do poppler-utils)
é possível extrair o
conteúdo do pdf para ser
lido no navegador web CLI.
Ou usando less é possível
ler o arquivo pdf, desde que
não sejam imagens. Se for
necessário ler PDFs com imagens,
há a opção do pacote fbi, o
programa fbgs (um wraper), através
do uso do framebuffer (precisa ter
direitos de acesso de root).
O GNU/Linux tem capacidade para lidar com incontáveis protocolos de comunicação, proprietários ou livres. Geralmente a dificuldade encontrada pelos usuários em utilizar alguns desses protocolos reside no fato de tais serem protocolos controlados por empresas que desejam monopolizar essa comunicação através de seus próprios comunicadores de código-fonte fechado. É o caso clássico do MSN, que ao longo de sua história mudou seu protocolo inúmeras vezes, prejudicando os usuários de comunicadores livres. Recentemente tem ocorrido algo parecido (mas não tão icônico) com Google Talk e facebook messenger.
DOSLinuxDiferenças
----------- ---------- -----------------------------------------------
Arachne Links2, Lynx Links2 é um navegador "gráfico"
links, elinks que funciona mesmo em sistemas
sem interface gráfica,
extremamente rápido, com capacidade
de exibir as imagens. Lynx consegue
exibir as páginas mais próximas de sua
forma visual nos navegadores gráficos,
mesmo muitas páginas em javascript.
MSN pebrot, finch clientes modo texto para
o protocolo MSN.
Bate-Papo talk, ytalk O talk e o ytalk permite a
conversa de dois usuários não
só através de uma rede local,
mas de qualquer parte do
planeta, pois usa o protocolo
tcp/ip para comunicação. Muito
útil e fácil de usar (modo texto).
leetIRC, Weechat, Clientes modo texto
Toffee MCabber, para o protocolo IRC.
XBitch,
irssi.
hang-outs chat MCabber Cliente modo texto para o
(da Google) protocolo de msg instantânea
da google.
torrent transmission-cli Cliente CLI para
download de
bit-torrent
DOSLinuxDiferenças
----------- ---------- -----------------------------------------------
Grafx2 Grafx2, Editor de bitmap.
PictureViewer ImageMagick, O ImageMagick é um "canivete suíço"
fbi não-interativo para imagens, capaz
de realizar ações em lotes, o que
facilita tratamento de grandes
quantidades de imagens.
"linux framebuffer imageviewer"
(fbi) não precisa de uma interface
gráfica rodando para mostrar
as imagens em um terminal
"puro".
GNU Screen, Salvar uma imagem da tela atual.
ImageMagick
mpxplay, mocp, orpheus, Players CLI de música.
OpenCubicPlayer open cubic player mocp segue o visual do
mplayer, cvlc, famoso gerenciador de
cmus arquivos mc.
QuickView mplayer Video player CLI.
mplayer não necessita
de um servidor gráfico
para rodar vídeos,
fazendo-o através do
directframebuffer.
DVD4DOS mplayer Player de DVDs.
Cdrtools Cdrtools/Cdrkit Uma coleção de projetos independentes
de softwares livres/open source para
queimar/regravar CDs, DVDs, Blue-Rays,
ripador de CDs, gerador de imagens ISO
prontas para serem gravadas.
Burncenter Queimador de CDs/DVDs.
Front-end em CLI para Cdrtools/Cdrkit.
mixer alsamixer Controlador de som
CLI escrito em curses.
DOSBOX, Ambos funcionam sobre o Linux,
DOSEMU+FREEDOS funcionando, porém, muito
diferentemente um do outro.
DOSBOX foi pensado especificamente
para jogos, porém roda uma
quantidade razoável de programas.
DOSEMU+FREEDOS é o próprio DOS
(FreeDOS) rodando no Linux sobre uma
camada de compatibilidade
(DOSEMU).
Wine Wine é uma camada que redireciona as requisições
feitas pelos programas Windows para as bibliotecas
nativas do Linux (não sendo, portanto, na prática,
um emulador). Tem uma gama gigantesca de programas
que funcionam a contento. É sempre preferível que
se utilize programas nativos.
zsnes zsnes, snes9x Emuladores de Super Nintendo.
zsnes não foi ainda portado
para a plataforma x86_64.
Genecyst, KGen BlastEM, Gens Emuladores de Mega drive/Sega Genesis.
Genesis Plus
Master System Mednafen Emulador de Atari Lynx, NES, SNES,
Virtual Boy, Game Boy,
Game Boy Color, Game Boy Advance,
Master System, Sega Game Gear,
Sega Genesis, PlayStation,
Neo Geo Pocket, Neo Geo Pocket Color,
WonderSwan, TurboGrafx-16
(TurboGrafx-CD), SuperGrafx, PC-FX
1964js, N64js 1964js, N64js Emuladores de Nintendo 64
em javascript.
O GNU/Linux é um sistema criado POR programadores PARA programadores. Invariavelmente qualquer distribuição Linux trará consigo uma gama já respeitável de linguagens de programação pré-instaladas, tais como python, tcl e perl, além da própria linguagem do shell _ geralmente o bash _ com um enorme poder de aproveitamento da capacidade do sistema.
DOSLinuxDiferenças
----------- ---------- -----------------------------------------------
vim vim, emacs IDE's com coloração de sintaxe.
WBAT dialog Caixas de diálogos para scripts.
O dialog tem inúmeras opções
e acabou servindo de base para
vários sucessores gráficos.
qbasic, FreeBasic FreeBasic possui orientação a objetos
quickbasic e continua em desenvolvimento, com acesso
direto a várias bibliotecas importantes
(como GTK+, GSL, SDL, Allegro, Lua e OpenGL).
DOSLinuxDiferenças
----------- ---------- -----------------------------------------------
Agente de cron Pouca diferença. O cron
Sistema dá mais liberdade na programação
de tarefas a serem executadas
pelo Linux.
EZ-NOS 2, Apache O Apache é o servidor WEB mais
Sioux, usado no mundo (algo em torno
(web server) de 75% das empresas), muito
rápido e flexível de se
configurar.
Squid, Apache, A migração de um servidor
ip masquerade, proxy para Linux requer
nat, diald, o uso de vários programas
exim separados para que se tenha
um resultado profissional.
Isto pode parecer incomodo
no começo, mas você logo
perceberá que a divisão
de serviços entre programas
é mais produtivo. Quando
desejar substituir um
deles, o funcionamento dos
outros não serão afetados.
Não vou entrar em detalhes
sobre os
programas citados ao lado,
mas o squid é um servidor
proxy Web (HTTP e HTTPS)
completo e também apresenta
um excelente serviço FTP.
Possui outros módulos como
dns, ping, restrições de
acesso, limites de tamanho
de arquivos, cache, etc.
zope, Sem comentários... todas são
php, wdm, ferramentas para a geração
htdig de grandes Web Sites. O wdm,
por exemplo, é usado na geração
do site da distribuição Debian
(http://www.debian.org) em 30
idiomas diferentes.
RockIRCd ircd-ratbox IRC server.
NetBIOS Sem equivalente O Linux tem suporte nativo a
tcp/ip desde o começo de sua
existência e não precisa de
nenhuma camada de comunicação
entre ele e a Internet. A
performance é aproximadamente
10% maior em conexões Internet
via fax-modem e outras redes
tcp/ip.
AVG, Viruscan, Clamavis, AVG Os maiores fabricantes de
norton, F-PROT, F-Prot, ViruScan anti-virus disponibilizam
CPAV. versões para Linux, com o
objetivo principal de
remoção de vírus em
servidores de E-mail ou
servidores de arquivos,
com o objetivo de não
contaminar os vulneráveis
sistemas Windows, servindo
como uma efetiva barreira
de defesa na rede.
DOSLinuxDiferenças
----------- ---------- -----------------------------------------------
OpenGEM, jwm, twm Opções de interface
Ozone fluxbox, gráfica para o pinguim
blackbox, é o que não falta:
lxde, xfce, desde ambientes
openbox, extremamente leves (jwm, twm)
KDE, Gnome, que dão basicamente um
e muitas gerenciador de janelas,
outras. até monstros que quase
substituem o próprio
sistema operacional
como KDE & Gnome.
Sem XWindow System, A interface gráfica
equivalente XFree86 no GNU/Linux funciona
X.org geralmente sobre um
Wayland, software com funcionamento
Mir. do tipo cliente-servidor
(um programa separado do sistema),
o que facilita muito utilizar
o Desktop através de uma rede.
Com as exceções recentes
do Ubuntu (que utiliza o
Mir), e o Fedora WorkStation
(que utiliza Wayland), as
distribuições em geral
ainda utilizam o X como
servidor gráfico, o mais
antigo ainda em uso.
Diferentemente do GNU/Linux, o Windows não fez uma evolução independente do terminal e da interface gráfica, sendo a linha de comando no Windows comparativamente bastante rudimentar. Se você se interessar em softwares de linha de comando para trabalhar no Linux com tarefas que faria em interface gráfica no Windows, veja a sessão acima Migrando de DOS para GNU/Linux
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
MS Word Open OfficeWriter (OpenOffice ou LibreOffice)
LibreOffice possue todos os recursos do Word
Abiword além de ter a interface gráfica
Calligra Words semelhante, menus e muitas teclas
de atalho idênticas ao Word, o
que facilita a migração.
Também trabalha com arquivos no
formato Word97/2000 e não é
vulnerável a vírus de macro. É
distribuído gratuitamente e não
requer pagamento de licença
podendo ser instalado em quantos
computadores você quiser (tanto
domésticos como de empresas).
Opção adicional mais leve é o
Abiword.
O desktop KDE possue a
opção de office Calligra Words.
MS Excel Open Office Calc: Mesmos pontos do
LibreOffice acima e também abre
Calligra Sheets arquivos Excel97/2000.
Gnumeric Gnumeric é uma opção
relativamente mais leve.
MS PowerPoint Open Office Impress: Mesmos pontos do acima.
LibreOffice
Calligra Stage
MS Access MySQL, PostgreSQL Existem diversas ferramentas de
Oracle, Base, gsql conceito para bancos de dados
corporativos no Linux. Todos
produtos compatíveis com outras
plataformas.
MS Outlook Evolution, Centenas de programas de E-Mail
sylpheed, Instale, avalie e escolha.
icedove,
ThunderbirdKMail
e muitos outros.
Babylon GoldenDict Tradutor capaz de utilizar
os arquivos de dicionários
do Babylon.
SAP AG Compiere Gestão empresarial (ERP).
FreedomERP Usar software livre nesse setor tão
Openbravo importante faz a empresa permanecer
Odoo autônoma. Se o desenvolvedor não satisfaz
Stoq as necessidades da empresa, o empresário
WebERP não entra em apuros: o código fonte está
disponível, bastando contratar outro
desenvolvedor.
winzip file-roller, Análogos. Com as extensões
xarchiver, opcionais o file-roller e Ark
Ark podem descompactar dezenas
e dezenas de formatos de
arquivos comprimidos.
MS Windows Explorer Konqueror Todos com funções
Krusader semelhantes, uns com foco em
Dolphin ser amigável (PCManFM/Dolphin/Nautilus),
Nautilus outros com foco em recursos
Thunar adicionais (Konqueror).
PCManFM PCManFM é extremamente leve.
Krusader carrega
o conceito do mc para o
ambiente KDE.
O GNU/Linux tem capacidade para lidar com incontáveis protocolos de comunicação, proprietários ou livres. Geralmente a dificuldade encontrada pelos usuários em utilizar alguns desses protocolos reside no fato de tais serem protocolos controlados por empresas que desejam monopolizar essa comunicação através de seus próprios comunicadores de código-fonte fechado. É o caso clássico do MSN, que ao longo de sua história mudou seu protocolo inúmeras vezes, prejudicando os usuários de comunicadores livres. Recentemente tem ocorrido algo parecido (mas não tão icônico) com Google Talk e facebook messenger.
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
MS Internet Explorer Firefox, Opera, Firefox e seu fork, IceCat/Iceweasel
Google Chrome Chromium, IceCat, possuem incontáveis plugins,
Midori extremamente poderosos.
Chromium é a versão livre do navegador
da Google.
Midori é um navegador leve.
Skype Skype, Telefonia por VoIP.
Qutecom,
Mumble,
KPhone,
Jitsi e
muitos
outros.
facebook messenger facebook messenger messenger livre para o protocolo
de mensagens instantâneas do
facebook.
MSN aMSN, Pidgin Permite conversar diretamente com
Kopete, Empathy, usuários do Microsoft MSN. O Pidgin
emesene é multiprotocolo: facebook, MSN, IRC, etc
ICQ LICQ, Pidgin, SIM, Muito prático e fácil de
Kopete operar. Possibilita a
mudança completa da
aparência do programa
através de Skins. A
organização dos menus
deste programa é outro
ponto de destaque.
Bate-Papo talk, ytalk O talk e o ytalk permite a
conversa de dois usuários não
só através de uma rede local,
mas de qualquer parte do
planeta, pois usa o protocolo
tcp/ip para comunicação. Muito
útil e fácil de usar (modo texto).
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
Photo Shop, Gimp, Gimp é fácil de usar, possui
Corel Photo Paint Darktable muitos scripts que permitem
Krita a criação rápida e fácil de
qualquer tipo de efeito
profissional pelo usuário
mais leigo. Acompanha centenas
de efeitos especiais e um
belo manual em html com muitas
fotos (aproximadamente 20MB) que
mostra o que é possível se fazer
com ele.
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
winamp xmms2, Players para todos os gostos;
audacious, teste até descobrir o que melhor lhe
Amarok, satisfaz. xmms2 e audacious são
Exaile, relativamente independentes de ambiente.
Rhythmbox e Amarok é dependente do ambiente KDE;
muitos outros o Exaile e o Rhythmbox das
bibliotecas GTK+.
media player SMPlayer, playmidi Programas para execução de
xwave, VLC, xine, arquivos de música e vídeos
Kodi multimídia. Existem outras
alternativas, a escolha
depende do seu gosto e da
sofisticação do programa.
Kodi (anterior XBMC) é uma
central de entretenimento
completa.
'ripador' de DVDs K9Copy, Conversores de DVD.
HandBrake,
acidrip,
dvdrip.
Nero k3b, Xfburn, k3b é um gravador de
Brasero, GnomeBaker, midias completo. Os demais são
X-CD-Roast front-end mais simples, para
usos menos exigentes.
Windows DVD Maker DeVeDe, Autoração de DVDs.
Bombono,
DVDStyler.
Adobe After Effects KdenLive, Edição de Vídeos.
Windows Movie Maker Natron, Natron equivale mais ao
Cinelerra, After Effects e o
Blender, OpenShot ao MovieMaker.
OpenShot.
piTiVi
DOSBOX DOSBOX, Ambos funcionam sobre
DOSEMU+FREEDOS o Linux, porém, muito
diferentemente um do outro.
DOSBOX foi pensado especificamente
para jogos, porém roda uma
quantidade razoável de programas.
DOSEMU+FREEDOS é o próprio DOS (FreeDOS)
rodando no Linux sobre uma
camada de compatibilidade
(DOSEMU).
Wine Wine é uma camada que redireciona as requisições
feitas pelos programas Windows para as bibliotecas
nativas do Linux (não sendo, portanto, na prática,
um emulador). Tem uma gama gigantesca de programas
que funcionam a contento. É sempre preferível que
se utilize programas nativos.
zsnes zsnes, snes9x Emuladores de Super Nintendo.
zsnes não foi ainda portado
para a plataforma x86_64.
Genecyst, KGen BlastEM, Gens Emuladores de Mega drive/Sega Genesis.
Mednafen Emulador de Atari Lynx, NES, SNES,
Virtual Boy, Game Boy,
Game Boy Color, Game Boy Advance,
Master System, Sega Game Gear,
Sega Genesis, PlayStation,
Neo Geo Pocket, Neo Geo Pocket Color,
WonderSwan, TurboGrafx-16
(TurboGrafx-CD), SuperGrafx, PC-FX
1964js, N64js 1964js, N64js Emuladores de Nintendo 64
em javascript.
Dolphin Dolphin Emulador de GameCube.
NO$GBA VisualBoyAdvance Emulador de GBA.
NO$GBA DesMUME Emulador de DS.
PCSX, ePSXe PCSX, PSX, ePSXe, Emuladores de PlayStation One.
PCSX-R
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
Origin QtiPlot, O projeto QtiPlot se inspirou no
SciDAVis Origin e cumpre perfeitamente as
LabPlot tarefas com a mesma simplicidade.
LabPlot roda no ambiente KDE.
ArcGIS QGIS, GRASS, O QGIS possui uma interface
SPRING amigável, é completo e
possui incontáveis plugins
para aumentar ainda mais
sua funcionalidade.
R R Idênticos. No Linux, pode ser adicionado R-cmdr, uma
rica interface gráfica, com capacidade de
criação de gráficos.
O GNU/Linux é um sistema criado POR programadores PARA programadores. Invariavelmente qualquer distribuição Linux trará consigo uma gama já respeitável de linguagens de programação pré-instaladas, tais como python, tcl e perl, além da própria linguagem do shell _ geralmente o bash _ com um enorme poder de aproveitamento da capacidade do sistema. Um programador que faça uso de RADs gráficos também não ficará desamparado trabalhando no pinguim. ;)
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
Visual Basic Gambas RAD para softwares em BASIC.
Não é compatível com código VB, porém
implementa melhorias conceituais
de legibilidade de projeto, já
que separa completamente a GUI e
o back-end. Se propoem, porém, a
ser fácil na tradução de programas
VB para ele. Com orientação a
objetos, foi completamente
re-escrito e compilado usando o
próprio Gambas. ;)
DevC++ Geany, Anjuta, Equivalentes. Todos com capacidade
gedit, Kate de extensão através de plugins. O
último para ambiente KDE.
Qt Creator Qt Creator Um RAD multiplataforma para C/C++.
Sem equivalente KDevelop Um RAD excelente para o ambiente
de desktop KDE. Depende das
bibliotecas qt.
Glade Glade Um construtor de interfaces para
praticamente qualquer linguagem.
As GUI criadas dependem das
bibliotecas Gtk+ instaladas.
Delphi Lazarus Excelente RAD para o compilador
Free Pascal. Compatível com
código Delphi.
Eclipse Eclipse RAD para programação em Java +
incontáveis linguagens, a se
contar com as possibilidades
dadas através de plugins.
VBScript kdialog, Caixas de diálogo
zenity, para serem utilizadas
whiptail com shell scripts.
Muito ricas em opções
e simples de se usar.
Adobe Dreamweaver BlueGriffon Todos eles são
Kompozer (antigo NVU), editores HTML WYSIWYG.
Seamonkey (fork do Mozilla),
Bluefish, LibreOffice
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
Agente de cron Pouca diferença. O cron
Sistema dá mais liberdade na programação
de tarefas a serem executadas
pelo Linux.
IIS, Pers. Apache O Apache é o servidor WEB mais
Web Server usado no mundo (algo em torno
de 75% das empresas), muito
rápido e flexível de se
configurar.
Exchange, Postfix, Sendmail 72% da base de servidores de
NT Mail Exim, Qmail emails no mundo atualmente
roda em software livre. Os
mais recomendados são o
Postfix e o qmail, devido a
segurança, velocidade e
integridade de mensagem.
Wingate, Squid, Apache, A migração de um servidor
MS Proxy ip masquerade, proxy para Linux requer
nat, diald, o uso de vários programas
exim, separados para que se tenha
um resultado profissional.
Isto pode parecer incomodo
no começo, mas você logo
perceberá que a divisão
de serviços entre programas
é mais produtivo. Quando
desejar substituir um
deles, o funcionamento dos
outros não serão afetados.
Não vou entrar em detalhes
sobre os
programas citados ao lado,
mas o squid é um servidor
proxy Web (HTTP e HTTPS)
completo e também apresenta
um excelente serviço FTP.
Possui outros módulos como
dns, ping, restrições de
acesso, limites de tamanho
de arquivos, cache, etc.
MS Frontpage SeaMonkey, BlueGriffon Sem comentários... todas são
e muitas outras ferramentas para a geração
ferramentas para de grandes Web Sites. O wdm,
geração de conteúdo por exemplo, é usado na geração
WEB (como zope, do site da distribuição Debian
php3, php4, wdm, (http://www.debian.org) em 30
htdig) idiomas diferentes.
MS Winsock Sem equivalente O Linux tem suporte nativo a
tcp/ip desde o começo de sua
existência e não precisa de
nenhuma camada de comunicação
entre ele e a Internet. A
performance é aproximadamente
10% maior em conexões Internet
via fax-modem e outras redes
tcp/ip.
AVG, Viruscan, Clamav, AVG Os maiores fabricantes de
norton, F-PROT, F-Prot, ViruScan anti-virus disponibilizam
CPAV. Kaspersky, versões para Linux, com o
ESET NOD32, objetivo principal de
Avast, McAfee remoção de vírus em
Comodo. servidores de E-mail ou
servidores de arquivos,
com o objetivo de não
contaminar os vulneráveis
sistemas Windows, servindo
como uma efetiva barreira
de defesa na rede.
WindowsLinuxDiferenças
----------- ---------- -----------------------------------------------
Sem XWindow System, A interface gráfica
equivalente XFree86 no GNU/Linux funciona
X.org geralmente sobre um
Wayland, software com funcionamento
Mir. do tipo cliente-servidor
(um programa separado do sistema),
o que facilita muito utilizar
o Desktop através de uma rede.
Com as excessões recentes
do Ubuntu (que utiliza o
Mir), e o Fedora WorkStation
(que utiliza Wayland), as
distribuições em geral
ainda utilizam o X como
servidor gráfico, o mais
antigo ainda em uso.
MS Windows, jwm, twm Diferentemente do Windows (em que a
DWM, fluxbox, interface É o sistema), a evolução
MS Windows Aero blackbox, da interface gráfica do GNU/Linux
lxde, xfce, ocorreu separadamente do sistema.
KDE, Gnome, Opções de interface
openbox, gráfica para o pinguim
e muitas é o que não faltam:
outras. desde ambientes
extremamente leves (jwm)
que dão basicamente um
gerenciador de janelas,
até monstros que quase
substituem o próprio
sistema operacional
como KDE & Gnome.
Este capítulo traz explicações de como manipular discos rígidos e partições no sistema GNU/Linux e como acessar seus discos de CD-ROM e partições DOS, Windows 9X/XP/Vista no GNU/Linux.
Também será ensinado como formatar uma partição ou arquivo em formato EXT2, EXT3, EXT4, reiserfs e usar a ferramenta mkswap (para criar uma partição ou arquivo de memória virtual).
São divisões existentes no disco rígido que marcam onde começa onde termina um sistema de arquivos. Por causa destas divisões, nós podemos usar mais de um sistema operacional no mesmo computador (como o GNU/Linux, Windows e DOS), ou dividir o disco rígido em uma ou mais partes para ser usado por um único sistema operacional.
Para gravar os dados, o disco rígido deve ser primeiro particionado (usando o fdisk), escolher o tipo da partição (Linux Native, Linux Swap, etc) e depois aquela partição deve ser formatada com o mkfs.ext2 (veja [#s-disc-ext2 Partição EXT2 (Linux Native), Seção 5.3]).
Após criada e formatada, a partição será identificada como um dispositivo no diretório /dev (veja [#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12]) . e deverá ser montada ([#s-disc-montagem Montando (acessando) uma partição de disco, Seção 5.13]) para permitir seu uso no sistema.
Uma partição de disco não interfere em outras partições existentes, por este motivo é possível usar o Windows, GNU/Linux e qualquer outro sistema operacional no mesmo disco. Para escolher qual deles será inicializado, veja [ch-boot.html Gerenciadores de Partida (boot loaders), Capítulo 6].
Para particionar (dividir) o disco rígido em uma ou mais partes é necessário o uso de um programa de particionamento. Os programas mais conhecidos para particionamento de discos no GNU/Linux são fdisk, cfdisk e o Disk Druid.
Lembre-se:
Quando se apaga uma partição, você estará apagando TODOS os arquivos existentes nela!
A partição do tipo Linux Native (Tipo 83) é a usada para armazenar arquivos no GNU/Linux. Para detalhes veja [#s-disc-ext2 Partição EXT2 (Linux Native), Seção 5.3].
A partição do tipo Linux Swap (Tipo 82) é usada como memória virtual. Para detalhes veja [#s-disc-swap Partição Linux Swap (Memória Virtual), Seção 5.7].
Em sistemas novos, é comum encontrar o Windows instalado em uma partição que consome TODO o espaço do disco rígido. Uma solução para instalar o GNU/Linux é apagar a partição Windows e criar três com tamanhos menores (uma para o Windows, uma para o GNU/Linux e outra para a Memória Virtual do Linux (SWAP). Ou criar apenas 2 se você não quiser mais saber mais do Windows ;-)
A outra é usar o parted (e gparted sua versão gráfica), um bom exemplo de programa de reparticionamento não destrutivo (que usa o espaço livre existente) que trabalha com FAT16, FAT32, NTFS. Esta técnica também é chamada de Reparticionamento não destrutivo (e o outro obviamente Reparticionamento destrutivo).
Para mais detalhes sobre discos, partições ou como particionar seu disco, veja algum bom documento sobre particionamento (como a página de manual e documentação do fdisk, cfdisk, parted ou Disk Druid).
É criado durante a "formatação" da partição de disco (quando se usa o comando mkfs.ext2). Após a formatação toda a estrutura para leitura/gravação de arquivos e diretórios pelo sistema operacional estará pronta para ser usada. Normalmente este passo é feito durante a instalação de sua distribuição GNU/Linux.
Cada sistema de arquivos tem uma característica em particular mas seu propósito é o mesmo: Oferecer ao sistema operacional a estrutura necessária para ler/gravar os arquivos/diretórios.
Entre os sistemas de arquivos existentes posso citar:
Ext2 - Usado em partições Linux Nativas para o armazenamento de arquivos. É identificado pelo código 83. Seu tamanho deve ser o suficiente para acomodar todo os arquivos e programas que deseja instalar no GNU/Linux (você encontra isto no manual de sua distribuição). Para detalhes veja [#s-disc-ext2 Partição EXT2 (Linux Native), Seção 5.3].
Ext3 - Este sistema de arquivos possui melhorias em relação ao ext2, como destaque o recurso de jornaling. Ele também é identificado pelo tipo 83 e totalmente compatível com o ext2 em estrutura. O journal mantém um log de todas as operações no sistema de arquivos, caso aconteça uma queda de energia elétrica (ou qualquer outra anormalidade que interrompa o funcionamento do sistema), o fsck verifica o sistema de arquivos no ponto em que estava quando houve a interrupção, evitando a demora para checar todo um sistema de arquivos (que pode levar minutos em sistemas de arquivos muito grandes). Para detalhes veja [#s-disc-ext3 Partição EXT3 (Linux Native), Seção 5.5].
Swap - Usado em partições Linux Swap para oferecer memória virtual ao sistema. Note que é altamente recomendado o uso de uma partição Swap no sistema (principalmente se você tiver menos que 16MB de memória RAM). Este tipo de partição é identificado pelo código 82. Para detalhes veja [#s-disc-swap Partição Linux Swap (Memória Virtual), Seção 5.7].
proc - Sistema de arquivos do kernel (veja [#s-disc-proc O sistema de arquivos /proc, Seção 5.8]).
FAT12 - Usado em disquetes no DOS
FAT16 - Usado no DOS e oferece suporte até discos de 2GB
FAT32 - Também usado no DOS e oferece suporte a discos de até 2 Terabytes
A partição EXT2 é o tipo usado para criar o sistema de arquivos Linux Native usado para armazenar o sistema de arquivos EXT2 (após a formatação) e permitir o armazenamento de dados. Para detalhes de como criar uma partição EXT2 veja [#s-disc-ext2-criando-p Criando um sistema de arquivos EXT2 em uma partição, Seção 5.3.1].
Este tipo de partição é normalmente identificado pelo código 83 nos programas de particionamento de disco. Note que também é possível criar um sistema de arquivos EXT2 em um arquivo (ao invés de uma partição) que poderá ser montado e acessado normalmente pelo sistema de arquivos (veja [#s-disc-ext2-criando-a Criando um sistema de arquivos EXT2 em um arquivo, Seção 5.3.2].
Logo que foi inventado, o GNU/Linux utilizava o sistema de arquivos Minix (e consequentemente uma partição Minix) para o armazenamento de arquivos. Com a evolução do desenvolvimento, foi criado o padrão EXT (Extended Filesystem) e logo evoluiu para o EXT2 (Second Extended Filesystem) que é o usado hoje em dia.
Você deve escolher este tipo de partição para armazenar seus arquivos, é o padrão atualmente, é o mais rápido, não se fragmenta tão facilmente pois permite a localização do melhor lugar onde o arquivo se encaixa no disco, etc. Isto é útil para grandes ambientes multiusuário onde várias pessoas gravam/apagam arquivos o tempo todo.
Criando um sistema de arquivos EXT2 em uma partição
O utilitário usado para formatar uma partição EXT2 é o mkfs.ext2. Após terminar este passo, seu sistema de arquivos EXT2 estará pronto para ser usado.
Após particionar seu disco rígido e criar uma (ou várias) partições EXT2, use o comando:
mkfs.ext2 /dev/hda?
Onde a "?" em hda? significa o número da partição que será formatada. A identificação da partição é mostrada durante o particionamento do disco, anote se for o caso. hda é o primeiro disco rígido IDE, hdb é o segundo disco rígido IDE. Discos SCSI são identificados por sda?, sdb?, etc. Para detalhes sobre a identificação de discos, veja [#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12].
Algumas opções são úteis ao mkfs.ext2:
-c Procura blocos danificados na partição antes de criar o sistema de arquivos.
-L NOME Coloca um nome (label) no sistema de arquivos.
-b NUM Define o tamanho do bloco, em bytes.
-m NUM Define a porcentagem de espaço em disco reservada para manutenção (por padrão reservado para o root, mas isto é alterável).
Agora para acessar a partição deverá ser usado o comando: mount /dev/hda? /mnt -t ext2
Para mais detalhes veja [#s-disc-montagem Montando (acessando) uma partição de disco, Seção 5.13].
Note que é possível criar um sistema de arquivos no disco rígido sem criar uma partição usando /dev/hda, /dev/hdb, etc. EVITE FAZER ISSO! Como não estará criando uma partição, o disco estará divido de maneira incorreta, você não poderá apagar o sistema de arquivos completamente do disco caso precise (lembre-se que você não criou uma partição), e a partição possui uma assinatura apropriada que identifica o sistema de arquivos.
O espaço padrão reservado na partição para o usuário root é de 5%. Em sistemas com partições maiores que 3Gb, isso pode representar uma grande quantidade de espaço em disco não utilizada por outros usuários. Veja a opção -m sobre como fazer esta modificação. Caso já tenha criado a partição, isto pode ser feito no tune2fs com a opção -m.
É possível criar um sistema de arquivos EXT2 em um arquivo que poderá ser montado e acessado normalmente como se fosse uma partição normal. Isto é possível por causa do recurso loop oferecido pelo kernel do GNU/Linux. Os dispositivos de loop estão disponíveis no diretório /dev com o nome loop? (normalmente estão disponíveis 8 dispositivos de loop).
Isto é possível usando o comando dd e o mkfs.ext2. Veja passo a passo como criar o sistema de arquivos EXT2 em um arquivo:
Use o comando dd if=/dev/zero of=/tmp/arquivo-ext2 bs=1024 count=10000 para criar um arquivo arquivo-ext2 vazio de 10Mb de tamanho em /tmp. Você pode modificar os parâmetros de of para escolher onde o arquivo será criado, o tamanho do arquivo poderá ser modificado através de count
Formate o arquivo com mkfs.ext2 /tmp/arquivo-ext2. Ele primeiro dirá que o arquivo arquivo-ext2 não é um dispositivo de bloco especial (uma partição de disco) e perguntará se deve continuar, responda com y.
O sistema de arquivos EXT2 será criado em /tmp/arquivo-ext2 e estará pronto para ser usado.
Monte o arquivo arquivo-ext2 com o comando: mount /tmp/arquivo-ext2 /mnt -o loop=/dev/loop1. Note que foi usado o parâmetro -o loop para dizer ao comando mount para usar os recursos de loop do kernel para montar o sistema de arquivos.
Confira se o sistema de arquivos EXT2 em arquivo-ext2 foi realmente montado no sistema de arquivos digitando df -T. Para detalhes, veja [ch-cmdv.html#s-cmdv-df df, Seção 10.3].
Pronto! o que você gravar para /mnt será gravado dentro do arquivo /tmp/arquivo-ext2. Como foi criado um sistema de arquivos EXT2 em arquivo-ext2, você poderá usar todos os recursos da partição EXT2 normal, como permissões de arquivos e diretórios, links simbólicos, etc.
O uso da opção loop=/dev/loop1 permite que o dispositivo /dev/loop1 seja associado ao arquivo /arquivo-ext2 e assim permitir sua montagem e uso no sistema.
Você poderá usar apenas -o loop com o comando mount, assim o kernel gerenciará automaticamente os dispositivos de loop.
Caso faça isto manualmente, lembre-se de usar dispositivos /dev/loop? diferentes para cada arquivo que montar no sistema. Pois cada um faz referência a um único arquivo.
O sistema de journaling grava qualquer operação que será feita no disco em uma área especial chamada "journal", assim se acontecer algum problema durante a operação de disco, ele pode voltar ao estado anterior do arquivo, ou finalizar a operação.
Desta forma, o journal acrescenta ao sistema de arquivos o suporte a alta disponibilidade e maior tolerância a falhas. Após uma falha de energia, por exemplo, o journal é analisado durante a montagem do sistema de arquivos e todas as operações que estavam sendo feitas no disco são verificadas. Dependendo do estado da operação, elas podem ser desfeitas ou finalizadas. O retorno do servidor é praticamente imediato (sem precisar a enorme espera da execução do fsck em partições maiores que 10Gb), garantindo o rápido retorno dos serviços da máquina.
Outra situação que pode ser evitada é com inconsistências no sistema de arquivos do servidor após a situação acima, fazendo o servidor ficar em estado 'single user' e esperando pela intervenção do administrador. Este capítulo do guia explica a utilização de journaling usando o sistema de arquivos ext3 (veja [#s-disc-ext3 Partição EXT3 (Linux Native), Seção 5.5] para detalhes).
O sistema de arquivos ext3 faz parte da nova geração extended file system do Linux, sendo que seu maior benefício é o suporte a journaling.
O uso deste sistema de arquivos comparado ao ext2, na maioria dos casos, melhora o desempenho do sistema de arquivos através da gravação sequencial dos dados na área de metadados e acesso mhash a sua árvore de diretórios.
A estrutura da partição ext3 é semelhante a ext2, o journaling é feito em um arquivo chamado .journal que fica oculto pelo código ext3 na partição (desta forma ele não poderá ser apagado, comprometendo o funcionamento do sistema). A estrutura idêntica da partição ext3 com a ext2 torna mais fácil a manutenção do sistema, já que todas as ferramentas para recuperação ext2 funcionarão sem problemas.
Criando um sistema de arquivos EXT3 em uma partição
Para criar uma partição ext3, utilize o comando mkfs.ext3 ou o mkfs.ext2 junto com a opção -j. As opções usadas pelo mkfs.ext3 são idênticas a do mkfs.ext2 (documentado em [#s-disc-ext2-criando-p Criando um sistema de arquivos EXT2 em uma partição, Seção 5.3.1]). A única vantagem desta ferramenta comparada ao mkfs.ext2 é que a opção -j é automaticamente adicionada a linha de comando para criar um sistema de arquivos com journal. Se você é daqueles que querem ter um controle maior sobre o tamanho do arquivo de journal, use a opção -J [tam] (onde tamanho é o tamanho em Megabytes).
Quando uma partição ext3 é criada, o arquivo .journal é criado no raíz da partição, sendo usado para gravar os metadados das transações de journaling. A estrutura da partição ext2 não difere em nada da ext3, a não ser este arquivo e a opção "has_journal" que é passada a partição.
Por exemplo, para criar uma partição ext3 em /dev/hda1:
mkfs.ext3 /dev/hda1
ou
mkfs.ext2 -j /dev/hda1
Basta agora montar a partição com o comando mount /dev/hda1 /teste -t ext3 (para montar a partição em /teste. Após isto, modifique o /etc/fstab para montar a partição como ext3 quando o Linux for iniciado. Para mais detalhes veja [#s-disc-montagem Montando (acessando) uma partição de disco, Seção 5.13]. ). Caso o suporte a ext3 tenha sido compilado no kernel, ele tentará detectar e montar a partição como ext3, caso contrário, ele usará ext2.
Sua partição agora está montada como ext3, para conferir digite: df -T.
OBS: Quando criar um sistema de arquivos ext3 em uma partição raíz (/), tenha certeza de incluir o suporte a ext3 embutido no kernel, caso contrário a partição será montada como ext2.
As instruções para criar um sistema de arquivos ext3 em um arquivo não difere muito das instruções de [#s-disc-ext2-criando-a Criando um sistema de arquivos EXT2 em um arquivo, Seção 5.3.2], apenas utilize a opção -j ou -J [tamanho_em_mb] (como explicado em [#s-disc-ext3-criando-p Criando um sistema de arquivos EXT3 em uma partição, Seção 5.5.1]).
Fazendo a conversão do sistema de arquivos EXT2 para EXT3
Se você já possui um uma partição ext2 e deseja converte-la para ext3 isto poderá ser feito facilmente, de forma segura (sem qualquer risco de perda de dados) e você poderá voltar para o sistema ext2 caso deseje (veja [#s-disc-ext3-conv3-2 Convertendo de EXT3 para EXT2, Seção 5.5.4]).
Primeiro, execute o comando tune2fs na partição que deseja converter com a opção -j ou -J [tamanho_journal] para adicionar o suporte a Journaling na partição. Este comando poderá ser executado com segurança em uma partição ext2 montada, após converter remontar a partição usando os comandos umount /particao e mount /particao.
Após a conversão para ext3 é desnecessária a checagem periódica do sistema de arquivos (que por padrão é após 20 montagens e a cada 30 dias). Você pode desativar a checagem após o número máximo de montagens com a opção -c [num_vezes], e o número de dias máximos antes de verificar novamente com a opção -i [num_dias] (o uso de 0 desativa). Por exemplo:
tune2fs -c 0 -i 90 /dev/hda2
Desativa a checagem após número máximo de montagens (-c 0) e diz para a partição ser verificada a cada 90 dias (-i 90).
O último passo é modificar o /etc/fstab para que a partição seja montada como ext3 na inicialização e depois desmontar (umount /dev/hda2 e remonta-la (mount /dev/hda2) para usar o suporte ext3. Confira se ela está usando ext3 usando o comando df -T.
OBS: Caso a partição convertida para ext3 seja a raíz (/), tenha certeza de incluir o suporte a ext3 embutido no kernel, caso contrário, a partição será montada como ext2.
Remover o suporte a ext3 de uma partição é simples, rápido e seguro. Execute os seguintes passos:
Execute o comando tune2fs -O^has_journal /dev/hdxx na partição que deseja remover o Journal. Este comando poderá ser executado em uma partição montada.
Modifique o /etc/fstab e altere a partição para ext2.
Desmonte e monte novamente a partição com os comandos: umount /dev/hdxx e mount /dev/hdxx.
Pronto! a partição agora é novamente uma partição ext2 normal, confira digitando df -T.
Pronto, o suporte a ext3 foi removido do seu sistema e agora poderá usar a partição como ext2 normalmente (confira digitando df -T).
Este é um sistema de arquivos alternativo ao ext2/3 que também possui suporte a journaling. Entre suas principais características, estão que ele possui tamanho de blocos variáveis, suporte a arquivos maiores que 2 Gigabytes (esta é uma das limitações do ext3) e o acesso mhash a árvore de diretórios é um pouco mais rápida que o ext3.
Para utilizar reiserfs, tenha certeza que seu kernel possui o suporta habilitado (na seção File Systems) e instale o pacote reiserfsprogs que contém utilitários para formatar, verificar este tipo de partição.
Criando um sistema de arquivos reiserfs em uma partição
Para criar uma partição reiserfs, primeiro instale o pacote reiserfsprogs (apt-get install reiserfsprogs).
Para criar uma partição reiserfs, primeiro crie uma partição ext2 normal, e então use o comando:
mkreiserfs /dev/hda?
Onde a "?" em hda? significa o número da partição que será formatada com o sistema de arquivos reiserfs. A identificação da partição é mostrada durante o particionamento do disco, anote se for o caso. hda é o primeiro disco rígido IDE, hdb é o segundo disco rígido IDE. Discos SCSI são identificados por sda?, sdb?, etc. Para detalhes sobre a identificação de discos, veja [#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12].
Algumas opções são úteis ao mkreiserfs:
-s [num] - Especifica o tamanho do arquivo de journal em blocos. O valor mínimo é 513 e o máximo 32749. O valor padrão é 8193.
-l [NOME] - Coloca um nome (label) no sistema de arquivos.
-f - Força a execução do mkreiserfs.
-d - Ativa a depuração durante a execução do mkreiserfs.
Agora para acessar a partição deverá ser usado o comando: mount /dev/hda? /mnt -t reiserfs
Para mais detalhes veja [#s-disc-montagem Montando (acessando) uma partição de disco, Seção 5.13].
Note que é possível criar um sistema de arquivos no disco rígido sem criar uma partição usando /dev/hda, /dev/hdb, etc. usando a opção -f EVITE FAZER ISSO! Como não estará criando uma partição, o disco estará divido de maneira incorreta, você não poderá apagar o sistema de arquivos completamente do disco caso precise (lembre-se que você não criou uma partição), e a partição possui uma assinatura apropriada que identifica o sistema de arquivos.
Criando um sistema de arquivos reiserfs em um arquivo
O sistema de arquivos reiserfs também poderá ser criado em um arquivo, usando os mesmos benefícios descritos em [#s-disc-ext2-criando-a Criando um sistema de arquivos EXT2 em um arquivo, Seção 5.3.2]. Para fazer isso execute os seguintes passos em sequência:
Use o comando dd if=/dev/zero of=/tmp/arquivo-reiserfs bs=1024 count=33000 para criar um arquivo arquivo-reiserfs vazio de 33Mb de tamanho em /tmp. Você pode modificar os parâmetros de of para escolher onde o arquivo será criado, o tamanho do arquivo poderá ser modificado através de count. Note que o tamanho mínimo do arquivo deve ser de 32Mb, devido aos requerimentos do reiserfs.
Formate o arquivo com mkreiserfs -f /tmp/arquivo-reiserfs. Ele primeiro dirá que o arquivo arquivo-reiserfs não é um dispositivo de bloco especial (uma partição de disco) e perguntará se deve continuar, responda com y.
O sistema de arquivos ReiserFS será criado em /tmp/arquivo-reiserfs e estará pronto para ser usado.
Monte o arquivo arquivo-reiserfs com o comando: mount /tmp/arquivo-reiserfs /mnt -t reiserfs -o loop=/dev/loop1. Note que foi usado o parâmetro -o loop para dizer ao comando mount para usar os recursos de loop do kernel para montar o sistema de arquivos. O parâmetro -t reiserfs poderá ser omitido, se desejar.
Confira se o sistema de arquivos ReiserFS em arquivo-reiserfs foi realmente montado no sistema de arquivos digitando df -T. Para detalhes, veja [ch-cmdv.html#s-cmdv-df df, Seção 10.3].
Pronto! o que você gravar para /mnt será gravado dentro do arquivo /tmp/arquivo-reiserfs. Você poderá usar todos os recursos de um sistema de arquivos reiserfs como permissões de arquivos e diretórios, links simbólicos, etc.
O uso da opção loop=/dev/loop1 permite que o dispositivo /dev/loop1 seja associado ao arquivo /arquivo-reiserfs e assim permitir sua montagem e uso no sistema.
Você poderá usar apenas -o loop com o comando mount, assim o kernel gerenciará automaticamente os dispositivos de loop.
Caso faça isto manualmente, lembre-se de usar dispositivos /dev/loop? diferentes para cada arquivo que montar no sistema. Pois cada um faz referência a um único arquivo.
O comando e2label é usado para esta função.
e2label [dispositivo] [nome]
Onde:
dispositivo
Partição que terá o nome modificado
nome
Nome que será dado a partição (máximo de 16 caracteres). Caso seja usado um nome de volume com espaços, ele deverá ser colocado entre "aspas".
Se não for especificado um nome, o nome atual da partição será mostrado. O nome da partição também pode ser visualizado através do comando dumpe2fs (veja [#s-disc-dumpe2fs dumpe2fs, Seção 5.7.5]).
Exemplo: e2label /dev/sda1 FocaLinux, e2label /dev/sda1 "Foca Linux"
O utilitário mklost found cria o diretório especial lost found no diretório atual. O diretório lost found é criado automaticamente após a formatação da partição com o mkfs.ext2, a função deste diretório é pré-alocar os blocos de arquivos/diretório durante a execução do programa fsck.ext2 na recuperação de um sistema de arquivos (veja [ch-manut.html#s-manut-checagem Checagem dos sistemas de arquivos, Seção 26.1]). Isto garante que os blocos de disco não precisarão ser diretamente alocados durante a checagem.
mklost found
OBS: Este comando só funciona em sistemas de arquivos ext2
Exemplo: cd /tmp;mklost found;ls -a
Mostra detalhes sobre uma partição Linux.
dumpe2fs [opções] [partição]
Onde:
partição
Identificação da partição que será usada.
opções
-b
Mostra somente os blocos marcado como defeituosos no sistema de arquivos especificado.
Este comando lista diversas opções úteis do sistema de arquivos como o tipo do sistema de arquivos, características especiais, número de inodos, blocos livres, tamanho do bloco, intervalo entre checagens automáticas, etc.
Exemplo: dumpe2fs /dev/sda1, dumpe2fs -b /dev/sda1
Criar uma partição EXT2 ou um arquivo usando o loop? Abaixo estão algumas considerações:
A partição EXT2 é o método recomendado para a instalação do GNU/Linux.
O desempenho da partição EXT2 é bem melhor se comparado ao arquivo porque é acessada diretamente pelo Kernel (SO).
O arquivo EXT2 é útil para guardarmos dados confidenciais em disquetes ou em qualquer outro lugar no sistema. Você pode perfeitamente gravar seus arquivos confidenciais em um arquivo chamado libBlaBlaBla-2.0 no diretório /lib e ninguém nunca suspeitará deste arquivo (acho que não...). Também é possível criptografa-lo para que mesmo alguém descobrindo que aquilo não é uma lib, não poder abri-lo a não ser que tenha a senha (isto é coberto no documento Loopback-encripted-filesystem.HOWTO).
O uso do arquivo EXT2 é útil quando você está perdendo espaço na sua partição EXT2 e não quer re-particionar seu disco pois teria que ser feita uma re-instalação completa e tem muito espaço em um partição de outro SO (como o Windows).
Você poderia facilmente copiar o conteúdo de /var, por exemplo, para o arquivo EXT2 ext2-l criado no diretório Raíz do Windows, apagar o conteúdo de /var (liberando muito espaço em disco) e então montar ext2-l como /var. A partir de agora, tudo o que for gravado em /var será na realidade gravado no arquivo ext2-l.
Para o sistema acessar o arquivo, deve passar pelo sistema de arquivos loop e FAT32, isto causa um desempenho menor.
Este tipo de partição é usado para oferecer o suporte a memória virtual ao GNU/Linux em adição a memória RAM instalada no sistema. Este tipo de partição é identificado pelo tipo 82 nos programas de particionamento de disco para Linux. Para detalhes de como criar uma partição Linux Swap veja [#s-disc-swap-criando-p Criando sistema de arquivos Swap em uma partição, Seção 5.8.1].
Somente os dados na memória RAM são processados pelo processador, por ser mais rápida. Desta forma quando você está executando um programa e a memória RAM começa a encher, o GNU/Linux move automaticamente os dados que não estão sendo usados para a partição Swap e libera a memória RAM para a continuar carregando os dados necessários pelo. Quando os dados movidos para a partição Swap são solicitados, o GNU/Linux move os dados da partição Swap para a Memória. Por este motivo a partição Swap também é chamada de Troca ou memória virtual.
A velocidade em que os dados são movidos da memória RAM para a partição é muito alta. Note também que é possível criar o sistema de arquivos Swap em um arquivo ao invés de uma partição (veja [#s-disc-swap-criando-a Criando um sistema de arquivos Swap em um arquivo, Seção 5.8.2]).
O programa usado para formatar uma partição Swap é o mkswap. Seu uso é simples:
mkswap /dev/hda?
Novamente veja [#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12] caso não souber identificar seus discos e partições. O nome do dispositivo da partição Swap pode ser visualizado através de seu programa de particionamento, você pode usar o comando fdisk -l /dev/hda para listar as partições no primeiro disco rígido e assim verificar qual dispositivo corresponde a partição Swap.
A opção -c também pode ser usada com o mkswap para checar se existem agrupamentos danificados na partição.
Com a partição Swap formatada, use o comando: swapon /dev/hda? para ativar a partição Swap (lembre-se de substituir ? pelo número de sua partição Swap).
Observações:
Os Kernels do GNU/Linux 2.0.xx e anteriores somente suportam partições Swap de até 128MB. Caso precise de mais que isso, crie mais partições Swap ou atualize seu sistema para trabalhar com o kernel 2.2.xx
Se utilizar mais que 1 partição Swap, pode ser útil o uso da opção -p NUM que especifica a prioridade em que a partição Swap será usada. Pode ser usado um valor de prioridade entre 0 e 32767, partições com número maior serão usadas primeiro, sendo que na montagem automática através de "mount -a" podem ser designados números negativos.
Procure usar o número maior para partições mais rápidas (elas serão acessadas primeiro) e números maiores para partições mais lentas. Caso precise desativar a partição Swap, use o comando: swapoff /dev/hda?.
Também é possível criar um arquivo que poderá ser usado como memória virtual. Veja passo a passo como fazer isso:
Use o comando dd if=/dev/zero of=/tmp/troca bs=1024 count=16000 para criar um arquivo chamado troca vazio de 16Mb de tamanho em /tmp. Você pode modificar os parâmetros de of para escolher onde o arquivo será criado, o tamanho do arquivo poderá ser modificado através de count.
Execute mkswap /tmp/troca para formatar o arquivo. Após concluir este passo, o sistema de arquivos Swap estará criado e pronto para ser usado.
Digite sync para sincronizar os buffers para o disco, assim você não terá problemas em um servidor com muito I/O.
Ative o arquivo de troca com o comando swapon /tmp/troca.
Confira se o tamanho da memória virtual foi modificado digitando cat /proc/meminfo ou free.
Observações:
Podem ser usadas partições de troca e arquivos de troca juntos, sem problemas.
Caso seu sistema já tenha uma partição de Swap, é recomendável deixar o acesso ao arquivo Swap com uma prioridade menor (usando a opção -p NUM com o comando swapon).
Criar uma partição de Troca ou um arquivo de troca? Abaixo algumas vantagens e desvantagens:
A partição Swap é mais rápida que o arquivo Swap pois é acessada diretamente pelo Kernel. Se o seu computador tem pouca memória (menos que 32Mb) ou você tem certeza que o sistema recorre frequentemente a memória virtual para executar seus programas, é recomendável usar uma partição Swap.
O arquivo de troca permite que você crie somente uma partição Linux Native e crie o arquivo de troca na partição EXT2.
Você pode alterar o tamanho do arquivo de troca facilmente apagando e criando um novo arquivo como descrito em [#s-disc-swap-criando-a Criando um sistema de arquivos Swap em um arquivo, Seção 5.8.2].
É possível criar um arquivo de troca em outros tipos de partições como FAT16, FAT32, etc.
O arquivo de troca estará disponível somente após o sistema de arquivos que o armazena (ext2, fat32, etc) estar montado. Isto é um problema para sistemas com pouca memória que dependem do arquivo de troca desde sua inicialização.
É o sistema de arquivos do Kernel do GNU/Linux. Ele oferece um método de ler, gravar e modificar dinamicamente os parâmetros do kernel, muito útil para curiosos (como eu) e programas de configuração. A modificação dos arquivos do diretório /proc é o método mais usado para modificar a configuração do sistema e muitos programas também dependem deste diretório para funcionar.
Nele você tem todo o controle do que o seus sistema operacional está fazendo, a configuração dos hardwares, interrupções, sistema de arquivos montado, execução de programas, memória do sistema, rede, etc.
Agora entre no diretório /proc digite ls e veja a quantidade de arquivos e diretórios que ele possui, dê uma passeada por eles. Abaixo a descrição de alguns deles (todos podem ser visualizados pelo comando cat):
Diretórios com números - Estes identificam os parâmetros de um processo em execução. Por exemplo, se o PID (identificação do processo) do inetd for 115, você pode entrar no diretório 115 e verificar as opções usadas para execução deste programa através de cada arquivos existente dentro do diretório. Alguns são:
cmdline - O que foi digitado para iniciar o processo (pode também ter sido iniciado através de um programa ou pelo kernel).
environ - Variáveis de Ambiente existentes no momento da execução do processo.
status - Dados sobre a execução do Processo (PID, status da execução do programa, memória consumida, memória executável, UID, GID, etc).
apm - Dados sobre o gerenciamento de energia
cmdline - Linha de comando usada para inicializar o Kernel GNU/Linux. Os parâmetros são passados através do programa de inicialização, como o LILO, LOADLIN, SYSLINUX.
cpuinfo - Detalhes sobre a CPU do sistema
devices - Dispositivos usados no sistema
dma - Canais de DMA usados por dispositivos
filesystems - Sistemas de arquivos em uso atualmente
interrupts - Interrupções usadas por dispositivos
ioports - Portas de Entrada e Saída usadas pelos dispositivos do sistema
kcore - Este arquivo corresponde a toda a memória RAM em seu sistema. Seu tamanho é correspondente a memória RAM do micro
kmsg - Permite visualizar mensagens do Kernel (use o comando cat < kmsg para visualiza-lo e pressione CTRL C para cancelar
loadavg - Média de Carga do sistema
meminfo - Dados de utilização da memória do sistema
misc - Outras configurações
modules - Módulos atualmente carregados no kernel
mounts - Sistemas de Arquivos atualmente montados
pci - Detalhes sobre dispositivos PCI do sistema
rtc - Relógio em Tempo real do sistema
uptime - Tempo de execução do sistema
version - Versão atual do Kernel, programa usado na compilação, etc
Diretório net - Dados sobre a rede do sistema
Diretório sys - Dados sobre outras áreas do sistema
Diretório scsi - Detalhes sobre dispositivos SCSI do sistema
Note que o diretório proc e os arquivos existentes dentro dele estão localizados no diretório raiz (/), mas não ocupa nenhum espaço no disco rígido.
O lvm (Logical Volume Manager) faz a associação entre dispositivos/partições físicas (incluindo discos RAID, MO, mass storages diversos, MD, e loop) e dispositivos lógicos. O método tradicional faz a alocação de todo espaço físico ao tamanho da partição do disco (o método tradicional), o que traz muito trabalho quando o espaço esgota, cópia de dados ou planejamento de uso de máquina (que pode mudar com o passar do tempo). O sistema de lvm soluciona os seguintes problemas:
Uso eficaz de disco, principalmente quando há pouco espaço para criação de partições independentes.
Permite aumentar/diminuir dinamicamente o tamanho das partições sem reparticionamento do disco rígido usando o espaço livre em outras partições ou utilizando o espaço livre reservado para o uso do LVM.
Uma partição de disco é identificada por um nome de volume e não pelo dispositivo. Você pode então se referir aos volumes como: usuários, vendas, diretoria, etc.
Sua divisão em 3 camadas possibilita a adição/remoção de mais discos de um conjunto caso seja necessário mais espaço em volumes, etc.
Permite selecionar o tamanho do cluster de armazenamento e a forma que eles são acessados entre os discos, possibilitando garantir a escolha da melhor opção dependendo da forma que os dados serão manipulados pelo servidor.
Permite snapshots dos volumes do disco rígido.
As 3 camadas do LVM são agrupadas da seguinte forma:
PV (Phisical Volume) - Corresponde a todo o disco rígido/partição ou dispositivo de bloco que será adicionado ao LVM. Os aplicativos que manipulam o volume físico, começam com as letras pv*. O espaço disponível no PV é dividido em PE (Phisical Extends, ou extensões físicas). O valor padrão do PE é de 4MB, possibilitando a criação de um VG de 256Gb.
Por exemplo: /dev/hda1
VG (Volume Group) - Corresponde ao grupo de volumes físicos que fazem parte do LVM. Do grupo de volume são alocados os espaços para criação dos volumes lógicos. Os aplicativos que manipulam o o grupo de volume, começam com as letras vg*.
Por exemplo: /dev/lvmdisk0 LV (Logical Volume) - Corresponde a partição lógica criada pelo LVM para gravação de dados. ao invés de ser identificada por nomes de dispositivos, podem ser usados nomes comuns para se referir as partições (tmp,usr,etc.). O Volume lógico é a área onde o sistema de arquivo é criado para gravação de dados, seria equivalente a partição em um sistema SEM LVM só que lógica ao invés de física. O volume lógico tem seu espaço dividido em LE (Logical Extends, ou extensões lógicas) que correspondem aos PE's alocados.
Exemplos: /dev/lvmdisk/usr, /dev/lvmdisk/tmp, etc.
Desenvolvi este desenho para representar a idéia de organização de um sistema LVM para o guia Foca GNU/Linux e apresentar a descrição prática da coisa:
------[ Grupo de Volume (VG) - lvmdsk ]------
| --[ PV - hda1 ]--- --[ PV - hdb1 ]-- |
| | PE PE PE PE PE PE| | PE PE PE PE PE | |
| ------------------ ----------------- |
| | | | | |
| | | ----------------- | |
| | ---------------- | |
| | | | | |
| -[ LV - var ]- -[ LV - home ]- |
| | LE LE LE LE | | LE LE LE LE | |
| -------------- --------------- |
---------------------------------------------
O gráfico acima representa a seguinte situação:
Nós temos dois volumes físicos representados por hda1 e hdb1. Cada um desses volumes físicos tem um Phisical Extend (PE) de 4M (o padrão).
Estes dois volumes físicos acima representam o espaço total do grupo de volume lvmdisk em /dev/lvmdisk.
Do grupo de volume lvmdisk são criados dois volumes lógicos chamados var e home, estando disponíveis para particionamento através de /dev/lvmdisk/var e /dev/lvmdisk/home.
Na prática, o espaço do volume lógico é definido alocando-se alguns Phisical Extends (PE) dos volumes físicos como logical extends (LE) dos volumes lógicos. Desta forma, o tamanho de todos os PEs e LEs existentes dentro de um mesmo grupo de volume devem ser iguais.
Um sistema com LVM tem sua performance um pouco reduzida quanto ao acesso a disco, devido as camadas adicionais de acesso aos dados, sendo afetadas operações em caracteres e inteligentes de acesso a dados.
Entretanto, a performance de leitura/gravação de blocos é melhorada consideravelmente após a adoção do LVM. O LVM também garante que o sistema não mostre sintomas de paradas durante o esvaziamento de cache de disco, mantendo sempre uma certa constância na transferência de dados mesmo em operações pesadas de I/O no disco. Depende de você avaliar estes pontos e considerar sua adoção.
Nesta seção não tenho a intenção de cobrir todos os detalhes técnicos da implantação do LVM, a idéia aqui é fornecer uma referência básica e prática para uso em qualquer sistema normal (desconsiderando usos críticos). A idéia aqui é mostrar de forma prática como implantar LVM em sua máquina e preparar seu uso nos discos.
Antes de começar, retire QUALQUER CD que estiver inserido na unidade de CD-ROM, pois eles podem causar erro no pvscan, pvdisplay, etc.
No particionamento, defina as partições do tipo 8E (Linux LVM). A partição Linux LVM é exatamente igual a Linux Native (82), a única vantagem é que o LVM utilizará auto detecção para saber quais partições ele deve utilizar no pvscan.
Instale o pacote lvm10 e uma imagem de kernel 2.4 que tenha suporte a LVM, ou compile seu próprio kernel (caso goste de máquinas turbinadas :-)
Execute o pvscan para detectar as partições marcadas como LVM e criar sua configuração em /etc/lvmtab.d.
OBS: É normal o sistema procurar dispositivos de CD-ROM durante a execução do pvscan, apenas não deixe um CD na unidade para evitar grandes sustos se estiver desatento com os passos :-)
Rode o pvcreate no disco ou partição para dizer que ela será um volume físico do LVM: pvcreate /dev/hda1 ou pvcreate /dev/hda
Em caso de dúvida sobre qual é a partição LVM, digite: fdisk -l /dev/hda (supondo que /dev/hda é o disco rígido que está configurando o LVM).
Rode o pvdisplay /dev/hda1 para verificar se o volume físico foi criado. Recomendo que deixe a partição raíz (/) de fora do LVM para não ter futuros problemas com a manutenção do seu sistema, a menos que tenha muitas opções de inicialização com suporte a LVM em mãos, ou algo mais complexo baseado em initrd :-)
Crie o grupo de volume na partição vgcreate lvmdisk /dev/hda1 /dev/hdb7... Note que partições de discos diferentes podem fazer parte de um mesmo grupo de volume (VG) do LVM. Caso use o devfs, será preciso usar o caminho completo do dispositivo ao invés do link: vgcreate lvmdisk /dev/ide/host0/bus0/target0/lun0/part1
O valor padrão do "Phisical Extend" é de 4MB mas pode ser alterado pelo parâmetro "-s tamanho", assim o tamanho máximo do grupo de volume será de 256GB (4MB * 64.000 extends que são suportados por volume lógico). Os valores do Phisical Extend (PE) pode ser de 8k a 16GB. Não é possível modificar o tamanho do PE após ele ser definido.
Verifique o grupo de volume (VG) recém criado com o comando: vgdisplay ou vgdisplay /dev/hda6. Atente para a linha "Free PE / tamanho", que indica o espaço livre restante para criar os volumes lógicos (LV).
Crie o volume lógico (LV) com o comando: lvcreate -L1500 -ntmp lvmdisk Que vai criar uma partição LVM de 1500MB (1,5GB) com o nome tmp (acessível por /var/lvmdisk/tmp) dentro do grupo lvmdisk. Você deverá fazer isso com as outra partições.
Agora resta criar um sistema de arquivos (ext3, reiserfs, xfs, jfs, etc) como faria com qualquer partição física normal:
mkfs.ext3 /dev/lvmdisk/tmp mkfs.reiserfs /dev/lvmdisk/tmp
OBS: Caso deseje montar automaticamente o volume LVM, coloque o caminho completo do LVM ao invés do volume físico no /etc/fstab: /dev/lvmdisk/tmp.
O processo para aumentar o tamanho do volume lógico consiste em primeiro aumentar o tamanho do VG com o lvextend e depois ajustar o tamanho do sistema de arquivos:
# Aumenta o espaço do volume lógico tmp para 1G
lvextend -L1G /dev/lvmdisk/tmp
# Aumenta em 200MB o espaço no volume lógico tmp
lvextend -L 200M /dev/lvmdisk/tmp
As unidades Kk,Mm,Gg,Tt podem ser usadas para especificar o espaço. Após modificar o volume lógico, será preciso aumentar o tamanho do sistema de arquivos para ser exatamente igual ao tamanho do LV. Isto depende do seu sistema de arquivos:
ext2/3
resize2fs /dev/lvmdisk/tmp
O ext2/3 ainda vem com o utilitário e2fsadm que executa os dois comandos (lvextend e resize2fs) de uma só vez: e2fsadm -L 1G /dev/lvmdisk/tmp
OBS: Você deverá desmontar o sistema de arquivos antes de alterar o tamanho de um sistema de arquivos ext2 ou ext3. Para alterar o tamanho durante a execução do sistema operacional, é necessária a aplicação do patch ext2online no kernel.
reiserfs
resize_reiserfs -f /dev/lvmdisk/tmp
O tamanho do sistema de arquivos reiserfs poderá ser modificado on-line, assim não precisa parar seu servidor para esta operação.
xfs
xfs_growfs /tmp
Note que deve ser especificado o ponto de montagem ao invés do dispositivo. O sistema de arquivos deverá ser montado antes de ser modificado e incluido no /etc/fstab.
Para diminuir o tamanho de um volume lógico, certifique-se de ter calculado o espaço corretamente para acomodar todos os dados que já existem na partição. A diferença para o processo de aumentar o LV é que neste o sistema de arquivos é reduzido primeiro e depois o LV:
ext2/3
e2fsadm -L-1G /dev/lvmdisk/tmp
Você também poderá usar o resize2fs e depois o lvreduce, mas deverá dizer o tamanho em blocos para o resize2fs que varia de acordo com o tamanho do sistema de arquivos:
OBS: Você deverá desmontar o sistema de arquivos antes de alterar o tamanho do sistema de arquivos, a não ser que tenha o patch ext2online aplicado no kernel.
Para formatar disquetes para serem usados no GNU/Linux use o comando:
mkfs.ext2 [-c] [/dev/fd0]
Em alguns sistemas você deve usar mke2fs no lugar de mkfs.ext2. A opção -c faz com que o mkfs.ext2 procure por blocos danificados no disquete e /dev/fd0 especifica a primeira unidade de disquetes para ser formatada (equivalente a A: no DOS). Mude para /dev/fd1 para formatar um disquete da segunda unidade.
OBS: Este comando cria um sistema de arquivos ext2 no disquete que é nativo do GNU/Linux e permite usar características como permissões de acesso e outras. Isto também faz com que o disquete NÃO possa ser lido pelo DOS/Windows. Para formatar um disquete no GNU/Linux usando o FAT12 (compatível com o DOS/Windows) veja próxima seção.
Exemplo: mkfs.ext2 -c /dev/fd0
Formatando disquetes compatíveis com o DOS/Windows
A formatação de disquetes DOS no GNU/Linux é feita usando o comando superformat que é geralmente incluído no pacote mtools. O superformat formata (cria um sistema de arquivos) um disquete para ser usado no DOS e também possui opções avançadas para a manipulação da unidade, formatação de intervalos de cilindros específicos, formatação de discos em alta capacidade e verificação do disquete.
superformat [opções] [dispositivo]
dispositivo
Unidade de disquete que será formatada. Normalmente /dev/fd0 ou /dev/fd1 especificando respectivamente a primeira e segunda unidade de disquetes.
opções
-v [num]
Especifica o nível de detalhes que serão exibidos durante a formatação do disquete. O nível 1 especifica um ponto mostrado na tela para cada trilha formatada. Veja a página de manual do superformat para detalhes.
-superverify
Verifica primeiro se a trilha pode ser lida antes de formata-la. Este é o padrão.
--dosverify, -B
Verifica o disquete usando o utilitário mbadblocks. Usando esta opção, as trilhas defeituosas encontradas serão automaticamente marcadas para não serem utilizadas.
--verify_later, -V
Verifica todo o disquete no final da formatação.
--noverify, -f
Não faz verificação de leitura.
-b [trilha]
Especifica a trilha inicial que será formatada. O padrão é 0.
-e [trilha]
Especifica a trilha final que será formatada.
Na primeira vez que o superformat é executado, ele verifica a velocidade de rotação da unidade e a comunicação com a placa controladora, pois os discos de alta densidade são sensíveis a rotação da unidade. Após o teste inicial ele recomendará adicionar uma linha no arquivo /etc/driveprm como forma de evitar que este teste seja sempre executado. OBS: Esta linha é calculada de acordo com a rotação de usa unidade de disquetes, transferência de dados e comunicação com a placa controladora de disquete. Desta forma ela varia de computador para computador Note que não é necessário montar a unidade de disquetes para formata-la.
Segue abaixo exemplos de como formatar seus disquetes com o superformat:
superformat /dev/fd0 - Formata o disquete na primeira unidade de disquetes usando os valores padrões.
superformat /dev/fd0 dd - Faz a mesma coisa que o acima, mas assume que o disquete é de Dupla Densidade (720Kb).
superformat -v 1 /dev/fd0 - Faz a formatação da primeira unidade de disquetes (/dev/fd0) e especifica o nível de detalhes para 1, exibindo um ponto após cada trilha formatada.
Além de programas de formatação em modo texto, existem outros para ambiente gráfico (X11) que permitem fazer a mesma tarefa.
Entre os diversos programas destaco o gfloppy que além de permitir selecionar se o disquete será formatado para o GNU/Linux (ext2) ou DOS (FAT12), permite selecionar a capacidade da unidade de disquetes e formatação rápida do disco.
O GNU/Linux acessa as partições existente em seus discos rígidos e disquetes através de diretórios. Os diretórios que são usados para acessar (montar) partições são chamados de Pontos de Montagem. Para detalhes sobre montagem de partições, veja [#s-disc-montagem Montando (acessando) uma partição de disco, Seção 5.13].
No DOS cada letra de unidade (C:, D:, E:) identifica uma partição de disco, no GNU/Linux os pontos de montagem fazem parte da grande estrutura do sistema de arquivos raiz.
Existem muitas vantagens de se usar pontos de montagem ao invés de unidade de disco para identificar partições (método usado no DOS):
Você pode montar a partição no diretório que quiser.
Em caso de um sistema de arquivos cheio, você pode copiar o conteúdo de um grande diretório para um disco separado, apagar o conteúdo do diretório original e montar o disco onde foram copiados os arquivos naquele local (caso não use um sistema de LVM).
O uso de pontos de montagem torna o gerenciamento mais flexível.
A adição de novas partições ou substituição de discos rígidos não afeta a ordem de identificação dos discos e pontos de montagem (como não acontece no DOS).
Identificação de discos e partições em sistemas Linux
No GNU/Linux, os dispositivos existentes em seu computador (como discos rígidos, disquetes, tela, portas de impressora, modem, etc) são identificados por um arquivo referente a este dispositivo no diretório /dev.
A identificação de discos rígidos no GNU/Linux é feita da seguinte forma:
/dev/hda1
| | ||
| | ||_Número que identifica o número da partição no disco rígido.
| | |
| | |_Letra que identifica o disco rígido (a=primeiro, b=segundo, etc...).
| |
| |_Sigla que identifica o tipo do disco rígido (hd=ide, sd=SCSI, xt=XT).
|
|_Diretório onde são armazenados os dispositivos existentes no sistema.
Abaixo algumas identificações de discos e partições em sistemas Linux:
/dev/fd0 - Primeira unidade de disquetes.
/dev/fd1 - Segunda unidade de disquetes.
/dev/hda - Primeiro disco rígido na primeira controladora IDE do micro (primary master).
/dev/hda1 - Primeira partição do primeiro disco rígido IDE.
/dev/hdb - Segundo disco rígido na primeira controladora IDE do micro (primary slave).
/dev/hdb1 - Primeira partição do segundo disco rígido IDE.
/dev/sda - Primeiro disco rígido na primeira controladora SCSI ou SATA.
/dev/sda1 - Primeira partição do primeiro disco rígido SCSI ou SATA.
/dev/sdb - Segundo disco rígido na primeira controladora SCSI ou SATA.
/dev/sdb1 - Primeira partição do segundo disco rígido SCSI ou SATA.
/dev/sr0 - Primeiro CD-ROM SCSI.
/dev/sr1 - Segundo CD-ROM SCSI.
/dev/xda - Primeiro disco rígido XT.
/dev/xdb - Segundo disco rígido XT.
As letras de identificação de discos rígidos podem ir além de hdb, em meu micro, por exemplo, a unidade de CD-ROM está localizada em /dev/hdg (Primeiro disco - quarta controladora IDE).
É importante entender como os discos e partições são identificados no sistema, pois será necessário usar os parâmetros corretos para monta-los.
Você pode acessar uma partição de disco usando o comando mount.
mount [dispositivo] [ponto de montagem] [opções]
Onde:
dispositivo
Identificação da unidade de disco/partição que deseja acessar (como /dev/hda1 (disco rígido) ou /dev/fd0 (primeira unidade de disquetes).
ponto de montagem
Diretório de onde a unidade de disco/partição será acessado. O diretório deve estar vazio para montagem de um sistema de arquivo. Normalmente é usado o diretório /mnt para armazenamento de pontos de montagem temporários.
-t [tipo]
Tipo do sistema de arquivos usado pelo dispositivo. São aceitos os sistemas de arquivos:
ext2 - Para partições GNU/Linux usando o Extended File System versão 2 (a mais comum).
ext3 - Para partições GNU/Linux usando o Extended File System versão 3, com suporte a journaling.
reiserfs - Para partições reiserfs, com suporte a journaling.
xfs - Para partições xfs, com suporte a journaling.
vfat - Para partições Windows 95 que utilizam nomes extensos de arquivos e diretórios.
msdos - Para partições DOS normais.
iso9660 - Para montar unidades de CD-ROM. É o padrão.
umsdos - Para montar uma partição DOS com recursos de partições EXT2, como permissões de acesso, links, etc.
Para mais detalhes sobre opções usadas com cada sistema de arquivos, veja a página de manual mount.
-r
Caso for especificada, monta a partição somente para leitura.
-w
Caso for especificada, monta a partição como leitura/gravação. É o padrão.
Existem muitas outras opções que podem ser usadas com o comando mount, mas aqui procurei somente mostrar o básico para "montar" seus discos e partições no GNU/Linux (para mais opções, veja a página de manual do mount). Caso você digitar mount sem parâmetros, serão mostrados os sistemas de arquivos atualmente montados no sistema. Esta mesma listagem pode ser vista em /etc/mtab. A remontagem de partição também é muito útil, especialmente após reparos nos sistema de arquivos do disco rígido. Veja alguns exemplos de remontagem abaixo.
É necessário permissões de root para montar partições, a não ser que tenha especificado a opção user no arquivo /etc/fstab (veja [#s-disc-fstab fstab, Seção 5.14.1]).
Exemplo de Montagem:
Montar uma partição Windows (vfat) de /dev/hda1 em /mnt somente para leitura: mount /dev/hda1 /mnt -r -t vfat
Montar a primeira unidade de disquetes /dev/fd0 em /floppy: mount /dev/fd0 /floppy -t vfat
Montar uma partição DOS localizada em um segundo disco rígido /dev/hdb1 em /mnt: mount /dev/hdb1 /mnt -t msdos.
Remontar a partição raíz como somente leitura: mount -o remount,rw /
Remontar a partição raíz como leitura/gravação (a opção -n é usada porque o mount não conseguirá atualizar o arquivo /etc/mtab devido ao sistema de arquivos / estar montado como somente leitura atualmente: mount -n -o remount,rw /.
O arquivo /etc/fstab permite que as partições do sistema sejam montadas facilmente especificando somente o dispositivo ou o ponto de montagem. Este arquivo contém parâmetros sobre as partições que são lidos pelo comando mount. Cada linha deste arquivo contém a partição que desejamos montar, o ponto de montagem, o sistema de arquivos usado pela partição e outras opções. fstab tem a seguinte forma:
Diretório do GNU/Linux onde a partição montada será acessada.
Tipo
Tipo de sistema de arquivos usado na partição que será montada. Para partições GNU/Linux use ext2, para partições DOS (sem nomes extensos de arquivos) use msdos, para partições Win 95 (com suporte a nomes extensos de arquivos) use vfat, para unidades de CD-ROM use iso9660.
Opções
Especifica as opções usadas com o sistema de arquivos. Abaixo, algumas opções de montagem para ext2/3 (a lista completa pode ser encontrada na página de manual do mount):
defaults - Utiliza valores padrões de montagem.
noauto - Não monta os sistemas de arquivos durante a inicialização (útil para CD-ROMS e disquetes).
ro - Monta como somente leitura.
user - Permite que usuários montem o sistema de arquivos (não recomendado por motivos de segurança).
sync é recomendado para uso com discos removíveis (disquetes, zip drives, etc) para que os dados sejam gravados imediatamente na unidade (caso não seja usada, você deve usar o comando [ch-cmdv.html#s-cmdv-sync sync, Seção 10.22] antes de retirar o disquete da unidade.
dump
Especifica a frequência de backup feita com o programa dump no sistema de arquivos. 0 desativa o backup.
Ordem
Define a ordem que os sistemas de arquivos serão verificados na inicialização do sistema. Se usar 0, o sistema de arquivos não é verificado. O sistema de arquivos raíz que deverá ser verificado primeiro é o raíz "/" (a não ser que você tenha um sistema de arquivos de outro tipo que não é montado dentro do diretório raíz e possui seu suporte embutido no kernel) .
Após configurar o /etc/fstab, basta digitar o comando mount /dev/hdg ou mount /cdrom para que a unidade de CD-ROM seja montada. Você deve ter notado que não é necessário especificar o sistema de arquivos da partição pois o mount verificará se ele já existe no /etc/fstab e caso existir, usará as opções especificadas neste arquivo. Para maiores detalhes veja as páginas de manual fstab e mount.
5.14.1 fstab O arquivo /etc/fstab permite que as partições do sistema sejam montadas facilmente especificando somente o dispositivo ou o ponto de montagem. Este arquivo contém parâmetros sobre as partições que são lidos pelo comando mount. Cada linha deste arquivo contém a partição que desejamos montar, o ponto de montagem, o sistema de arquivos usado pela partição e outras opções. fstab tem a seguinte forma:
Onde: Sistema de Arquivos Partição que deseja montar. Ponto de montagem Diretório do GNU/Linux onde a partição montada será acessada. Tipo Tipo de sistema de arquivos usado na partição que será montada. Para partições GNU/Linux use ext2, para partições DOS (sem nomes extensos de arquivos) use msdos, para partições Win 95 (com suporte a nomes extensos de arquivos) use vfat, para unidades de CD-ROM use iso9660. Opções Especifica as opções usadas com o sistema de arquivos. Abaixo, algumas opções de montagem para ext2/3 (a lista completa pode ser encontrada na página de manual do mount): defaults - Utiliza valores padrões de montagem. noauto - Não monta os sistemas de arquivos durante a inicialização (útil para CD-ROMS e disquetes). ro - Monta como somente leitura. user - Permite que usuários montem o sistema de arquivos (não recomendado por motivos de segurança). sync é recomendado para uso com discos removíveis (disquetes, zip drives, etc) para que os dados sejam gravados imediatamente na unidade (caso não seja usada, você deve usar o comando sync, Seção 10.22 antes de retirar o disquete da unidade. dump Especifica a frequência de backup feita com o programa dump no sistema de arquivos. 0 desativa o backup. Ordem Define a ordem que os sistemas de arquivos serão verificados na inicialização do sistema. Se usar 0, o sistema de arquivos não é verificado. O sistema de arquivos raíz que deverá ser verificado primeiro é o raíz "/" (a não ser que você tenha um sistema de arquivos de outro tipo que não é montado dentro do diretório raíz e possui seu suporte embutido no kernel) . Após configurar o /etc/fstab, basta digitar o comando mount /dev/hdg ou mount /cdrom para que a unidade de CD-ROM seja montada. Você deve ter notado que não é necessário especificar o sistema de arquivos da partição pois o mount verificará se ele já existe no /etc/fstab e caso existir, usará as opções especificadas neste arquivo. Para maiores detalhes veja as páginas de manual fstab e mount.
Para desmontar um sistema de arquivos montado com o comando umount, use o comando umount. Você deve ter permissões de root para desmontar uma partição.
umount [dispositivo/ponto de montagem]
Você pode tanto usar umount /dev/hda1 como umount /mnt para desmontar um sistema de arquivos /dev/hda1 montado em /mnt.
Observação: O comando umount executa o sync automaticamente no momento da desmontagem para garantir que todos os dados ainda não gravados serão salvos.= Guia Foca GNU/Linux Capítulo 6 - Gerenciadores de Partida (boot loaders) =
Gerenciadores de Partida são programas que carregam um sistema operacional e/ou permitem escolher qual será iniciado. Normalmente este programas são gravados no setor de boot (inicialização) da partição ativa ou no master boot record (MBR) do disco rígido.
Este capitulo explica o funcionamento de cada um dos principais gerenciadores de partida usados no GNU/Linux, em que situações é recomendado seu uso, as características, como configura-lo e alguns exemplos de configuração.
Gerenciadores de Partida são programas que carregam um sistema operacional e/ou permitem escolher qual será iniciado. Normalmente este programas são gravados no setor de boot (inicialização) da partição ativa ou no master boot record (MBR) do disco rígido.
Este capitulo explica o funcionamento de cada um dos principais gerenciadores de partida usados no GNU/Linux, em que situações é recomendado seu uso, as características, como configura-lo e alguns exemplos de configuração.
O LILO (Linux Loader) é sem dúvida o gerenciador de partida padrão para quem deseja iniciar o GNU/Linux através do disco rígido. Ele permite selecionar qual sistema operacional será iniciado (caso você possua mais de um) e funciona tanto em discos rígidos IDE como SCSI.
A seleção de qual sistema operacional e a passagem de parâmetros ao kernel pode ser feita automaticamente ou usando o aviso de boot: do LILO.
Os dados para a criação do novo setor de boot que armazenará o gerenciador de partida são lidos do arquivo /etc/lilo.conf Este arquivo pode ser criado em qualquer editor de textos (como o ae ou vi). Normalmente ele é criado durante a instalação de sua distribuição GNU/Linux mas por algum motivo pode ser preciso modifica-lo ou personaliza-lo (para incluir novos sistemas operacionais, mensagens, alterar o tempo de espera para a partida automática, etc).
O arquivo /etc/lilo.conf é dividido em duas seções: Geral e Imagens. A seção Geral vem no inicio do arquivo e contém opções que serão usadas na inicialização do Lilo e parâmetros que serão passados ao kernel. A seção Imagens contém opções especificas identificando qual a partição que contém o sistema operacional, como será montado inicialmente o sistema de arquivos, tabela de partição, o arquivo que será carregado na memória para inicializar o sistema, etc. Abaixo um modelo do arquivo /etc/lilo.conf para sistemas que só possuem o GNU/Linux instalado:
Para criar um novo gerenciador de partida através do arquivo /etc/lilo.conf , execute o comando lilo.
No exemplo acima, o gerenciador de partida será instalado em /dev/hda1 (veja [ch-disc.html#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12]) , utilizará um setor de boot compacto (compact), modo de vídeo VGA normal (80x25), esperará 2 segundos antes de processar automaticamente a primeira seção image= e carregará o kernel /vmlinux de /dev/hda1. Para detalhes sobre opções que podem ser usadas neste arquivo veja [#s-boot-lilo-opcoes Opções usadas no LILO, Seção 6.1.2].
Para mostrar o aviso de boot:, você deverá ligar as teclas Caps Lock ou Scrool lock na partida ou pressionar a tecla Shift durante os dois segundos de pausa. Outro método é incluir a opção prompt na seção global para que o aviso de boot: seja mostrado automaticamente após carregar o Lilo.
Abaixo uma configuração para computadores com mais de um sistema operacional (Usando GNU/Linux e DOS):
O exemplo acima é idêntico ao anterior, o que foi acrescentado foi a opção prompt na seção geral (para que seja mostrado imediatamente o aviso de boot: no momento em que o LILO for carregado), e incluída uma imagem de disco DOS localizado em /dev/hda2. No momento da inicialização é mostrada a mensagem boot: e caso seja digitado DOS e pressionado ENTER, o sistema iniciará o DOS. Caso a tecla Enter seja pressionada sem especificar a imagem, a primeira será carregada (neste caso o GNU/Linux).
Você pode substituir a palavra GNU/Linux da opção label por o número 1 e DOS por 2, desta forma o número pode ser digitado para iniciar o sistema operacional. Isto é muito útil para construir um menu usando a opção message. Para detalhes veja [#s-boot-lilo-opcoes Opções usadas no LILO, Seção 6.1.2].
A seção Geral vem do inicio do arquivo até a palavra delay=20. A partir do primeiro aparecimento da palavra image, other ou range, tudo o que vier abaixo será interpretado como imagens de inicialização.
Por padrão, a imagem carregada é a especificada por default= ou a primeira que aparece no arquivo (caso default= não seja especificado). Para carregar o outro sistema (o DOS), digite o nome da imagem de disco no aviso de boot: (especificada em label=) que será carregada. Você também pode passar parâmetros manualmente ao kernel digitando o nome da imagem de disco e uma opção do kernel ou através do arquivo /etc/lilo.conf (veja [#s-boot-lilo-opcoes Opções usadas no LILO, Seção 6.1.2]).
O LILO pode inicializar o seguintes tipos de imagens:
Imagens do kernel de um arquivo. Normalmente usado para iniciar o GNU/Linux pelo disco rígido e especificado pelo parâmetro image=.
Imagens do kernel de um dispositivo de bloco (como um disquete). Neste caso o número de setores a serem lidos devem ser especificados na forma PRIMEIRO-ÚLTIMO ou PRIMEIRO NÚMERO de setores a serem lidos.
É necessário especificar o parâmetro image= e range=, por exemplo:
image=/dev/fd0
range=1 512
Todas as opções do kernel podem ser usadas na inicialização por dispositivo.
O setor de boot de outro sistema operacional (como o DOS, OS/2, etc). O setor de partida é armazenado junto com a tabela de partição no arquivo /boot/map. É necessário especificar o parâmetro OTHER=dispositivo ou OTHER=arquivo e a inicialização através de um setor de partida possui algumas opções especiais como o TABLE= (para especificar a tabela de partição) e o MAP-DRIVE= (identificação da unidade de discos pelo sistema operacional). Veja o exemplo desta configuração abaixo:
other=/dev/hda2
table=/dev/hda
label=DOS
map-drive=0x80
to = 0x81
map-drive=0x81
to = 0x80
Observações:
Caso o gerenciador de partida seja instalado no MBR do disco rígido (boot=/dev/hda), o setor de boot do antigo sistema operacional será substituído, retire uma cópia do setor de boot para um disquete usando o comando dd if=/dev/hda of=/floppy/mbr bs=512 count=1 no GNU/Linux para salvar o setor de boot em um disquete e dd if=/floppy/mbr of=/dev/hda bs=446 count=1 para restaura-lo. No DOS você pode usar o comando fdisk /mbr para criar um novo Master Boot Record.
Após qualquer modificação no arquivo /etc/lilo.conf , o comando lilo deverá ser novamente executado para atualizar o setor de partida do disco rígido. Isto também é válido caso o kernel seja atualizado ou a partição que contém a imagem do kernel desfragmentada.
A limitação de 1024 cilindros do Lilo não existe mais a partir da versão 21.4.3 (recomendada, por conter muitas correções) e superiores.
A reinstalação, formatação de sistemas DOS e Windows pode substituir o setor de partida do HD e assim o gerenciador de partida, tornando impossível a inicialização do GNU/Linux. Antes de reinstalar o DOS ou Windows, verifique se possui um disquete de partida do GNU/Linux.
Para gerar um novo boot loader, coloque o disquete na unidade e após o aviso boot: ser mostrado, digite linux root=/dev/hda1 (no lugar de /dev/hda1 você coloca a partição raiz do GNU/Linux), o sistema iniciará. Dentro do GNU/Linux, digite o comando lilo para gerar um novo setor de partida.
Agora reinicie o computador, tudo voltará ao normal.
Esta seção traz opções úteis usadas no arquivo lilo.conf com explicações sobre o que cada uma faz. As opções estão divididas em duas partes: As usadas na seção Global e as da seção Imagens do arquivo lilo.conf.
Global
backup=[arquivo/dispositivo] - Copia o setor de partida original para o arquivo ou dispositivo especificado.
boot=dispositivo - Define o nome do dispositivo onde será gravado o setor de partida do LILO (normalmente é usada a partição ativa ou o Master Boot Record - MBR). Caso não seja especificado, o dispositivo montado como a partição raiz será usado.
compact - Tenta agrupar requisições de leitura para setores seguintes ao sendo lido. Isto reduz o tempo de inicialização e deixa o mapa menor. É normalmente recomendado em disquetes.
default=imagem - Usa a imagem especificada como padrão ao invés da primeira encontrada no arquivo lilo.conf.
delay=[num] - Permite ajustar o número de segundos (em décimos de segundos) que o gerenciador de partida deve aguardar para carregar a primeira imagem de disco (ou a especificada por default=). Esta pausa lhe permite selecionar que sistema operacional será carregado.
install=interface - Especifica que interface será usada para exibição de menu com as opções de inicialização ao usuário. As seguintes opções são permitidas:
text - Exibe uma mensagem de texto (exibida através do parâmetro message=) na tela. Esta é a recomendada para terminais.
menu - Exibe um menu que lhe permite selecionar através de uma interface de menu a opção de inicialização. Esta é a padrão.
bmp - Exibe um bitmap gráfico com a resolução de 640x480 com 16 ou 256 cores.
lba32 - Permite que o LILO quebre o limite de 1024 cilindros do disco rígido, inicializando o GNU/Linux em um cilindro acima deste através do acesso . Note que isto requer compatibilidade com o BIOS, mais especificamente que tenha suporte a chamadas int 0x13 e AH=0x42. É recomendado o seu uso.
map=arquivo-mapa - Especifica a localização do arquivo de mapa (.map). Se não for especificado, /boot/map é usado.
message=arquivo - Especifica um arquivo que contém uma mensagem que será mostrada antes do aviso de boot:. Nenhuma mensagem é mostrada até que seja pressionada a tecla Shift após mostrar a palavra LILO. O tamanho da mensagem deve ser no máximo 65535 bytes. O arquivo de mapa deve ser novamente criado caso a mensagem seja retirada ou modificada. Na mensagem, o caracter FF (CTRL L) limpa a tela.
nowarn - Não mostra mensagens de alerta.
password=senha - Permite proteger todas as imagens de disco com uma única senha. Caso a senha esteja incorreta, o LILO é novamente carregado.
prompt - Mostra imediatamente o aviso de boot: ao invés de mostrar somente quando a tecla Shift é pressionada.
verbose=[num] - Ativa mensagens sobre o processamento do LILO. Os números podem ser especificados de 1 a 5, quanto maior o número, maior a quantidade de detalhes mostrados.
timeout=[num] - Ajusta o tempo máximo de espera (em décimos de segundos) de digitação no teclado. Se nenhuma tecla é pressionada no tempo especificado, a primeira imagem é automaticamente carregada. Igualmente a digitação de senha é interrompida se o usuário estiver inativo por este período.
Adicionalmente as opções de imagem do kernel append, ramdisk, read-only, read-write, root e vga podem ser especificadas na seção global. Opções por Imagem
As opções por imagem iniciam com uma das seguintes opções: image=, other= ou range=. Opções usadas por cada imagem:
table=dispositivo - Indica o dispositivo que contém a tabela de partição para aquele dispositivo. Necessário apenas para imagens especificadas por other=.
unsafe - Não acessa o setor de boot no momento da criação do mapa. Isto desativa algumas checagens, como a checagem da tabela de partição. unsafe e table= são incompatíveis.
label=[nome] - Permite especificar um nome para a imagem. Este nome será usado na linha boot: para inicializar o sistema.
alias=[nome] - Apelido para a imagem de disco. É como um segundo label.
optional - Ignora a imagem caso não estiver disponível no momento da criação do mapa. É útil para especificar kernels que não estão sempre presentes no sistema.
password=senha - Protege a imagem atual com a senha. Caso a senha esteja incorreta, o setor de partida do Lilo é novamente carregado.
restricted - A senha somente é pedida para iniciar a imagem se o sistema for iniciado no modo single.
Também podem ser usados parâmetros de inicialização do kernel no arquivo /etc/lilo.conf, veja a seção [#s-boot-kernelparam Parâmetros de inicialização passados ao kernel, Seção 6.3] para maiores detalhes.
Abaixo um exemplo do arquivo /etc/lilo.conf que poderá ser usado em instalações GNU/Linux com o DOS.
boot=/dev/hda1 #Instala o LILO em /dev/hda1
compact
install=menu
map=/boot/map
message=/etc/lilo.message #mensagem que será mostrada na tela
default=1 #Carrega a Imagem especificada por label=1 como padrão
vga=normal #usa o modo de video 80x25 ao iniciar o Linux
delay=20 #aguarda 2 segundos antes de iniciar a imagem padrão
lba32 #permite quebrar o limite de 1024 cilindros na inicialização
prompt #mostra o aviso de "boot:" logo que o LILO é carregado
image=/vmlinuz #especifica o arquivo que contém a primeira imagem
root=/dev/hda1 #partição onde a imagem acima esta localizada
label=1 #identificação da imagem de disco
read-only #monta inicialmente como somente leitura
password=12345 #Usa a senha 12345
restricted #somente quando iniciar com o parâmetro single
other=/dev/hda2 #especifica outro sistema que será carregado
table=/dev/hda #a tabela de partição dele está em /dev/hda
label=2 #identificação desta imagem de disco
password=12345 #pede a senha antes de iniciar este sistema
Você pode usar o exemplo acima como base para construir sua própria configuração personalizada do /etc/lilo.conf mas não se esqueça de modificar as tabelas de partições para seu sistema. Se você usa o Windows NT 4.0, Windows NT 5.0 (Windows 2000) ou o OS/2, recomendo ler o DOS Windows OS/2-HOWTO.
Após criar seu arquivo /etc/lilo.conf , execute o comando lilo e se tudo ocorrer bem, o LILO será instalado.
(Os detalhes contidos na seção sobre o GRUB, foram integralmente desenvolvidos por Alexandre Costa alebyte@bol.com.br como contribuição ao guia FOCA GNU/Linux.)
O GRUB (Grand Unified Boot Loader) é mais uma alternativa como gerenciador de boot e apresenta alguns recursos extras com relação as outras opções disponíveis. Ele é flexível, funcional e poderoso, podendo inicializar sistemas operacionais como o Windows (9x, ME, NT, 2000 e XP), Dos, Linux, GNU Hurd, *BSD, OS/2 e etc. Podemos destacar também o suporte aos sistemas de arquivos ext2 (Linux), ext3 e reiserfs (novos sistemas de arquivos journaling do Linux), FAT16 e FAT32 (Win 9x/ME), FFS (Fast File System usado no *BSD), minix (MINIX OS) e etc.
Por utilizar o padrão Multiboot ele é capaz de carregar diversas imagens de boot e módulos. Por esse motivo ele é o único gerenciador de inicialização capaz de carregar o conjunto de servidores do GNU Hurd. O GRUB também permite buscar imagens do kernel pela rede, por cabo seriais, suporta discos rígidos IDE e SCSI, detecta toda a memória RAM disponível no sistema, tem interface voltada para linha de comandos ou menus de escolha, além de suportar sistemas sem discos e terminais remotos.
Como possui inúmeros recursos, será apresentada sua utilização básica, ficando como sugestão ao leitor procurar se aprofundar mais em suas possibilidades de uso e configuração.
O GRUB trabalha com uma notação diferente para apontar discos e partições sendo necessário algumas explicações antes de prosseguir. Veja a tabela comparativa:
No Linux No GRUB
/dev/hda (hd0)
/dev/hda1 (hd0,0)
/dev/hda2 (hd0,1)
/dev/hdb (hd1)
/dev/hdb1 (hd1,0)
/dev/hdb2 (hd1,1)
/dev/sda (hd0) # Disco SCSI ID 0
/dev/sda1 (hd0,0) # Disco SCSI ID 0, partição 1
/dev/sda2 (hd0,1) # Disco SCSI ID 0, partição 2
/dev/sdb (hd1) # Disco SCSI ID 1
/dev/sdb1 (hd1,0) # Disco SCSI ID 1, partição 1
/dev/sdb2 (hd1,1) # Disco SCSI ID 1, partição 2
/dev/fd0 (fd0)
OBS: Os discos IDE e SCSI são referenciados ambos como (hd?) pelo GRUB. Não há distinção entre os discos e de modo geral a identificação de unidades IDE é menor do que qualquer tipo de drive SCSI, salvo se você alterar a sequência de inicialização (boot) na BIOS.
Para saber como o Linux trabalha com partições veja [ch-disc.html#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12].
Instalando o GRUB (legacy, como ficou conhecido, após o advento do GRUB 2)
A instalação do GRUB ao contrário da instalação do LILO ([#s-boot-lilo LILO, Seção 6.1]), só precisa ser executada uma única vez. Caso seja necessária alguma mudança como por exemplo adicionar uma nova imagem, esta pode ser feita apenas editando o arquivo de configuração menu.lst.
Um método simples de adicionar o GRUB para gerenciar seu MBR (Master Boot Record) é rodando o seguinte comando (como superusuário):
# /sbin/grub-install /dev/hda
Este comando grava o GRUB no MBR do primeiro disco e cria o diretório /boot/grub onde estarão os arquivos necessários para o seu funcionamento. Neste ponto o GRUB já está instalado e quando você reiniciar seu computador irá se deparar com uma linha de comandos, onde terá que carregar a imagem do kernel manualmente. Mais adiante será explorada a utilização desta linha de comando que é muito eficiente.
Provavelmente você achará mais interessante copiar o arquivo de configuração de exemplos do GRUB e otimizá-lo í s suas necessidades. Note que isto não exclui a possibilidade de utilizar a linha de comando, apenas cria uma interface de menus onde você pode configurar várias opções de boot de uma forma organizada, automatizada e funcional. Copie este arquivo para o diretório /boot/grub com o seguinte comando:
Quando criamos um disquete de partida, este funcionará em um sistema qualquer, podendo utilizar este disquete em várias máquinas diferentes ou em uma máquina em que tenha tido algum problema com o GRUB no MBR. Coloque um disquete virgem e digite os seguintes comandos:
Quando foi criado o disquete de partida anteriormente, este só nos permitia utilizar a linha de comando sendo necessário carregar o menu.lst pelo disco rígido (o qual deve estar presente). Em alguns casos este disco satisfaz as necessidades básicas mas pode haver um momento em que você deseje ter um disquete que funcione com vários sistema e não dependa de um disco fixo.
Este último comando disponibiliza a linha de comando do GRUB. Digite os seguintes comandos:
grub> install (fd0)/grub/stage1 d (fd0) (fd0)/grub/stage2 p (fd0)/grub/menu.lst
grub> quit
Neste momento o disquete está pronto. Note que o menu.lst que foi copiado para ele é um arquivo de exemplo, sendo necessário que você o configure de acordo com suas necessidades.
Esta seção descreve o arquivo menu.lst com explicações sobre as opções mais usadas. Este arquivo é dividido em parâmetros Globais, que afetam o arquivo todo e parâmetros que só tem efeito para as imagens do sistema que será carregado. Algumas opções podem ser passadas para o kernel do Linux no momento do boot, algumas delas também serão detalhadas.
Parâmetros Globais
:* timeout = Define um tempo (em segundos) de espera. Se nenhuma tecla for pressionada, carrega a imagem padrão.
default = Define qual será a opção padrão que deve ser automaticamente selecionada quando nenhuma outra for especificada em um tempo definido por timeout.
fallback = Caso ocorra algum erro inesperado e a opção padrão não possa ser carregada, este parâmetro define qual a outra opção deve ser utilizada.
color = Permite que você escolha as cores usadas no menu de boot.
password = Permite que você especifique uma senha. Está será solicitada sempre que houver necessidade de realizar uma função que não seja carregar as imagens disponíveis, como por exemplo acessar a linha de comandos do GRUB. Você pode utilizar também o parâmetro password para esconder um arquivo que contenha outras configurações, como um menu.lst secreto. O arquivo pode ter um nome qualquer.
Você pode ter várias entradas do parâmetro "password" em um mesmo arquivo sendo que uma delas é usada para bloquear o acesso as imagens/linha de comandos e as outras usadas para carregar arquivos de opções do GRUB. Quando você digitar p para entrar com a senha, você pode digitar a senha que protege as imagens/linha de comandos ou a que é utilizada para carregar os arquivos de opções.
hiddenmenu = Está opção faz com que o menu de opções não seja mostrado e de boot na imagem especificada por "default" depois de expirado o tempo definido em timeout. O usuário pode requisitar o menu com as opções pressionando a tecla <ESC> antes que o tempo definido em timeout expire.
Parâmetros que afetam apenas as imagens
:* title = Define um texto que será apresentado no menu de boot para identificar o sistema a ser inicializado.
root = Determina qual a partição raiz do sistema a ser inicializada.
rootnoverify = Idêntica a opção root, mas não tenta montar a partição-alvo, o que é necessário para alguns sistemas como Dos e Windows.
kernel = Nesta opção você informa qual o kernel vai ser inicializado. Você pode passar parâmetros diretamente para o kernel também.
Ex.: kernel (hd0,0)/boot/vmlinuz-2.4.16 vga=6
module = Faz com que algum módulo necessário para o boot seja carregado. Lembre-se que estes não são módulos do kernel (módulos de som, rede, etc.) e sim módulos necessários ao boot de alguns sistemas, como por exemplo o GNU Hurd.
lock = Quando você quiser controlar se uma pessoa pode iniciar um sistema que esteja listado nas opções do menu de boot, você pode utilizar esta opção que faz com que a senha especificada com o comando "password" seja solicitada no momento em que se tentar carregar a imagem em questão.
pause = Emite uma mensagem na tela e espera uma tecla ser pressionada.
makeactive = Torna a partição ativa. Este comando está limitado a partições primárias dos discos.
chainloader = Alguns sistemas como o Windows ou Dos armazenam seu próprio gerenciador de boot no início da partição em que ele está instalado. Para efetuar o boot destes sistemas através do GRUB, você precisa pedir para que o gerenciador de boot de tal sistema seja carregado e faça seu trabalho, dando o boot.
hide e unhide = Esconde e mostra partição respectivamente. Estas duas opções são necessárias quando houver mais de uma versão do Dos ou Windows na máquina em partições diferentes, já que estes sistemas detectam automaticamente a partição e quase sempre o fazem de modo errado. Suponha o Windows na primeira partição primária (hd0,0) e o Dos na segunda partição primária (hd0,1). Quando quisermos carregar estes sistemas devemos proceder da seguinte maneira:
title Windows
hide (hd0,1)
unhide (hd0,0)
rootnoverify (hd0,0)
chainloader 1
makeactive
title Dos
hide (hd0,0)
unhide (hd0,1)
rootnoverify (hd0,1)
chainloader 1
makeactive
map = Alguns sistemas não permitem ser inicializados quando não estão no primeiro disco (Dos, Win 9x, etc.). Para resolver esta e outras situações o GRUB tem um comando que permite enganar tal sistema mapeando as unidades de disco do modo como lhe for mais conveniente.
Imagine que você tenha o primeiro disco (hd0) com o GNU/Linux instalado e em um outro disco (hd1) com o Windows/Dos instalado. O Windows/Dos não permitem serem inicializados desta forma e como solução você poderia usar a seguinte entrada no arquivo de configurações do GRUB:
title Windows
unhide (hd1,0)
rootnoverify (hd1,0)
chainloader 1
map (hd1) (hd0)
makeactive
Isso faz com que o disco (hd1), onde esta o Windows/Dos, seja apresentado a este sistema como (hd0) "enganado" o mesmo e possibilitando o boot.
Parâmetros enviados diretamente ao kernel
Pode ser necessário passar alguns parâmetros para o kernel no momento do boot. Para maiores informações ver a seção [#s-boot-kernelparam Parâmetros de inicialização passados ao kernel, Seção 6.3]. Você pode passar os parâmetros da seguinte maneira:
# Exemplo de entrada no 'menu.lst'.
title Linux 2.4.16
root (hd0,0)
kernel (hd0,0)/boot/vmlinuz-2.4.16 vga=6 mem=512M ramdisk=0
Neste exemplo, a linha com o comando "kernel" é usada para indicar qual imagem deve ser carregada. As opções que seguem (vga, mem e ramdisk) são parâmetros que devem ser passados diretamente ao kernel do sistema a ser carregado.
# Exemplo de arquivo de configuração do GRUB.
# Note que você pode usar o caracter '#' para fazer comentários.
# Se após 30 segundos nenhuma tecla for pressionada, carrega a imagem padrão.
timeout 30
# Define a primeira imagem como padrão.
default 0
# Caso a imagem padrão não funcione carrega a imagem definida aqui.
fallback 1
# Define as cores que serão usadas no menu.
color light-cyan/black white/blue
# Permite utilizar uma senha.
password minha-senha-secreta
password minha-senha (hd0,0)/boot/grub/secret.conf
# Para boot com o GNU/Hurd
title GNU/Hurd
root (hd0,0)
kernel /boot/gnumach.gz root=hd0s1
module /boot/serverboot.gz
# Para boot com o GNU/Linux
title Linux 2.4.16
# Pede a senha configurada em "password" antes de carregar esta imagem.
lock
root (hd0,0)
# Atente as opções passadas diretamente para o kernel (vga, mem, etc.).
kernel (hd0,0)/boot/vmlinuz-2.4.16 vga=6 mem=512M ramdisk=0
# Para boot com o Mach (obtendo o kernel de um disquete)
title Utah Mach4 multiboot
root (hd0,2)
pause Insira o disquete agora!!!
kernel (fd0)/boot/kernel root=hd0s3
module (fd0)/boot/bootstrap
# Para boot com FreeBSD
title FreeBSD 3.4
root (hd0,2,a)
kernel /boot/loader
# Para boot com OS/2
title OS/2
root (hd0,1)
makeactive
chainloader 1
chainloader /boot/chain.os2
# Para boot com Windows 9x, ME, NT, 2000, XP.
title Windows 9x, ME, NT, 2000, XP
unhide (hd0,0)
rootnoverify (hd0,0)
chainloader 1
makeactive
# Para instalar o GRUB no disco rígido.
title = Instala o GRUB no disco rígido
root = (hd0,0)
setup = (hd0)
# Muda as cores.
title Mudar as cores
color light-green/brown blink-red/blue
O GRUB possui inúmeros recursos, mas com certeza um dos mais importantes e que merece destaque é sua linha de comandos. A maioria dos comandos usados no arquivo de configuração menu.lst são válidos aqui e muitos outros estão disponíveis. Uma breve apresentação da linha de comandos será dada, ficando por conta do leitor se aprofundar o quanto achar necessário em sua flexibilidade.
Quando o GRUB é inicializado você pode se deparar com sua linha de comandos ou se possuir o arquivo menu.lst configurado, um menu de escolha. Mesmo usando os menus de escolha você pode utilizar a linha de comandos, bastando para isso seguir as instruções no rodapé da tela onde o GRUB nos informa que podemos digitar e para editar as entradas de boot ou c para ter acesso a linha de comandos (lembre-se que pressionar <ESC> faz com que você volte aos menus de escolha).
Caso a opção password tenha sido especificada no arquivo menu.lst, será necessário antes de acessar as outras opções (que estarão desabilitadas) pressionar p e entrar com a senha correta.
Agora, com acesso a linha de comandos, você pode verificar os comandos disponíveis pressionando duas vezes a tecla <TAB>. Note que você também pode utilizar esta tecla para completar nomes de comandos bem como parâmetros de alguns comandos.
Alguns comandos disponíveis:
cat = Este comando permite verificar o conteúdo de um arquivo qualquer, o qual deve estar gravado em um dispositivo ligado a sua máquina. Embora seja um recurso útil, nenhuma permissão de acesso é verificada e qualquer pessoa que tenha acesso a linha de comandos do GRUB pode listar o conteúdo de arquivos importantes. Para contornar este problema o parâmetro password é utilizado no arquivo menu.lst e faz com que uma senha seja solicitada antes de liberar o acesso a linha de comandos. Não esqueça que ainda é possível utilizar um disquete com o GRUB para dar boot na máquina o que permite usar a linha de comandos pelo disquete.
Ex.: grub> cat (hd0,0)/etc/passwd
cmp = Este comando é utilizado para comparar dois arquivos.
displaymem = Mostra informações sobre a memória RAM.
find = Permite encontrar um arquivo. A saída deste comando disponibiliza o nome completo do caminho para o arquivo e a partição onde o mesmo está localizado.
Ex.: grub> find stage1
geometry = Mostra informações sobre a geometria reconhecida de seu drive e permite que você escolha a geometria desejada caso esta esteja sendo reconhecida erroneamente.
help = help "comando" para ver a ajuda.
Ex.: help color
install = Instala o GRUB, embora não seja recomendado o uso deste comando diretamente, pois é possível esquecer ou trocar facilmente um parâmetro e sobrescrever a tabela de partições de seu disco.
Ex.: install (fd0)/grub/stage1 d (fd0) (fd0)/grub/stage2 p (fd0)/grub/menu.lst
setup = Você pode usar este comando para instalar o GRUB. Note que sua sintaxe é menos complexa do que a usada em install.
boot = Efetua o boot. Suponha o Linux instalado em (hd0,0), podemos passar os seguintes comandos na linha de comandos para efetuar o boot de uma imagem do GNU/Linux:
Muitos outros comandos estão disponíveis tanto na linha de comandos do GRUB quanto no arquivo de configuração menu.lst. Estes comandos adicionais podem ser necessários apenas para algumas pessoas e por isso não serão explicados.
Não existe a necessidade de se remover o GRUB do MBR pois não há utilização para o mesmo vazio. Para substituir o GRUB do MBR é necessário apenas que outro gerenciador de boot escreva algo nele. Você pode seguir o procedimento de instalação do LILO para escrever algo no MBR ou usar o comando fdisk /mbr do DOS.
Para obter informações mais detalhadas sobre o GRUB é recomendado o site oficial do mesmo, o qual está disponível apenas na língua inglesa. Os seguintes sites foram utilizados na pesquisa:
Site Debian-br (http://debian-br.cipsga.org.br/), na parte de suporte, documentação, "Como usar o GRUB: Um guia rápido para usar o GRUB, feito por Vitor Silva Souza e Gustavo Noronha Silva".
Abaixo algumas das opções mais usadas para passar parâmetros de inicialização de hardware/características ao kernel.
append=string - Passa os parâmetros especificados ao kernel. É extremamente útil para passar parâmetros de hardwares que podem ter problemas na hora da detecção ou para parâmetros que precisam ser passados constantemente ao kernel através do aviso boot:.
Exemplo: append="mem=32m"
ramdisk=tamanho - Especifica o tamanho do disco RAM que será criado. Caso for igual a zero, nenhum disco RAM será criado. Se não for especificado, o tamanho do disco RAM usado na imagem de inicialização do kernel será usada.
read-only - Especifica que o sistema de arquivos raiz deverá ser montado como somente leitura. Normalmente o sistema de inicialização remonta o sistema de arquivos como leitura/gravação.
read-write - Especifica que o sistema de arquivos raiz deverá ser montado como leitura e gravação.
root=dispositivo - Especifica o dispositivo que será montado como raiz. Se a palavra current é usada, o dispositivo atual será montado como raiz.
vga=modo - Especifica o mode de video texto que será usado durante a inicialização.
normal - Usa o modo 80x25 (80 colunas por 25 linhas)
extended (ou ext) - Usa o modo de texto 80x50
ask - Pergunta que modo de video usar na inicialização. Os modos de vídeo podem ser obtidos pressionando-se enter quando o sistema perguntar o modo de vídeo.
Uma lista mais detalhada de parâmetros de inicialização pode ser obtida no documento Boot-prompt-howto (veja [ch-ajuda.html#s-ajuda-howto Documentos HOWTO's, Seção 31.8]).
É um gerenciador de partida que permite iniciar o GNU/Linux a partir do DOS. A vantagem do uso do Loadlin é não ser preciso reiniciar o computador para se entrar no GNU/Linux. Ele funciona carregando o kernel (copiado para a partição DOS) para a memória e inicializando o GNU/Linux.
Outro motivo pelo qual é muito usado é quando o GNU/Linux não tem suporte a um certo tipo de dispositivo, mas este tem seu suporte no DOS ou Windows e funciona corretamente com eles.
O truque é o seguinte: Você inicia normalmente pelo DOS e após seu dispositivo ser configurado corretamente pelo driver do DOS e funcionando corretamente, você executa o Loadlin e o GNU/Linux assim poderá usa-lo. Muitos usam o comando Loadlin dentro do arquivo autoexec.bat para iniciar o GNU/Linux automaticamente após o dispositivo ser configurado pelo DOS.
ATENÇÃO!!! Não execute o Loadlin dentro do Windows.
Abaixo a lista de opções que podem ser usadas com o programa LOADLIN (note que todas são usadas no DOS):
loadlin [imagem_kernel] [argumentos] [opções]
imagem_kernel - Arquivo que contém o kernel.
root=dispositivo - Especifica o dispositivo que contém o sistema de arquivos raiz. É especificado de acordo com a identificação de dispositivos no GNU/Linux (/dev/hda1, /dev/hdb1, etc).
ro - Diz ao kernel para montar inicialmente o sistema de arquivos raiz como somente leitura. Os scripts de inicialização normalmente modificam o sistema de arquivos para leitura e gravação após sua checagem.
rw - Diz ao kernel para montar inicialmente o sistema de arquivos raiz como leitura e gravação.
initrd=[NUM] - Define o tamanho do disco RAM usado no sistema.
-v - Mostra detalhes sobre mensagens e configuração
-t - Modo de teste, tudo é feito menos a inicialização do GNU/Linux.
-d arquivo - Mesma função de -t, mas envia a saída para o arquivo
-txmode - Altera o modo de vídeo para 80x25 antes de inicializar o kernel.
-dskreset - Após carregar a imagem do kernel, reseta todos os discos rígidos antes de inicializar o GNU/Linux.
Abaixo você encontra um exemplo do comando loadlin que poderá ser usado em sua instalação GNU/Linux (precisando apenas ajustar a localização da partição raiz do GNU/Linux de acordo com seu sistema).
C:\> LOADLIN vmlinuz root=/dev/hda1 ro
| | |
| | - Montar como somente leitura
| |
| - Partição raiz
|
- Nome do kernel copiado para o DOS
Outro gerenciador de partida que funciona somente com sistemas de arquivos DOS. A principal diferença do syslinux em relação ao LOADLIN é que foi feito especialmente para funcionar em disquetes formatados no DOS, facilitando a instalação do GNU/Linux e para a criação de disquetes de recuperação ou de inicialização. Um disquete gerado pelo syslinux é lido sem problemas pelo DOS/Windows.
syslinux [-s] [dispositivo]
A opção -s instala no disquete uma versão segura, lenta e estúpida do syslinux. Isto é necessário para algumas BIOS problemáticas.
Criando um disquete de inicialização com o syslinux
Siga os passos abaixo para criar um disquete de inicialização com o syslinux:
Formate o disquete no DOS ou com alguma ferramenta GNU/Linux que faça a formatação de disquetes para serem usados no DOS.
Copie um ou mais arquivos de kernel para o disquete
Digite syslinux /dev/fd0 (lembre-se de usar a opção -s se tiver problemas de inicialização). Este comando modificará o setor de partida do disquete e gravará um arquivo chamado LDLINUX.SYS no diretório raiz do disquete.
Lembre-se: O disquete deve estar desmontado antes de usar o comando syslinux, caso o disquete estiver montado uma mensagem será mostrada e o syslinux abortado.
Por padrão é carregado o kernel de nome GNU/Linux. Este padrão pode ser modificado através do arquivo de configuração SYSLINUX.CFG que também é gravado no diretório raiz do disquete. Veja [#s-boot-syslinux-opcoes O arquivo SYSLINUX.CFG, Seção 6.5.2] para detalhes.
Se as teclas Caps Lock ou Scrool Lock estiverem ligadas ou Shift, Alt forem pressionadas durante o carregamento do syslinux, o syslinux mostrará um aviso de boot: no estilo do LILO. O usuário pode então digitar o nome do kernel seguido de qualquer parâmetro para inicializar o GNU/Linux.
Este arquivo é criado no diretório raiz da unidade de disquete e contém as opções que serão usadas para modificar o funcionamento do syslinux. Abaixo a listagem de opções que podem ser especificadas neste arquivo:
default [kernel] [opções]
Indica o nome do kernel e as opções dele que serão usadas na inicialização, caso syslinux seja iniciado automaticamente. Caso não for especificada, o valor assumido será linux auto sem nenhuma opção de inicialização.
append [opções]
Passa uma ou mais opções ao kernel na inicialização. Elas serão adicionadas automaticamente para inicializações automáticas e manuais do syslinux.
label [nome]
kernel [kernel]
append [opções]
Nome que identificará o kernel no aviso de boot: (idêntica a opção label= do LILO). Se a imagem especificada por nome for selecionada, o kernel usado será o especificado pelo parâmetro kernel e as opções usadas por append.
Caso seja passado um hífen - ao parâmetro append, os parâmetros passados pelo append global serão anulados.
implicit [valor]
Se o [valor] for igual a 0, não carrega a imagem até que seja explicitamente especificada na opção label.
timeout [tempo]
Indica quanto tempo o syslinux aguardará antes de inicializar automaticamente (medido em 1/10 de segundos). Caso alguma tecla seja pressionada, a inicialização automática é interrompida. Para desativar esta característica, use 0 como timeout. O valor máximo é de 35996.
font [nome]
Especifica uma fonte (em formato .psf) que será usada para mostrar as mensagens do syslinux (após o aviso de copyright do programa). Ele carrega a fonte para a placa de vídeo, se a fonte conter uma tabela unicode, ela será ignorada. Somente funciona em placas EGA e VGA.
kbdmap [mapa]
Instala um simples mapa de teclado. O mapa de teclados usado é muito simples: somente remapeia códigos conhecidos pela BIOS, o que significa que somente teclas usadas no teclado padrão EUA serão usadas.
O utilitário keytab-lilo.pl da distribuição do lilo pode ser usado para criar tais mapas de teclado.
prompt [valor]
Se [valor] for igual a 1, mostra automaticamente o aviso de boot: assim que o syslinux for iniciado. Caso seja igual a 0, mostra o aviso de boot: somente se as teclas Shift ou Alt forem pressionadas ou Caps Lock e Scrool Lock estiverem ativadas.
display [arquivo]
Mostra o conteúdo do [arquivo] durante a inicialização do syslinux.
F1 [arquivo]
F2 [arquivo]
...
F0 [arquivo]
Especifica que arquivos serão mostrados quando as teclas de F1 até F10 forem pressionadas. Para detalhes, veja [#s-boot-syslinux-formatacao Formatação dos arquivos de tela do syslinux, Seção 6.5.3].
Os arquivos de texto que são mostrados na tela pelo syslinux podem ter suas cores modificadas usando parâmetros simples, isto causa um bom efeito de apresentação. Abaixo estão os códigos que podem ser usados para criar um arquivo texto que será exibido pelo syslinux:
CTRL L - Limpa a tela (semelhante ao que o clear faz).
CTRL O[frente][fundo] - Define a cor de frente e fundo, se somente
uma cor for especificada, esta será assumida como frente.
Veja os valores para [frente] e [fundo] abaixo:
00 - preto 08 - cinza escuro
01 - azul escuro 09 - azul claro
02 - verde escuro 0a - verde claro
03 - ciano escuro 0b - ciano claro
04 - vermelho escuro 0c - vermelho claro
05 - purple escuro 0d - purple claro
06 - marrom 0e - amarelo
07 - cinza claro 0f - branco
CTRL Z - Equivalente ao fim de arquivo no DOS
O código padrão usado é o 07. Escolhendo uma cor clara para o fundo (08-0f) resultará em uma cor piscante correspondente para a texto (00-07).
Para executar um comando, é necessário que ele tenha permissões de execução (veja [ch-perm.html#s-perm-tipos Tipos de Permissões de acesso, Seção 13.2] e [ch-cmdd.html#s-comando-ls ls, Seção 8.1]) e que esteja no caminho de procura de arquivos (veja [#s-run-path path, Seção 7.2]).
No aviso de comando #(root) ou $(usuário), digite o nome do comando e tecle Enter. O programa/comando é executado e receberá um número de identificação (chamado de PID - Process Identification), este número é útil para identificar o processo no sistema e assim ter um controle sobre sua execução (será visto mais adiante neste capítulo).
Todo o programa recebe uma identificação de usuário (UID) quando é executado o que determina quais serão suas permissões de acesso durante sua execução. O programa normalmente usa o UID do usuário que o executou ou o usuário configurado pelo bit de permissão de acesso SUID caso estiver definido. Existem também programas que são executados como root e modificam sua identificação de usuário para algum que tenha menos privilégios no sistema (como o Apache, por exemplo). Para maiores detalhes veja [ch-perm.html Permissões de acesso a arquivos e diretórios, Capítulo 13].
Todo o programa executado no GNU/Linux roda sob o controle das permissões de acesso. Recomendo ver mais tarde o [ch-perm.html Permissões de acesso a arquivos e diretórios, Capítulo 13].
Path é o caminho de procura dos arquivos/comandos executáveis. O path (caminho) é armazenado na variável de ambiente PATH. Você pode ver o conteúdo desta variável com o comando echo $PATH.
Por exemplo, o caminho /usr/local/bin:/usr/bin:/bin:/usr/bin/X11 significa que se você digitar o comando ls, o interpretador de comandos iniciará a procura do programa ls no diretório /usr/local/bin, caso não encontre o arquivo no diretório /usr/local/bin ele inicia a procura em /usr/bin, até que encontre o arquivo procurado.
Caso o interpretador de comandos chegue até o último diretório do path e não encontre o arquivo/comando digitado, é mostrada a seguinte mensagem:
bash: ls: command not found (comando não encontrado).
O caminho de diretórios vem configurado na instalação do Linux, mas pode ser alterado no arquivo /etc/profile. Caso deseje alterar o caminho para todos os usuários, este arquivo é o melhor lugar, pois ele é lido por todos os usuários no momento do login.
Caso um arquivo/comando não esteja localizado em nenhum dos diretórios do path, você deve executa-lo usando um ./ na frente do comando.
Se deseja alterar o path para um único usuário, modifique o arquivo .bash_profile em seu diretório de usuário (home).
OBSERVAÇÃO: Por motivos de segurança, não inclua o diretório atual $PWD no path.
Primeiro Plano - Também chamado de foreground. Quando você deve esperar o término da execução de um programa para executar um novo comando. Somente é mostrado o aviso de comando após o término de execução do comando/programa.
Segundo Plano - Também chamado de background. Quando você não precisa esperar o término da execução de um programa para executar um novo comando. Após iniciar um programa em background, é mostrado um número PID (identificação do Processo) e o aviso de comando é novamente mostrado, permitindo o uso normal do sistema.
O programa executado em background continua sendo executado internamente. Após ser concluído, o sistema retorna uma mensagem de pronto acompanhado do número PID do processo que terminou.
Para iniciar um programa em primeiro plano, basta digitar seu nome normalmente. Para iniciar um programa em segundo plano, acrescente o caracter "&" após o final do comando.
OBS: Mesmo que um usuário execute um programa em segundo plano e saia do sistema, o programa continuará sendo executado até que seja concluído ou finalizado pelo usuário que iniciou a execução (ou pelo usuário root).
Exemplo: find / -name boot.b &
O comando será executado em segundo plano e deixará o sistema livre para outras tarefas. Após o comando find terminar, será mostrada uma mensagem.
Os comandos podem ser executados em sequência (um após o término do outro) se os separarmos com ";". Por exemplo: echo primeiro;echo segundo;echo terceiro
Algumas vezes é útil ver quais processos estão sendo executados no computador. O comando ps faz isto, e também nos mostra qual usuário executou o programa, hora que o processo foi iniciado, etc.
ps [opções]
Onde:
opções
a
Mostra os processos criados por você e de outros usuários do sistema.
x
Mostra processos que não são controlados pelo terminal.
u
Mostra o nome de usuário que iniciou o processo e hora em que o processo foi iniciado.
m
Mostra a memória ocupada por cada processo em execução.
f
Mostra a árvore de execução de comandos (comandos que são chamados por outros comandos).
e
Mostra variáveis de ambiente no momento da inicialização do processo.
w
Mostra a continuação da linha atual na próxima linha ao invés de cortar o restante que não couber na tela.
--sort
[coluna]
Organiza a saída do comando ps de acordo com a coluna escolhida. Você pode usar as colunas pid, utime, ppid, rss, size, user, priority.
Pode ser especificada uma listagem em ordem inversa especificando—sort:[-coluna]. Para mais detalhes e outras opções, veja a página de manual.
As opções acima podem ser combinadas para resultar em uma listagem mais completa. Você também pode usar pipes "|" para filtrar a saída do comando ps. Para detalhes, veja [ch-redir.html#s-redir-pipe | (pipe), Seção 14.5].
Ao contrário de outros comandos, o comando ps não precisa do hífen "-" para especificar os comandos. Isto porque ele não utiliza opções longas e não usa parâmetros.
Exemplos: ps, ps ax|grep inetd, ps auxf, ps auxw.
Mostra os programas em execução ativos, parados, tempo usado na CPU, detalhes sobre o uso da memória RAM, Swap, disponibilidade para execução de programas no sistema, etc.
top é um programa que continua em execução mostrando continuamente os processos que estão rodando em seu computador e os recursos utilizados por eles. Para sair do top, pressione a tecla q.
top [opções]
Onde:
-d [tempo]
Atualiza a tela após o [tempo] (em segundos).
-s
Diz ao top para ser executado em modo seguro.
-i
Inicia o top ignorando o tempo de processos zumbis.
-c
Mostra a linha de comando ao invés do nome do programa.
A ajuda sobre o top pode ser obtida dentro do programa pressionando a tecla h ou pela página de manual (man top).
Abaixo algumas teclas úteis:
espaço - Atualiza imediatamente a tela.
CTRL L - Apaga e atualiza a tela.
h - Mostra a tela de ajuda do programa. É mostrado todas as teclas que podem ser usadas com o top.
i - Ignora o tempo ocioso de processos zumbis.
q - Sai do programa.
k - Finaliza um processo - semelhante ao comando kill. Você será perguntado pelo número de identificação do processo (PID). Este comando não estará disponível caso esteja usando o top com a opção -s.
n - Muda o número de linhas mostradas na tela. Se 0 for especificado, será usada toda a tela para listagem de processos.
Para cancelar a execução de algum processo rodando em primeiro plano, basta pressionar as teclas CTRL C. A execução do programa será cancelada e será mostrado o aviso de comando. Você também pode usar o comando [#s-run-kill kill, Seção 7.7.6] para interromper um processo sendo executado.
Para parar a execução de um processo rodando em primeiro plano, basta pressionar as teclas CTRL Z. O programa em execução será pausado e será mostrado o número de seu job e o aviso de comando.
Para retornar a execução de um comando pausado, use [#s-run-fg fg, Seção 7.7.4] ou [#s-run-bg bg, Seção 7.7.5].
O programa permanece na memória no ponto de processamento em que parou quando ele é interrompido. Você pode usar outros comandos ou rodar outros programas enquanto o programa atual está interrompido.
O comando jobs mostra os processos que estão parados ou rodando em segundo plano. Processos em segundo plano são iniciados usando o símbolo "&" no final da linha de comando (veja [#s-run-tipos Tipos de Execução de comandos/programas, Seção 7.3]) ou através do comando bg.
jobs
O número de identificação de cada processo parado ou em segundo plano (job), é usado com os comandos [#s-run-fg fg, Seção 7.7.4] e [#s-run-bg bg, Seção 7.7.5]. Um processo interrompido pode ser finalizado usando-se o comando kill %[num], onde [num] é o número do processo obtido pelo comando jobs.
Permite fazer um programa rodando em segundo plano ou parado, rodar em primeiro plano. Você deve usar o comando jobs para pegar o número do processo rodando em segundo plano ou interrompida, este número será passado ao comando fg para ativa-lo em primeiro plano.
fg [número]
Onde número é o número obtido através do comando jobs.
Caso seja usado sem parâmetros, o fg utilizará o último programa interrompido (o maior número obtido com o comando jobs).
Exemplo: fg 1.
Permite fazer um programa rodando em primeiro plano ou parado, rodar em segundo plano. Para fazer um programa em primeiro plano rodar em segundo, é necessário primeiro interromper a execução do comando com CTRL Z, será mostrado o número da tarefa interrompida, use este número com o comando bg para iniciar a execução do comando em segundo plano.
bg [número]
Onde: número número do programa obtido com o pressionamento das teclas CTRL Z ou através do comando jobs.
Permite enviar um sinal a um comando/programa. Caso seja usado sem parâmetros, o kill enviará um sinal de término ao processo sendo executado.
kill [opções] [sinal] [número]
Onde:
número
É o número de identificação do processo obtido com o comando [#s-run-ps ps, Seção 7.5]. Também pode ser o número após o sinal de % obtido pelo comando jobs para matar uma tarefa interrompida. Veja [#s-run-ver-backgrounds jobs, Seção 7.7.3].
sinal
Sinal que será enviado ao processo. Se omitido usa -15 como padrão.
opções
-9
Envia um sinal de destruição ao processo ou programa. Ele é terminado imediatamente sem chances de salvar os dados ou apagar os arquivos temporários criados por ele.
Você precisa ser o dono do processo ou o usuário root para termina-lo ou destruí-lo. Você pode verificar se o processo foi finalizado através do comando ps. Os tipos de sinais aceitos pelo GNU/Linux são explicados em detalhes em [#s-run-sinais Sinais do Sistema, Seção 7.7.9].
Exemplo: kill 500, kill -9 500, kill %1.
Retirado da página de manual signal. O GNU/Linux suporta os sinais listados abaixo. Alguns números de sinais são dependentes de arquitetura.
Primeiro, os sinais descritos no POSIX 1:
Sinal Valor Ação Comentário
---------------------------------------------------------------------------
HUP 1 A Travamento detectado no terminal de controle ou
finalização do processo controlado
INT 2 A Interrupção através do teclado
QUIT 3 C Sair através do teclado
ILL 4 C Instrução Ilegal
ABRT 6 C Sinal de abortar enviado pela função abort
FPE 8 C Exceção de ponto Flutuante
KILL 9 AEF Sinal de destruição do processo
SEGV 11 C Referência Inválida de memória
PIPE 13 A Pipe Quebrado: escreveu para o pipe sem leitores
ALRM 14 A Sinal do Temporizador da chamada do sistema alarm
TERM 15 A Sinal de Término
USR1 30,10,16 A Sinal definido pelo usuário 1
USR2 31,12,17 A Sinal definido pelo usuário 2
CHLD 20,17,18 B Processo filho parado ou terminado
CONT 19,18,25 Continuar a execução, se interrompido
STOP 17,19,23 DEF Interromper processo
TSTP 18,20,24 D Interromper digitação no terminal
TTIN 21,21,26 D Entrada do terminal para o processo em segundo plano
TTOU 22,22,27 D Saída do terminal para o processo em segundo plano
As letras da coluna Ação tem o seguinte significado:
A - A ação padrão é terminar o processo.
B - A ação padrão é ignorar o sinal.
C - A ação padrão é terminar o processo e mostrar o core.
D - A ação padrão é parar o processo.
E - O sinal não pode ser pego.
F - O sinal não pode ser ignorado.
Sinais não descritos no POSIX 1 mas descritos na SUSv2:
Sinal Valor Ação Comentário
-------------------------------------------------------------------------
BUS 10,7,10 C Erro no Barramento (acesso incorreto da memória)
POLL A Evento executado em Pool (Sys V). Sinônimo de IO
PROF 27,27,29 A Tempo expirado do Profiling
SYS 12,-,12 C Argumento inválido para a rotina (SVID)
TRAP 5 C Captura do traço/ponto de interrupção
URG 16,23,21 B Condição Urgente no soquete (4.2 BSD)
VTALRM 26,26,28 A Alarme virtual do relógio (4.2 BSD)
XCPU 24,24,30 C Tempo limite da CPU excedido (4.2 BSD)
XFSZ 25,25,31 C Limite do tamanho de arquivo excedido (4.2 BSD)
(Para os casos SIGSYS, SIGXCPU, SIGXFSZ, e em algumas arquiteturas também o SIGGUS, a ação padrão do Linux para kernels 2.3.27 e superiores é A (terminar), enquanto SYSv2 descreve C (terminar e mostrar dump core).) Seguem vários outros sinais:
Sinal Valor Ação Comentário
--------------------------------------------------------------------
IOT 6 C Traço IOT. Um sinônimo para ABRT
EMT 7,-,7
STKFLT -,16,- A Falha na pilha do processador
IO 23,29,22 A I/O agora possível (4.2 BSD)
CLD -,-,18 Um sinônimo para CHLD
PWR 29,30,19 A Falha de força (System V)
INFO 29,-,- Um sinônimo para SIGPWR
LOST -,-,- A Perda do bloqueio do arquivo
WINCH 28,28,20 B Sinal de redimensionamento da Janela (4.3 BSD, Sun)
UNUSED -,31,- A Sinal não usado (será SYS)
O "-" significa que o sinal não está presente. Onde três valores são listados, o primeiro é normalmente válido para o Alpha e Sparc, o do meio para i386, PowerPc e sh, o último para o Mips. O sinal 29 é SIGINFO/SIGPWR em um Alpha mas SIGLOST em um Sparc.
Executa um comando ignorando os sinais de interrupção. O comando poderá ser executado até mesmo em segundo plano caso seja feito o logout do sistema.
nohup [comando que será executado]
As mensagens de saída do nohup são direcionadas para o arquivo $HOME/nohup.out.
Exemplo: nohup find / -uid 0 >/tmp/rootfiles.txt &.
Configura a prioridade da execução de um comando/programa.
nice [opções] [comando/programa]
Onde:
comando/programa
Comando/programa que terá sua prioridade ajustada.
opções
-n [numero]
Configura a prioridade que o programa será executado. Se um programa for executado com maior prioridade, ele usará mais recursos do sistema para seu processamento, caso tenha uma prioridade baixa, ele permitirá que outros programas tenham preferência. A prioridade de execução de um programa/comando pode ser ajustada de -19 (a mais alta) até 19 (a mais baixa).
Permite identificar e fechar os processos que estão utilizando arquivos e soquetes no sistema.
fuser [opções] [nome]
Onde:
nome
Especifica um nome de processo, diretório, arquivo, etc.
opções
-k
Finaliza os processos acessando o arquivo especificado. O sinal desejado deve ser especificado com a opção -signal [num], ou o sinal -9 será enviado como padrão. Não é possível matar o próprio processo fuser.
-i
Pergunta antes de destruir um processo. Será ignorada caso a opção -k não seja especificada.
-l
Lista todos os nomes de sinais conhecidos.
-m [nome]
Especifica um arquivo em um sistema de arquivos montado ou dispositivo de bloco que está montado. Todos os processos acessando aquele sistema de arquivos serão listados. Diretórios são mostrados seguidos de uma /
-signal [número]
Usa o sinal especificado ao invés de -9 (SIGKILL) quando finalizar processos.
-u
Acrescenta o nome do dono de cada processo ao PID.
-v
Os processos são mostrados em um estilo idêntico ao ps.
Mostra estatísticas sobre o uso da memória virtual do sistema.
vmstat [intervalo] [contagem]
Onde:
intervalo
Número especificado em segundos entre atualizações.
contagem
Número de vezes que será mostrado.
Se não for especificado nenhum parâmetro, o vmstat mostra o status da memória virtual e volta imediatamente para a linha de comando. A descrição dos campos do vmstat são as seguintes:
Processos
r
Número de processos aguardando execução.
b
Número de processos em espera não interrompíveis.
w
Número de processos extraídos do arquivo de troca ou caso contrário em execução.
Memória
swpd
A quantidade de memória virtual usada em Kb.
free
Quantidade de memória livre em Kb.
buff
Quantidade de memória usada como buffer em Kb.
Memória Virtual
si
Quantidade de memória gravada para o disco Kb/s.
so
Quantidade de memória retirada do disco em Kb/s.
Entrada/Saída
bi
Blocos enviados para um dispositivo de bloco (medido em blocos por segundo).
bo
Blocos recebidos de um dispositivo de bloco (em blocos por segundo).
Sistema
in
Número de interrupções por segundo, incluindo o clock.
Retorna o PID do processo especificado
pidof [opções] [nome]
Onde:
nome
Nome do processo que seja obter o número PID
opções
-s
Retorna somente o primeiro PID encontrado.
-x
Retorna o PID do shell que está executando o script
-o [PID]
Ignora o processo com aquele PID. O PID especial %PPID pode ser usado para nomear o processo pai do programa pidof, em outras palavras
OBS: O programa pidof é um link simbólico ao programa killall5. Cuidado ao executar o killall5 as funções e opções são completamente diferentes dependendo da forma como é chamado na linha de comando! (veja [#s-run-killall5 killall5, Seção 7.7.8] para detalhes.)
Exemplo: pidof -s init
Muitas vezes quando se esta iniciando no GNU/Linux você pode executar um programa e talvez não saber como fecha-lo. Este capítulo do guia pretende ajuda-lo a resolver este tipo de problema.
Isto pode também ocorrer com programadores que estão construindo seus programas e por algum motivo não implementam uma opção de saída, ou ela não funciona!
Em nosso exemplo vou supor que executamos um programa em desenvolvimento com o nome contagem que conta o tempo em segundos a partir do momento que é executado, mas que o programador esqueceu de colocar uma opção de saída. Siga estas dicas para finaliza-lo:
Normalmente todos os programas UNIX (o GNU/Linux também é um Sistema Operacional baseado no UNIX) podem ser interrompidos com o pressionamento das teclas <CTRL> e <C>. Tente isto primeiro para finalizar um programa. Isto provavelmente não vai funcionar se estiver usando um Editor de Texto (ele vai entender como um comando de menu). Isto normalmente funciona para comandos que são executados e terminados sem a intervenção do usuário.
Caso isto não der certo, vamos partir para a força! ;-)
Mude para um novo console (pressionando <ALT> e <F2>), e faça o login como usuário root.
Localize o PID (número de identificação do processo) usando o comando: ps ax, aparecerão várias linhas cada uma com o número do processo na primeira coluna, e a linha de comando do programa na última coluna. Caso aparecerem vários processos você pode usar ps ax|grep contagem, neste caso o grep fará uma filtragem da saída do comando ps ax mostrando somente as linhas que tem a palavra "contagem". Para maiores detalhes, veja o comando [ch-cmdv.html#s-cmdv-grep grep, Seção 10.8].
Feche o processo usando o comando kill PID, lembre-se de substituir PID pelo número encontrado pelo comando ps ax acima.
O comando acima envia um sinal de término de execução para o processo (neste caso o programa contagem). O sinal de término mantém a chance do programa salvar seus dados ou apagar os arquivos temporários que criou e então ser finalizado, isto depende do programa.
Alterne para o console onde estava executando o programa contagem e verifique se ele ainda está em execução. Se ele estiver parado mas o aviso de comando não está disponível, pressione a tecla <ENTER>. Frequentemente acontece isto com o comando kill, você finaliza um programa mas o aviso de comando não é mostrado até que se pressione <ENTER>.
Caso o programa ainda não foi finalizado, repita o comando kill usando a opção -9: kill -9 PID. Este comando envia um sinal de DESTRUIÇÃO do processo, fazendo ele terminar "na marra"!
Uma última dica: todos os programas estáveis (todos que acompanham as boas distribuições GNU/Linux) tem sua opção de saída. Lembre-se que quando finaliza um processo todos os dados do programa em execução podem ser perdidos (principalmente se estiver em um editor de textos), mesmo usando o kill sem o parâmetro -9.
Procure a opção de saída de um programa consultando o help on line, as páginas de manual, a documentação que acompanha o programa, info pages. Para detalhes de como encontrar a ajuda dos programas, veja o [ch-ajuda.html Como obter ajuda no sistema, Capítulo 31]
As vezes quando um programa mal comportado é finalizado ou quando você visualiza um arquivo binário através do comando cat, é possível que o aviso de comando (prompt) volte com caracteres estranhos.
Para fazer tudo voltar ao normal, basta digitar reset e teclar ENTER. Não se preocupe, o comando reset não reiniciará seu computador (como o botão reset do seu computador faz), ele apenas fará tudo voltar ao normal.
Note que enquanto você digitar reset aparecerão caracteres estranhos ao invés das letras. Não se preocupe! Basta digitar corretamente e bater ENTER e o aviso de comando voltará ao normal.= Guia Foca GNU/Linux Capítulo 8 - Comandos para manipulação de diretório =
Abaixo comandos úteis para a manipulação de diretórios.
ls [opções] [caminho/arquivo] [caminho1/arquivo1] ...
onde:
caminho/arquivo
Diretório/arquivo que será listado.
caminho1/arquivo1
Outro Diretório/arquivo que será listado. Podem ser feitas várias listagens de uma só vez.
opções
-a, --all
Lista todos os arquivos (inclusive os ocultos) de um diretório.
-A, --almost-all
Lista todos os arquivos (inclusive os ocultos) de um diretório, exceto o diretório atual e o de nível anterior.
-B, --ignore-backups
Não lista arquivos que terminam com ~ (Backup).
--color=PARAM
Mostra os arquivos em cores diferentes, conforme o tipo de arquivo. PARAM pode ser:
never - Nunca lista em cores (mesma coisa de não usar o parâmetro --color).
always - Sempre lista em cores conforme o tipo de arquivo.
auto - Somente colore a listagem se estiver em um terminal.
-d, --directory
Lista os nomes dos diretórios ao invés do conteúdo.
-f
Não classifica a listagem.
-F
Insere um caracter após arquivos executáveis ('*'), diretórios ('/'), soquete ('='), link simbólico ('@') e pipe ('|'). Seu uso é útil para identificar de forma fácil tipos de arquivos nas listagens de diretórios.
-G, --no-group
Oculta a coluna de grupo do arquivo.
-h, --human-readable
Mostra o tamanho dos arquivos em Kbytes, Mbytes, Gbytes.
-H
Faz o mesmo que -h, mas usa unidades de 1000 ao invés de 1024 para especificar Kbytes, Mbytes, Gbytes.
-l
Usa o formato longo para listagem de arquivos. Lista as permissões, data de modificação, donos, grupos, etc.
-n
Usa a identificação de usuário e grupo numérica ao invés dos nomes.
-L, --dereference
Lista o arquivo original e não o link referente ao arquivo.
-o
Usa a listagem longa sem os donos dos arquivos (mesma coisa que -lG).
-p
Mesma coisa que -F, mas não inclui o símbolo '*' em arquivos executáveis. Esta opção é típica de sistemas Linux.
-R
Lista diretórios e sub-diretórios recursivamente.
--full-time
Lista data e hora completa.
Classificação da listagem
A listagem pode ser classificada usando-se as seguintes opções:
-f
Não classifica, e usa -au para listar os arquivos.
-r
Inverte a ordem de classificação.
-c
Classifica pela data de alteração.
-X
Classifica pela extensão.
-U
Não classifica, lista os arquivos na ordem do diretório.
Uma listagem feita com o comando ls -la normalmente é mostrada da seguinte maneira:
-rwxr-xr—1 gleydson user 8192 nov 4 16:00 teste
Abaixo as explicações de cada parte:
-rwxr-xr--
São as permissões de acesso ao arquivo teste. A primeira letra (da esquerda) identifica o tipo do arquivo, se tiver um d é um diretório, se tiver um "-" é um arquivo normal.
As permissões de acesso é explicada em detalhes em [ch-perm.html Permissões de acesso a arquivos e diretórios, Capítulo 13].
1
Se for um diretório, mostra a quantidade de sub-diretórios existentes dentro dele. Caso for um arquivo, será 1.
gleydson
Nome do dono do arquivo teste.
user
Nome do grupo que o arquivo teste pertence.
8192
Tamanho do arquivo (em bytes).
nov
Mês da criação/ última modificação do arquivo.
4
Dia que o arquivo foi criado.
16
00
Hora em que o arquivo foi criado/modificado. Se o arquivo foi criado há mais de um ano, em seu lugar é mostrado o ano da criação do arquivo.
teste
Nome do arquivo.
Exemplos do uso do comando ls:
ls - Lista os arquivos do diretório atual.
ls /bin /sbin - Lista os arquivos do diretório /bin e /sbin
ls -la /bin - Listagem completa (vertical) dos arquivos do diretório /bin inclusive os ocultos.
Entra em um diretório. Você precisa ter a permissão de execução para entrar no diretório.
cd [diretório]
onde:
diretório - diretório que deseja entrar.
Exemplos:
Usando cd sem parâmetros ou cd ~, você retornará ao seu diretório de usuário (diretório home).
cd /, retornará ao diretório raíz.
cd -, retornará ao diretório anteriormente acessado.
cd .., sobe um diretório.
cd ../[diretório], sobe um diretório e entra imediatamente no próximo (por exemplo, quando você está em /usr/sbin, você digita cd ../bin, o comando cd retorna um diretório (/usr) e entra imediatamente no diretório bin (/usr/bin).
Cria um diretório no sistema. Um diretório é usado para armazenar arquivos de um determinado tipo. O diretório pode ser entendido como uma pasta onde você guarda seus papeis (arquivos). Como uma pessoa organizada, você utilizará uma pasta para guardar cada tipo de documento, da mesma forma você pode criar um diretório vendas para guardar seus arquivos relacionados com vendas naquele local.
Mostra uma mensagem para cada diretório criado. As mensagens de erro serão mostradas mesmo que esta opção não seja usada.
Para criar um novo diretório, você deve ter permissão de gravação. Por exemplo, para criar um diretório em /tmp com o nome de teste que será usado para gravar arquivos de teste, você deve usar o comando "mkdir /tmp/teste".
Podem ser criados mais de um diretório com um único comando (mkdir /tmp/teste /tmp/teste1 /tmp/teste2).
Remove um diretório do sistema. Este comando faz exatamente o contrário do mkdir. O diretório a ser removido deve estar vazio e você deve ter permissão de gravação para remove-lo.
rmdir [caminho/diretório] [caminho1/diretório1]
onde:
caminho
Caminho do diretório que será removido.
diretório
Nome do diretório que será removido.
É necessário que esteja um nível acima do diretório(s) que será(ão) removido(s). Para remover diretórios que contenham arquivos, use o comando rm com a opção -r (para maiores detalhes, veja [ch-cmd.html#s-comando-rm rm, Seção 9.3]).
Por exemplo, para remover o diretório /tmp/teste você deve estar no diretório tmp e executar o comando rmdir teste.
Localização do arquivo que deseja apagar. Se omitido, assume que o arquivo esteja no diretório atual.
arquivo/diretório
Arquivo que será apagado.
opções
-i, --interactive
Pergunta antes de remover, esta é ativada por padrão.
-v, --verbose
Mostra os arquivos na medida que são removidos.
-r, --recursive
Usado para remover arquivos em sub-diretórios. Esta opção também pode ser usada para remover sub-diretórios.
-f, --force
Remove os arquivos sem perguntar.
-- arquivo
Remove arquivos/diretórios que contém caracteres especiais. O separador "--" funciona com todos os comandos do shell e permite que os caracteres especiais como "*", "?", "-", etc. sejam interpretados como caracteres comuns.
Use com atenção o comando rm, uma vez que os arquivos e diretórios forem apagados, eles não poderão ser mais recuperados.
Exemplos:
rm teste.txt - Apaga o arquivo teste.txt no diretório atual.
rm *.txt - Apaga todos os arquivos do diretório atual que terminam com .txt.
rm *.txt teste.novo - Apaga todos os arquivos do diretório atual que terminam com .txt e também o arquivo teste.novo.
rm -rf /tmp/teste/* - Apaga todos os arquivos e sub-diretórios do diretório /tmp/teste mas mantém o sub-diretório /tmp/teste.
rm -rf /tmp/teste - Apaga todos os arquivos e sub-diretórios do diretório /tmp/teste, inclusive /tmp/teste.
rm -f -- --arquivo-- - Remove o arquivo de nome --arquivo--.
Arquivo que será copiado. Podem ser especificados mais de um arquivo para ser copiado usando "Curingas" (veja [ch-bas.html#s-basico-curingas Curingas, Seção 2.12]).
destino
O caminho ou nome de arquivo onde será copiado. Se o destino for um diretório, os arquivos de origem serão copiados para dentro do diretório.
opções
i, --interactive
Pergunta antes de substituir um arquivo existente.
-f, --force
Não pergunta, substitui todos os arquivos caso já exista.
-r
Copia arquivos dos diretórios e subdiretórios da origem para o destino. É recomendável usar -R ao invés de -r.
-R, --recursive
Copia arquivos e sub-diretórios (como a opção -r) e também os arquivos especiais FIFO e dispositivos.
-v, --verbose
Mostra os arquivos enquanto estão sendo copiados.
-s, --simbolic-link
Cria link simbólico ao invés de copiar.
-l, --link
Faz o link no destino ao invés de copiar os arquivos.
-p, --preserve
Preserva atributos do arquivo, se for possível.
-u, --update
Copia somente se o arquivo de origem é mais novo que o arquivo de destino ou quando o arquivo de destino não existe.
-x
Não copia arquivos que estão localizados em um sistema de arquivos diferente de onde a cópia iniciou.
-a
Copia todos os artibutos (preservando proteção, dono e datas)
--preserve=timestamps
Preserva, dos atributos, apenas aqueles relativos à data (veremos mais abaixo quando usar)
O comando cp copia arquivos da ORIGEM para o DESTINO. Ambos origem e destino terão o mesmo conteúdo após a cópia.
Exemplos:
cp teste.txt teste1.txt
Copia o arquivo teste.txt para teste1.txt.
cp teste.txt /tmp
Copia o arquivo teste.txt para dentro do diretório /tmp.
cp * /tmp
Copia todos os arquivos do diretório atual para /tmp.
cp /bin/* .
Copia todos os arquivos do diretório /bin para o diretório em que nos encontramos no momento.
cp -R /bin /tmp
Copia o diretório /bin e todos os arquivos/sub-diretórios existentes para o diretório /tmp.
cp -R /bin/* /tmp
Copia todos os arquivos do diretório /bin (exceto o diretório /bin) e todos os arquivos/sub-diretórios existentes dentro dele para /tmp.
cp -R /bin /tmp
Copia todos os arquivos e o diretório /bin para /tmp.
Copia todos arquivos (e sub-pastas) que estão na conta de um usuário para uma pasta de outro. Requer privilégios de escrita sobre o diretório destino e, provavelmente, sobre o diretório origem - já que ao preservar dono, o comando deixará o destino com o dono original (usuário1) em vez do dono desejado (usuário2)
Como vimos acima, o comando natural para restaurar um backup de CD ou DVD seria cp -auv; porém aqui ocorre um bug: ao iniciar a cópia com a opção de preservar os atributos de proteção, como os CDs e DVDs são read-only, estas opção são marcadas nas pastas criadas, impedindo a cópia dos arquivos seguintes. Então a solução é ignorar os atributos exceto os de data (trocando a opção -a pela opção --preserve=timestamps) e acrescentando a opção -R (para fazer recursão nos subdiretórios).
Copia de arquivos entre computadores de uma mesma rede local, através de comandos do tipo scp "10.1.1.3:/home/jimbo/wales.jpg" .. Para mais detalhes, ver a documentação
Usado antes de uma expressão lógica, por exemplo, para testar a existência de arquivos ou a comparação de strings. Pode ser usado como comando (test (alguma coisa)...) ou logo após um if (if test (alguma coisa); then ...; fi)
time
Measure Program Resource Use
times
User and system times
timidity
Play midi files and set up software synth to play midi files with other commands.
Permite ver/modificar a Data e Hora do Sistema. Você precisa estar como usuário root para modificar a data e hora. Muitos programas do sistema, arquivos de registro (log) e tarefas agendadas funcionam com base na data e hora fornecidas pelo sistema, assim esteja consciente das modificações que a data/hora pode trazer a estes programas (principalmente em se tratando de uma rede com muitos usuários).
date MesDiaHoraMinuto[AnoSegundos]
Onde:
MesDiaHoraMinuto[AnoSegundos]
São respectivamente os números do mês, dia, hora e minutos sem espaços. Opcionalmente você pode especificar o Ano (com 2 ou 4 dígitos) e os Segundos.
[FORMATO]
Define o formato da listagem que será usada pelo comando date. Os seguintes formatos são os mais usados:
%d - Dia do Mês (00-31).
%m - Mês do Ano (00-12).
%y - Ano (dois dígitos).
%Y - Ano (quatro dígitos).
%H - Hora (00-24).
%I - Hora (00-12).
%M - Minuto (00-59).
%j - Dia do ano (1-366).
%p - AM/PM (útil se utilizado com %d).
%r - Formato de 12 horas completo (hh:mm:ss AM/PM).
%T - Formato de 24 horas completo (hh:mm:ss).
%w - Dia da semana (0-6).
Outros formatos podem ser obtidos através da página de manual do date.
Para alterar a data para 25 de dezembro de 2009, 08:15, digite (usando a conta root):
date --set "2009-12-25 08:15"
Note que o comando acima atualiza a data da sessão atual, mas não mexe no relógio interno do hardware. Quando o computador for reinicializado (reboot), a data dele será a do relógio interno do hardware. Assim, o comando acima, para ter um efeito permanente, deve ser seguido de uma atualização no relógio do hardware, atráves do comando hwclock:
hwclock --systohc
ou
hwclock --set --date="2009-12-25 08:15"
Para maiores detalhes, veja a página de manual do comando date.
Cria links para arquivos e diretórios no sistema. O link é um mecanismo que faz referência a outro arquivo ou diretório em outra localização. O link em sistemas GNU/Linux faz referência reais ao arquivo/diretório podendo ser feita cópia do link (será copiado o arquivo alvo), entrar no diretório (caso o link faça referência a um diretório), etc.
ln [opções] [origem] [link]
Onde:
origem
Diretório ou arquivo de onde será feito o link.
link
Nome do link que será criado. Se já existe um arquivo de nome link, o comando ln funcionará de forma errada, criando um link para um outro arquivo. Ver abaixo para mais detalhes.
opções
-s
Cria um link simbólico. Usado para criar ligações com o arquivo/diretório de destino.
-v
Mostra o nome de cada arquivo antes de fazer o link.
-d
Cria um hard link para diretórios. Somente o root pode usar esta opção.
O link simbólico cria um arquivo especial no disco (do tipo link) que tem como conteúdo o caminho para chegar até o arquivo alvo (isto pode ser verificado pelo tamanho do arquivo do link). Use a opção -s para criar links simbólicos.
O hardlink faz referência ao mesmo inodo do arquivo original, desta forma ele será perfeitamente idêntico, inclusive nas permissões de acesso, ao arquivo original.
Ao contrário dos links simbólicos, não é possível fazer um hardlink para um diretório ou fazer referência a arquivos que estejam em partições diferentes.
Se o link já existe, o comando ln dará erro ou fará uma coisa errada. Exemplo (feito na conta usuario; use outra conta para verificar)
mkdir -p /home/usuario/teste1/arquivos # cria um diretorio
echo "teste1" > /home/usuario/teste1/arquivos/teste1.txt
mkdir -p /home/usuario/teste2/arquivos # cria um diretorio
ln -sv /home/usuario/teste1/arquivos /home/usuario/teste2/arquivos # erro
ls -lart /home/usuario/teste2
ls -lart /home/usuario/teste2/arquivos
Como pode ser visto pela sequencia acima, o erro foi criar o diretório link /home/usuario/teste2/arquivos, com isso, ao se criar o link simbolico, ele foi colocado como /home/usuario/teste2/arquivos/arquivos.
Sequencia certa:
mkdir -p /home/usuario/teste1/arquivos # cria um diretorio
echo "teste1" > /home/usuario/teste1/arquivos/teste1.txt
mkdir -p /home/usuario/teste2 # cria um diretorio
ln -sv /home/usuario/teste1/arquivos /home/usuario/teste2/arquivos # certo
ls -lart /home/usuario/teste2
ls -lart /home/usuario/teste2/arquivos
cat /home/usuario/teste2/arquivos/teste1.txt
Para remover o link, usa-se o comando rm; como este comando também é usado para apagar arquivos, é bom tomar muito cuidado antes de remover o link para não remover coisas erradas:
Procura por arquivos/diretórios no disco. find pode procurar arquivos através de sua data de modificação, tamanho, etc através do uso de opções. find, ao contrário de outros programas, usa opções longas através de um "-".
find [diretório] [opções/expressão]
Onde:
diretório
Inicia a procura neste diretório, percorrendo seu sub-diretórios.
opções/expressão
-name [expressão]
Procura pelo nome [expressão] nos nomes de arquivos e diretórios processados.
-depth
Processa os sub-diretórios primeiro antes de processar os arquivos do diretório principal.
-maxdepth [num]
Faz a procura até [num] sub-diretórios dentro do diretório que está sendo pesquisado.
-mindepth [num]
Não faz nenhuma procura em diretórios menores que [num] níveis.
-mount, -xdev
Não faz a pesquisa em sistemas de arquivos diferentes daquele de onde o comando find foi executado.
-amin [num]
Procura por arquivos que foram acessados [num] minutos atrás. Caso for antecedido por "-", procura por arquivos que foram acessados entre [num] minutos atrás até agora.
-atime [num]
Procura por arquivos que foram acessados [num] dias atrás. Caso for antecedido por "-", procura por arquivos que foram acessados entre [num] dias atrás e a data atual.
-gid [num]
Procura por arquivos que possuam a identificação numérica do grupo igual a [num].
-group [nome]
Procura por arquivos que possuam a identificação de nome do grupo igual a [nome].
-uid [num]
Procura por arquivos que possuam a identificação numérica do usuário igual a [num].
-user [nome]
Procura por arquivos que possuam a identificação de nome do usuário igual a [nome].
-inum [num]
Procura por arquivos que estão localizados no inodo [num].
-links [num]
Procura por arquivos que possuem [num] links como referência.
-mmin [num]
Procura por arquivos que tiveram seu conteúdo modificado há [num] minutos. Caso for antecedido por "-", procura por arquivos que tiveram seu conteúdo modificado entre [num] minutos atrás até agora.
-mtime [num]
Procura por arquivos que tiveram seu conteúdo modificado há [num] dias. Caso for antecedido por "-", procura por arquivos que tiveram seu conteúdo modificado entre [num] dias atrás até agora.
-ctime [num]
Procura por arquivos que teve seu status modificado há [num] dias. Caso for antecedido por "-", procura por arquivos que tiveram seu conteúdo modificado entre [num] dias atrás até agora.
-nouser
Procura por arquivos que não correspondam a identificação do usuário atual.
-nogroup
Procura por arquivos que não correspondam a identificação do grupo do usuário atual.
-perm [modo]
Procura por arquivos que possuam os modos de permissão [modo]. Os [modo] de permissão pode ser numérico (octal) ou literal.
-used [num]
O arquivo foi acessado [num] vezes antes de ter seu status modificado.
-size [num]
Procura por arquivos que tiverem o tamanho [num]. [num] pode ser antecedido de " " ou "-" para especificar um arquivo maior ou menor que [num]. A opção -size pode ser seguida de:
b - Especifica o tamanho em blocos de 512 bytes. É o padrão caso [num] não seja acompanhado de nenhuma letra.
c - Especifica o tamanho em bytes.
k - Especifica o tamanho em Kbytes.
-type [tipo]
Procura por arquivos do [tipo] especificado. Os seguintes tipos são aceitos:
b - bloco
c - caracter
d - diretório
p - pipe
f - arquivo regular
l - link simbólico
s - sockete
A maior parte dos argumentos numéricos podem ser precedidos por " " ou "-". Para detalhes sobre outras opções e argumentos, consulte a página de manual.
Exemplo:
find / -name grep - Procura no diretório raíz e sub-diretórios um arquivo/diretório chamado grep.
find / -name grep -maxdepth 3 - Procura no diretório raíz e sub-diretórios até o 3o. nível, um arquivo/diretório chamado grep.
find . -size 1000k - Procura no diretório atual e sub-diretórios um arquivo com tamanho maior que 1000 kbytes (1Mbyte).
find / -mmin 10 - Procura no diretório raíz e sub-diretórios um arquivo que foi modificado há 10 minutos atrás.
find / -links 4 - Procura no diretório raíz e sub-diretórios, todos os arquivos que possuem 4 links como referência.
find / -type d -size +1000k - Procura no diretorio raíz e sub-diretórios, diretórios maiores que 1000 kbytes.
Procura por um texto dentro de um arquivo(s) ou no dispositivo de entrada padrão.
grep [expressão] [arquivo] [opções]
Onde:
expressão
palavra ou frase que será procurada no texto. Se tiver mais de 2 palavras você deve identifica-la com aspas "" caso contrário o grep assumirá que a segunda palavra é o arquivo! Para entender melhor o funcionamento da expressão, ver o livro Expressões regulares
arquivo
Arquivo onde será feita a procura.
opções
-A [número]
Mostra o [número] de linhas após a linha encontrada pelo grep.
-B [número]
Mostra o [número] de linhas antes da linha encontrada pelo grep.
-f [arquivo]
Especifica que o texto que será localizado, esta no arquivo [arquivo].
-h, --no-filename
Não mostra os nomes dos arquivos durante a procura.
-i, --ignore-case
Ignora diferença entre maiúsculas e minúsculas no texto procurado e arquivo.
-n, --line-number
Mostra o nome de cada linha encontrada pelo grep.
-U, --binary
Trata o arquivo que será procurado como binário.
Se não for especificado o nome de um arquivo ou se for usado um hífen "-", grep procurará a string no dispositivo de entrada padrão. O grep faz sua pesquisa em arquivos texto. Use o comando zgrep para pesquisar diretamente em arquivos compactados com gzip, os comandos e opções são as mesmas.
Permite fazer a paginação de arquivos ou da entrada padrão. O comando more pode ser usado como comando para leitura de arquivos que ocupem mais de uma tela. Quando toda a tela é ocupada, o more efetua uma pausa e permite que você pressione Enter ou espaço para continuar avançando no arquivo sendo visualizado. Para sair do more pressione q.
more [arquivo]
Onde: arquivo É o arquivo que será paginado.
Para visualizar diretamente arquivos texto compactados pelo gzip.gz use o comando zmore.
Permite fazer a paginação de arquivos ou da entrada padrão. O comando less pode ser usado como comando para leitura de arquivos que ocupem mais de uma tela. Quando toda a tela é ocupada, o less efetua uma pausa (semelhante ao more) e permite que você pressione Seta para Cima e Seta para Baixo ou PgUP/PgDown para fazer o rolamento da página. Para sair do less pressione q.
less [arquivo]
Onde: arquivo É o arquivo que será paginado.
Para visualizar diretamente arquivos texto compactados pelo utilitário gzip (arquivos .gz), use o comando zless.
Organiza as linhas de um arquivo texto ou da entrada padrão. A organização é feita por linhas e as linhas são divididas em campos que é a ordem que as palavras aparecem na linha separadas por um delimitador (normalmente um espaço).
sort [opções] [arquivo]
Onde:
arquivo
É o nome do arquivo que será organizado. Caso não for especificado, será usado o dispositivo de entrada padrão (normalmente o teclado ou um "|").
opções
-b
Ignora linhas em branco.
-d
Somente usa letras, dígitos e espaços durante a organização.
-f
Ignora a diferença entre maiúsculas e minúsculas.
-r
Inverte o resultado da comparação.
-n
Caso estiver organizando um campo que contém números, os números serão organizados na ordem aritmética. Por exemplo, se você tiver um arquivo com os números
100
10
50
Usando a opção -n, o arquivo será organizado desta maneira:
10
50
100
Caso esta opção não for usada com o sort, ele organizará como uma listagem alfabética (que começam de a até z e do 0 até 9)
10
100
50
-c
Verifica se o arquivo já esta organizado. Caso não estiver, retorna a mensagem "disorder on arquivo".
-o arquivo
Grava a saída do comando sort no arquivo.
-m arquivo1arquivo2
Combina o conteúdo de arquivo1 e arquivo2 gerando um único arquivo. Os dois arquivos precisam estar ordenados antes de se utilizar esta opção.
-i
Ignora os caracteres fora da faixa octal ASCII 040-0176 durante a organização.
-t caracter
Usa caracter como delimitador durante a organização de linhas. Por padrão é usado um espaço em branco como delimitador de caracteres.
num1 -num2
Especifica qual o campo dentro na linha que será usado na organização. O(s) campo(s) usado(s) para organização estará entre num1 e num2. O delimitador padrão utilizado é um espaço em branco (use a opção -t para especificar outro). A contagem é iniciada em "0". Caso não for especificada, a organização é feita no primeiro campo. Caso -num2 não seja especificado, a organização será feita usando a coluna num1 até o fim da linha.
-k num1, num2
Esta é uma alternativa ao método acima para especificar as chaves de organização. O uso é idêntico, mas o delimitador é iniciado em "1".
Abaixo, exemplos de uso do comando sort:
sort texto.txt - Organiza o arquivo texto.txt em ordem crescente.
sort texto.txt -r - Organiza o conteúdo do arquivo texto.txt em ordem decrescente.
cat texto.txt|sort - Faz a mesma coisa que o primeiro exemplo, só que neste caso a saída do comando cat é redirecionado a entrada padrão do comando sort.
sort -f texto.txt - Ignora diferenças entre letras maiúsculas e minúsculas durante a organização.
sort 1 -3 texto.txt - Organiza o arquivo texto.txt usando como referência a segunda até a quarta palavra (segundo ao quarto campo) que constam naquela linha.
sort -t : 2 -3 passwd - Organiza o arquivo passwd usando como referência a terceira até a quarta palavra (terceiro ao quarto campo). Note que a opção -t especifica o caracter ":" como delimitador de campos ao invés do espaço. Neste caso, o que estiver após ":" será considerado o próximo campo.
Muda a data e hora que um arquivo foi criado. Também pode ser usado para criar arquivos vazios. Caso o touch seja usado com arquivos que não existam, por padrão ele criará estes arquivos.
touch [opções] [arquivos]
Onde:
arquivos
Arquivos que terão sua data/hora modificados.
opções
-t MMDDhhmm[ANO.segundos]
Usa Mês (MM), Dias (DD), Horas (hh), minutos (mm) e opcionalmente o ANO e segundos para modificação do(s) arquivos ao invés da data e hora atual.
-a, --time=atime
Faz o touch mudar somente a data e hora do acesso ao arquivo.
-c, --no-create
Não cria arquivos vazios, caso os arquivos não existam.
-m, --time=mtime
Faz o touch mudar somente a data e hora da modificação.
-r [arquivo]
Usa as horas no [arquivo] como referência ao invés da hora atual.
Exemplos:
touch teste - Cria o arquivo teste caso ele não existir.
touch -t 10011230 teste - Altera da data e hora do arquivo para 01/10 e 12:30.
touch -t 120112301999.30 teste - Altera da data, hora ano, e segundos do arquivo para 01/12/1999 e 12:30:30.
touch -t 12011200 * - Altera a data e hora do arquivo para 01/12 e 12:00.
Permite ou não o recebimentos de requisições de talk de outros usuários.
mesg [y/n]
Onde: y permite que você receba "talks" de outros usuários.
Digite mesg para saber se você pode ou não receber "talks" de outros usuários. Caso a resposta seja "n" você poderá enviar um talk para alguém mas o seu sistema se recusará em receber talks de outras pessoas.
É interessante colocar o comando mesg y em seu arquivo de inicialização .bash_profile para permitir o recebimento de "talks" toda vez que entrar no sistema.
Para detalhes sobre como se comunicar com outros usuários, veja o comando [ch-cmdn.html#s-cmdn-talk talk, Seção 11.8].
Permite o usuário mudar sua identidade para outro usuário sem fazer o logout. Útil para executar um programa ou comando como root sem ter que abandonar a seção atual.
su [usuário]
Onde: usuário é o nome do usuário que deseja usar para acessar o sistema. Se não digitado, é assumido o usuário root.
Será pedida a senha do superusuário para autenticação. Digite exit quando desejar retornar a identificação de usuário anterior.
Grava os dados do cache de disco na memória RAM para todos os discos rígidos e flexíveis do sistema. O cache um mecanismo de aceleração que permite que um arquivo seja armazenado na memória ao invés de ser imediatamente gravado no disco, quando o sistema estiver ocioso, o arquivo é gravado para o disco. O GNU/Linux procura utilizar toda memória RAM disponível para o cache de programas acelerando seu desempenho de leitura/gravação.
sync
O uso do sync é útil em disquetes quando gravamos um programa e precisamos que os dados sejam gravados imediatamente para retirar o disquete da unidade. Mas o método recomendado é especificar a opção sync durante a montagem da unidade de disquetes (para detalhes veja [ch-disc.html#s-disc-fstab fstab, Seção 5.13.1].
Retorna o nome e versão do kernel atual. Retorna também o nome dado ao computador (informação que consta do arquivo /etc/hosts ou do arquivo /etc/sysconfig/network)
uname
uname é um comando Unix que permite obter informações acerca do servidor.
Desliga/reinicia o computador imediatamente ou após determinado tempo (programável) de forma segura. Todos os usuários do sistema são avisados que o computador será desligado . Este comando somente pode ser executado pelo usuário root ou quando é usada a opção -a pelos usuários cadastrados no arquivo /etc/shutdown.allow que estejam logados no console virtual do sistema.
shutdown [opções] [hora] [mensagem]
hora
Momento que o computador será desligado. Você pode usar HH:MM para definir a hora e minuto, MM para definir minutos, SS para definir após quantos segundos, ou now para imediatamente (equivalente a 0).
O shutdown criará o arquivo /etc/nologin para não permitir que novos usuários façam login no sistema (com exceção do root). Este arquivo é removido caso a execução do shutdown seja cancelada (opção -c) ou após o sistema ser reiniciado.
mensagem
Mensagem que será mostrada a todos os usuários alertando sobre o reinicio/desligamento do sistema.
opções
-h
Inicia o processo para desligamento do computador.
-r
Reinicia o sistema
-c
Cancela a execução do shutdown. Você pode acrescentar uma mensagem avisando aos usuários sobre o fato.
-a
Permite que os nomes de usuários contidos no arquivo /etc/shutdown.allow possam utilizar o shutdown para reinicializar/desligar o sistema. Deve ser colocado um nome de usuário por linha. O limite máximo de usuários neste arquivo é de 32.
Este arquivo é útil quando o shutdown é usado para controlar o pressionamento das teclas CTRL ALT DEL no /etc/inittab.
-k
Simula o desligamento/reinicio do sistema, enviando mensagem aos usuários.
-f
Não executa a checagem do sistema de arquivos durante a inicialização do sistema. Este processo é feito gravando-se um arquivo /fastboot que é interpretado pelos scripts responsáveis pela execução do fsck durante a inicialização do sistema.
-F
Força a checagem do sistema de arquivos durante a inicialização. É gravado um arquivo chamado /forcefsck que é interpretado pelos scripts responsáveis pela execução do fsck durante a inicialização do sistema.
-n
Faz com que o shutdown ignore a execução do init fechando todos os processos.
-t [num]
Faz com que o shutdown envie um sinal de término aos processos e aguarde [num] segundos antes de enviar o sinal KILL.
O shutdown envia uma mensagem a todos os usuários do sistema alertando sobre o desligamento durante os 15 minutos restantes e assim permite que finalizem suas tarefas. Após isto, o shutdown muda o nível de execução através do comando init para 0 (desligamento), 1 (modo monousuário), 6 (reinicialização). É recomendado utilizar o símbolo "&" no final da linha de comando para que o shutdown seja executado em segundo plano.
Quando restarem apenas 5 minutos para o reinicio/desligamento do sistema, o programa login será desativado, impedindo a entrada de novos usuários no sistema.
O programa shutdown pode ser chamado pelo init através do pressionamento da combinação das teclas de reinicialização CTRL ALT DEL alterando-se o arquivo /etc/inittab. Isto permite que somente os usuários autorizados (ou o root) possam reinicializar o sistema.
Exemplos:
"shutdown -h now" - Desligar o computador imediatamente.
"shutdown -r now" - Reinicia o computador imediatamente.
"shutdown 19:00 A manutenção do servidor será iniciada í s 19:00" - Faz o computador entrar em modo monousuário (init 1) as 19:00 enviando a mensagem A manutenção do servidor será iniciada í s 19:00 a todos os usuários conectados ao sistema.
"shutdown -r 15:00 O sistema será reiniciado as 15:00 horas" - Faz o computador ser reiniciado (init 6) as 15:00 horas enviando a mensagem O sistema será reiniciado as 15:00 horas a todos os usuários conectados ao sistema.
shutdown -r 20 - Faz o sistema ser reiniciado após 20 minutos.
shutdown -c - Cancela a execução do shutdown.
shutdown -t 30 -r 20 - Reinicia o sistema após 20 minutos, espera 30 segundos após o sinal de término para enviar o sinal KILL a todos os programas abertos.
Conta o número de palavras, bytes e linhas em um arquivo ou entrada padrão. Se as opções forem omitidas, o wc mostra a quantidade de linhas, palavras, e bytes.
wc [opções] [arquivo]
Onde:
arquivo
Arquivo que será verificado pelo comando wc.
opções
-c, --bytes
Mostra os bytes do arquivo.
-w, --words
Mostra a quantidade de palavras do arquivo.
-l, --lines
Mostra a quantidade de linhas do arquivo.
A ordem da listagem dos parâmetros é única, e modificando a posição das opções não modifica a ordem que os parâmetros são listados.
Exemplo:
wc /etc/passwd - Mostra a quantidade de linhas, palavras e letras (bytes) no arquivo /etc/passwd.
wc -w /etc/passwd - Mostra a quantidade de palavras.
wc -l /etc/passwd - Mostra a quantidade de linhas.
wc -l -w /etc/passwd - Mostra a quantidade de linhas e palavras no arquivo /etc/passwd.
Modifica atributos de arquivos/diretórios. Não confunda atributos de arquivo com permissões de acesso ([ch-perm.html Permissões de acesso a arquivos e diretórios, Capítulo 13]), os atributos são diferentes e definem outras características especiais para os arquivos/diretórios especificados.
chattr [opções] [atributos] [arquivos/diretórios]
Onde:
arquivos/diretórios
Arquivos/Diretórios que terão os atributos modificados. Podem ser usados curingas
opções
-R
Modifica atributos em subdiretórios
-V
Mostra detalhes sobre a modificação de atributos.
atributos
Os atributos de arquivos/diretórios podem ser especificados da seguinte maneira:
- Adiciona o atributo
- - Remove o atributo
= - Define o atributo exatamente como especificado
Os atributos são os seguintes:
A - Não modifica a hora de acesso de arquivos. Poder aumentar consideravelmente a performance em Notebooks devido a diminuição de I/O no disco rígido. Quando especificada em diretórios, faz com que todos os arquivos e subdiretórios residentes nele não tenham a hora de acesso modificada.
Este atributo funciona apenas em kernels 2.2 e superiores
a - Append-Only - Arquivos com este atributo podem somente ser gravados em modo incrementais (o conteúdo poderá somente ser adicionado ao final do arquivo). Eles não poderão ser removidos, renomeados e novos links não poderão ser criados para estes arquivos.
Em diretórios faz com que os arquivos sejam apenas adicionados. Somente o root pode especificar ou retirar este atributo.
c - Permite compactação nos arquivos especificados de forma transparente para o usuário. Durante a leitura, o kernel retorna dados descompactados e durante a gravação os dados são compactados e gravados no disco.
Este atributo ainda não foi totalmente implementado no código atual do kernel.
d - Este atributo não é usado pelo kernel, mas faz com que o programa dump evitar backup dos arquivos marcados com este atributo.
i - Imutável - Arquivos imutáveis não podem ser modificados, os dados também não podem ser gravados para estes arquivos, não podem ser removidos, renomeados. Até mesmo o usuário root não poderá modificar estes arquivos.
Em diretórios, faz com que arquivos não possam ser adicionados ou apagados. Somente o usuário root pode especificar ou retirar este atributo.
s - O arquivo especificado é marcado como "apagamento seguro"; quando o arquivo é apagado, seus blocos são zerados e gravados de volta no disco (eliminando qualquer possibilidade de recuperação).
S - Faz a gravação imediatamente para o arquivo especificado. É como especificar a opção "sync" na montagem do sistema de arquivos ext2, mas afeta somente os arquivos especificados. Não tem efeito em diretórios.
u - O arquivo especificado é marcado como recuperável. Quando o arquivo é apagado, seu conteúdo é salvo para permitir futura recuperação.
Este atributo ainda não foi implementado totalmente no código atual do kernel.
Os atributos de arquivos/diretórios são visualizados através do utilitário lsattr. Existem patches para os kernels da série 2.2 que adicionam o suporte experimental aos atributos "c" e "u".
Exemplos:
chattr AacdiSsu teste.txt - Adiciona todos os atributos
chattr =ASs teste.txt - Define os atributos para "ASs"
chattr i -A teste.txt - Retira o atributo "A" e adiciona "i"
Lista atributos de um arquivo/diretório. Os atributos podem ser modificados através do comando chattr.
lsattr [opções] [arquivos/diretórios]
Onde:
arquivos/diretórios
Arquivos/diretórios que deseja listar os atributos. Podem ser usados curingas.
opções
-a
Lista todos os arquivos, incluindo ocultos (iniciando com um ".").
-d
Lista os atributos de diretórios ao invés de listar os arquivos que ele contém.
-R
Faz a listagem em diretórios e subdiretórios.
-v
Mostra versões dos arquivos.
Caso seja especificado sem parâmetros, o lsattr listará os atributos de todos os arquivos e diretórios do diretório atual. O lsattr mostrará mensagens de erro caso seja usado em um diretório de pontos de montagem ou arquivos que não sejam ext2.
Mostra seções de cada linha do arquivo dependendo das opções passadas ao programa.
cut [opções] [arquivo]
Onde:
arquivo
Arquivo que será verificado pelo comando cut.
opções
-b, --bytes [bytes]
Mostra somente a lista de [bytes] do arquivo.
-c, --characters [numero]
Mostra somente o [número] de caracteres no arquivo. É semelhante a opção "-b" mas tabs e espaços são tratados como qualquer caracter.
-f, --field [campos]
Mostra somente a lista de [campos].
-d, --delimite [delimitador]
Para uso com a opção -f, os campos são separados pelo primeiro caracter em [delimitador] ao invés de tabulações.
-s
Para uso com a opção -f, somente mostra linhas que contém o caracter separador de campos.
Devem ser especificadas opções para o funcionamento deste comando. Os bytes, campos e delimitadores podem ser especificados através de intervalos de caracteres (usando a-z), através de vírgulas (a,b,d) ou da combinação entre eles.
cut -b 1,3 /etc/passwd - Pega a primeira e terceira letra (byte) de cada linha do arquivo /etc/passwd
cut -b 1,3-10 /etc/passwd - Pega a primeira letra (byte) e terceira a décima letra de cada linha do arquivo /etc/passwd.
cut -c 1,3-10 /etc/passwd - Pega o primeiro caracter e terceiro ao décimo caracter de cada linha do arquivo /etc/passwd.
Compara dois arquivos de qualquer tipo (binário ou texto). Os dois arquivos especificados serão comparado e caso exista diferença entre eles, é mostrado o número da linha e byte onde ocorreu a primeira diferença na saída padrão (tela) e o programa retorna o código de saída 1.
cmp [arquivo1] [arquivo2] [opções]
Opções:
arquivo1/arquivo2
Arquivos que serão comparados.
opções
-l
Mostra o número do byte (hexadecimal) e valores diferentes de bytes (octal) para cada diferença.
-s
Não mostra nenhuma diferença, só retorna o código de saída do programa.
Use o comando zcmp para comparar diretamente arquivos binários/texto compactados com gzip.
Compara dois arquivos e mostra as diferenças entre eles. O comando diff é usado somente para a comparação de arquivos em formato texto. As diferenças encontradas podem ser redirecionadas para um arquivo que poderá ser usado pelo comando patch para aplicar as alterações em um arquivo que não contém as diferenças. Isto é útil para grandes textos porque é possível copiar somente as modificações (geradas através do diff, que são muito pequenas) e aplicar no arquivo para atualiza-lo (através do patch) ao invés de copiar a nova versão. Este é um sistema de atualização muito usado na atualização dos código fonte do kernel do GNU/Linux.
Arquivos /diretórios que serão comparados. Normalmente é usado como primeiro arquivo/diretório o mais antigo e o mais novo como segundo.
opções
-lines [num]
Gera a diferença com [num] linhas de contexto. Por padrão o diff gera um arquivo com 2 linhas que é o mínimo necessário para o correto funcionamento do patch.
-a
Compara os dois arquivos como arquivos texto.
-b
Ignora espaços em branco como diferenças.
-B
Ignora linhas em branco inseridas ou apagadas nos arquivos.
-i
Ignora diferenças entre maiúsculas e minúsculas nos arquivos.
-H
Usa análise heurística para verificar os arquivos.
-N
Em uma comparação de diretórios, se o arquivo apenas existe em um diretório, trata-o como presente mas vazio no outro diretório.
-P
Em uma comparação de diretórios, se o arquivos apenas existe no segundo diretório, trata-o como presente mas vazio no primeiro diretório.
-q
Mostra somente se os dois arquivos possuem diferenças. Não mostra as diferenças entre eles.
-r
Compara diretórios e sub-diretórios existentes.
-S [nome]
Inicia a comparação de diretórios pelo arquivo [nome]. É útil quando cancelamos uma comparação.
-t
Aumenta a tabulação das diferenças encontradas.
-u
Usa o formato de comparação unificado.
Use o comando zdiff para comparar diretamente arquivos compactados pelo utilitário gzip
Use o comando sdiff para visualizar as linhas diferentes entre os dois arquivos em formato texto simples.
Exemplo:
diff texto.txt texto1.txt - Compara o arquivo texto.txt com texto1.txt e exibe suas diferenças na tela.
diff -Bu texto.txt texto1.txt - Compara o arquivo texto.txt com texto1.txt ignorando linhas em branco diferentes entre os dois arquivos e usando o formato unificado.
diff texto.txt texto1.txt >texto.diff - Compara o arquivo texto.txt com texto1.txt e gera um arquivo chamado texto.diff contendo a diferença entre eles. Este arquivo poderá ser usado pelo patch para aplicar as diferenças existente entre os dois no arquivo texto.txt.
diff -r /usr/src/linux-2.2.13 /usr/src/linux-2.2.14 >patch-2.2.14.diff - Compara o diretório e sub-diretórios linux-2.2.13 e linux-2.2.14 e grava as diferenças entre eles no arquivo patch-2.2.14.diff.
Página arquivos texto ou a entrada padrão para impressão. Este comando faz a paginação de um arquivo texto e opcionalmente ajusta o número de colunas e mostra o resultado na saída padrão.
pr [opções] [arquivo]
Onde:
arquivo
Arquivo que será paginado para impressão.
opções
[NUM]
Inicia a numeração de páginas na página [PAGINA]
-[NUM]
Mostra a saída com [NUM] colunas.
-c
Imprime o caracter CTRL como "^" na saída padrão.
-F, -f
Usa avanço de página ao invés de linhas em branco para separar páginas.
-e[caracter][tamanho]
Usa o caracter [caracter] como tabulação (o padrão é tab) e o espaço da tabulação [tamanho].
-h [nome]
Mostra [nome] ao invés do nome do arquivo no cabeçalho.
-l [num]
Define o número máximo de linhas por página para [num].
-m
Imprime vários arquivos em paralelo, um por coluna.
-r
Oculta mensagens de erro de abertura de arquivos.
-w [num]
Ajusta a largura da página para [num] colunas (o padrão é 72).
Exemplo: pr -l 50 -h "Teste do comando pr" teste.txt.
Atualiza arquivos texto através das diferenças geradas pelo comando diff.
patch [opções] [arquivo.diff] ou patch [opções] < [arquivo.diff]
Onde:
arquivo.diff
Arquivo contendo as diferenças geradas pelo comando diff.
opções
-p [num]
Nível do diretório onde o patch será aplicado, se igual a 0, o patch assume que os arquivos que serão atualizados estão no diretório atual, se 1, assume que os arquivos que serão atualizado estão no diretório acima (..), se 2, 2 diretórios acima ...
-b
Cria cópias de segurança dos arquivos originais ao aplica o patch.
-binary
Lê e grava arquivo usando modo binário.
-d [dir]
Muda para o diretório [dir] antes de aplica o patch.
-E
Remove arquivos vazios após a aplicação do patch.
-n
Interpreta o arquivo de patch como um .diff normal.
-N
Não desfaz patches já aplicados.
-s
Não mostra mensagens de erro.
-u
Interpreta o patch em formato unificado.
As diferenças são aplicadas em arquivos originais gerados pelo comando diff. É importante entender os comandos patch e diff pois são comandos muito utilizados para desenvolvimento feito por equipes de pessoas.
Exemplo:
patch -p0<texto.diff - Aplica as diferenças contidas no arquivo texto.diff nos arquivos originais.
patch -p0 texto.txt texto.diff - Aplica as diferenças contidas no arquivo texto.diff nos arquivos originais. Faz a mesma coisa que o comando anterior.
Localiza o arquivo que contém uma página de manual. A pesquisa é feita usando-se os caminhos de páginas de manuais configuradas no sistema (normalmente o arquivo /etc/manpath.config).
Mostra a localização de um arquivo executável no sistema. A pesquisa de arquivos executáveis é feita através do path do sistema. Para maiores detalhes, veja [ch-run.html#s-run-path path, Seção 7.2].
Renomeia extensão de arquivos para .gz. Este comando é útil quando fazemos downloads de arquivos compactados pelo gzip mas que não estão identificados pela extensão .gz.
zforce [arquivos]
Quando é usado o zforce verifica se o arquivo é um arquivo compactado pelo gzip, caso seja, é verificado se já tem a extensão .gz, caso não tiver, acrescenta a extensão.
Cria arquivos compactados gzip auto-extrácteis. Este comando é usado para compactar arquivos executáveis que se auto-descompactam assim que são solicitados. É útil para sistemas ou unidades de disco que possuem pouco espaço disponível. Este comando deve somente ser usado para arquivos executáveis.
gzexe [arquivo]
Onde: arquivo é o arquivo executável que será compactado.
Quando gzexe é executado, uma cópia do arquivo original é gravada com o formato nome_do_arquivo~.
Mostra quem está atualmente conectado no computador. Este comando lista os nomes de usuários que estão conectados em seu computador, o terminal e data da conexão.
who [opções]
onde:
opções
-H, --heading
Mostra o cabeçalho das colunas.
-i, -u, --idle
Mostra o tempo que o usuário está parado em Horas:Minutos.
-m, i am
Mostra o nome do computador e usuário associado ao nome. É equivalente a digitar who i am ou who am i.
-q, --count
Mostra o total de usuários conectados aos terminais.
-T, -w, --mesg
Mostra se o usuário pode receber mensagens via talk (conversação).
O usuário recebe mensagens via talk
- O usuário não recebe mensagens via talk.
? Não foi possível determinar o dispositivo de terminal onde o usuário está conectado.
Inicia conversa com outro usuário em uma rede local ou Internet. Talk é um programa de conversação em tempo real onde uma pessoa vê o que a outra escreve.
talk [usuário] [tty]
ou
talk [usuário@host]
Onde:
usuário
Nome de login do usuário que deseja iniciar a conversação. Este nome pode ser obtido com o comando who (veja [#s-cmdn-who who, Seção 11.1]).
tty
O nome de terminal onde o usuário está conectado, para iniciar uma conexão local.
usuário@host
Se o usuário que deseja conversar estiver conectado em um computador remoto, você deve usar o nome do usuário@hosname do computador.
Após o talk ser iniciado, ele verificará se o usuário pode receber mensagens, em caso positivo, ele enviará uma mensagem ao usuário dizendo como responder ao seu pedido de conversa. Veja [#s-cmdn-who who, Seção 11.1].
Para poder fazer a rolagem para cima e para baixo no talk, pressione CTRL P(Previous - Tela anterior) e CTRL N (Next - Próxima tela). Você deve ter o daemon do talk instalado (talkd) para receber requisições de conversa.
Você deve autorizar o recebimento de talks de outros usuários para que eles possam se comunicar com você , para detalhes veja o comando [ch-cmdv.html#s-cmdv-mesg mesg, Seção 10.19].
Executa um comando em um computador local ou remoto.
rsh [opções] [IP/DNS] [comando]
Onde:
IP/DNS
Endereço IP ou nome DNS do computador.
comando
Comando que será executado no computador local/remoto.
opções
-l [nome]
Entra no sistema usando o login [nome].
rsh é usado somente para executar comandos. Para usar um shell interativo veja [#s-cmdn-telnet Telnet, Seção 11.2] e [#s-cmdn-rlogin rlogin, Seção 11.10].
Mostra o caminho percorrido por um pacote para chegar ao seu destino. Este comando mostra na tela o caminho percorrido entre os Gateways da rede e o tempo gasto de retransmissão. Este comando é útil para encontrar computadores defeituosos na rede caso o pacote não esteja chegando ao seu destino.
Algumas distribuições Linux podem não reconhecer o comando traceroute, caso isso aconteça use o seguinte código para que o shell reconheça o comando:
sudo apt-get install traceroute
Após executar esse comando o shell pede que você digite a senha de root, depois disso os pacotes necessários serão baixados.
traceroute [opções] [host/IP de destino]
Onde:
host/IP destino
É o endereço para onde o pacote será enviado (por exemplo, www.debian.org). Caso o tamanho do pacote não seja especificado, é enviado um pacote de 38 bytes.
opções
-l
Mostra o tempo de vida do pacote (ttl)
-m [num]
Ajusta a quantidade máximas de ttl dos pacotes. O padrão é 30.
-n
Mostra os endereços numericamente ao invés de usar resolução DNS.
-p [porta]
Ajusta a porta que será usada para o teste. A porta padrão é 33434.
-r
Pula as tabelas de roteamento e envia o pacote diretamente ao computador conectado a rede.
-s [end]
Usa o endereço IP/DNS [end] como endereço de origem para computadores com múltiplos endereços IPs ou nomes.
-v
Mostra mais detalhes sobre o resultado do traceroute.
-w [num]
Configura o tempo máximo que aguardará por uma resposta. O padrão é 3 segundos.
Envia uma mensagem a todos os usuários do sistema. Este comando faz a leitura de um arquivo ou entrada padrão e escreve o resultado em todos os terminais onde existem usuários conectados. Somente o usuário root pode utilizar este comando.
wall [arquivo]
Exemplos: wall /tmp/mensagem.txt, echo Teste de mensagem enviada a todos os usuários conectados ao sistema|wall.
Este capítulo traz comandos usados para manipulação de conta de usuários e grupos em sistemas GNU/Linux. Entre os assuntos descritos aqui estão adicionar usuários ao sistema, adicionar grupos, incluir usuários em grupos existentes, etc.
Adiciona um usuário ou grupo no sistema. Por padrão, quando um novo usuário é adicionado, é criado um grupo com o mesmo nome do usuário. Opcionalmente o adduser também pode ser usado para adicionar um usuário a um grupo (veja [#s-cmdc-incluirgrupo Adicionando o usuário a um grupo extra, Seção 12.10]). Será criado um diretório home com o nome do usuário (a não ser que o novo usuário criado seja um usuário do sistema) e este receberá uma identificação. A identificação do usuário (UID) escolhida será a primeira disponível no sistema especificada de acordo com a faixa de UIDS de usuários permitidas no arquivo de configuração /etc/adduser.conf. Este é o arquivo que contém os padrões para a criação de novos usuários no sistema.
adduser [opções] [usuário/grupo]
Onde:
usuário/grupo
Nome do novo usuário que será adicionado ao sistema.
opções
-disable-passwd
Não executa o programa passwd para escolher a senha e somente permite o uso da conta após o usuário escolher uma senha.
--force-badname
Desativa a checagem de senhas ruins durante a adição do novo usuário. Por padrão o adduser checa se a senha pode ser facilmente adivinhada.
--group
Cria um novo grupo em vez de um novo usuário. A criação de grupos também pode ser feita pelo comando addgroup.
-uid [num]
Cria um novo usuário com a identificação [num] em vez de um procurar o próximo UID disponível.
-gid [num]
Faz com que o usuário seja parte do grupo [gid] em vez de um pertencer a um novo grupo que será criado com seu nome. Isto é útil caso deseje permitir que grupos de usuários possam ter acesso a arquivos comuns.
Caso estiver criando um novo grupo com adduser, a identificação do novo grupo será [num].
--home [dir]
Usa o diretório [dir] para a criação do diretório home do usuário em vez de um usar o especificado no arquivo de configuração /etc/adduser.conf.
--ingroup [nome]
Quando adicionar um novo usuário no sistema, coloca o usuário no grupo [nome] em vez de criar um novo grupo.
--quiet
Não mostra mensagens durante a operação.
--system
Cria um usuário de sistema em vez de um usuário normal.
Os dados do usuário são colocados no arquivo /etc/passwd após sua criação e os dados do grupo são colocados no arquivo /etc/group.
OBSERVAÇÃO: Caso esteja usando senhas ocultas (shadow passwords), as senhas dos usuários serão colocadas no arquivo /etc/shadow e as senhas dos grupos no arquivo /etc/gshadow. Isto aumenta mais a segurança do sistema porque somente o usuário root pode ter acesso a estes arquivos, ao contrário do arquivo /etc/passwd que possui os dados de usuários e devem ser lidos por todos.
Muda a senha do usuário ou grupo. Um usuário somente pode alterar a senha de sua conta, mas o superusuário (root) pode alterar a senha de qualquer conta de usuário, inclusive a data de validade da conta, etc. Os donos de grupos também podem alterar a senha do grupo com este comando.
Os dados da conta do usuário como nome, endereço, telefone, também podem ser alterados com este comando.
passwd [usuário/grupo] [opções]
Onde:
usuário
Nome do usuário/grupo que terá sua senha alterada.
opções
-g
Se especificada, a senha do grupo será alterada. Somente o root ou o administrador do grupo pode alterar sua senha. A opção -r pode ser usada com esta para remover a senha do grupo. A opção -R pode ser usada para restringir o acesso do grupo para outros usuários.
-x [dias]
Especifica o número máximo de dias que a senha poderá ser usada. Após terminar o prazo, a senha deverá ser modificada.
-i
Desativa a conta caso o usuário não tenha alterado sua senha após o tempo especificado por -x.
-n [dias]
Especifica o número mínimo de dias para a senha ser alterada. O usuário não poderá mudar sua senha até que [dias] sejam atingidos desde a última alteração de senha.
-w [num]
Número de dias antecedentes que o usuário receberá o alerta para mudar sua senha. O alerta ocorre [num] dias antes do limite da opção -x, avisando ao usuários quantos dias restam para a troca de sua senha.
-l [nome]
Bloqueia a conta do usuário [nome]. Deve ser usada pelo root. O bloqueio da conta é feito acrescentando um caracter a senha para que não confira com a senha original.
-u [nome]
Desbloqueia a conta de um usuário bloqueada com a opção -l.
-S [nome]
Mostra o status da conta do usuário [nome]. A primeira parte é o nome do usuário seguido de L(conta bloqueada), NP(sem senha), ou P (com senha), a terceira parte é a data da última modificação da senha, a quarta parte é a período mínimo, máximo, alerta e o período de inatividade para a senha.
Procure sempre combinar letras maiúsculas, minúsculas, e números ao escolher suas senhas. Não é recomendado escolher palavras normais como sua senha pois podem ser vulneráveis a ataques de dicionários cracker. Outra recomendação é utilizar senhas ocultas em seu sistema (shadow password).
Você deve ser o dono da conta para poder modificar a senhas. O usuário root pode modificar/apagar a senha de qualquer usuário.
Altera a identificação de grupo do usuário. Para retornar a identificação anterior, digite exit e tecle Enter. Para executar um comando com outra identificação de grupo de usuário, use o comando [#s-cmdc-sg sg, Seção 12.9].
newgrp - [grupo]
Onde:
-
Se usado, inicia um novo ambiente após o uso do comando newgrp (semelhante a um novo login no sistema), caso contrário, o ambiente atual do usuário é mantido.
grupo
Nome do grupo ou número do grupo que será incluído.
Quando este comando é usado, é pedida a senha do grupo que deseja acessar. Caso a senha do grupo esteja incorreta ou não exista senha definida, a execução do comando é negada. A listagem dos grupos que pertence atualmente pode ser feita usando o comando [#s-cmdc-id id, Seção 12.12].
Apaga um usuário do sistema. Quando é usado, este comando apaga todos os dados da conta especificado dos arquivos de contas do sistema.
userdel [-r] [usuário]
Onde:
-r
Apaga também o diretório HOME do usuário.
OBS: Note que uma conta de usuário não poderá ser removida caso ele estiver no sistema, pois os programas podem precisar ter acesso aos dados dele (como UID, GID) no /etc/passwd.
Mostra o último login dos usuários cadastrados no sistema. É mostrado o nome usado no login, o terminal onde ocorreu a conexão e a hora da última conexão. Estes dados são obtidos através da pesquisa e formatação do arquivo /var/log/lastlog. Caso o usuário não tenha feito login, é mostrada a mensagem ** Never logged in **
lastlog [opções]
Onde:
opções
-t [dias]
Mostra somente os usuários que se conectaram ao sistema nos últimos [dias].
-u [nome]
Mostra somente detalhes sobre o usuário [nome].
A opção -t substitui a opção -u caso sejam usadas.
Mostra uma listagem de entrada e saída de usuários no sistema. São mostrados os seguintes campos na listagem:
Nome do usuário
Terminal onde ocorreu a conexão/desconexão
O hostname (caso a conexão tenha ocorrido remotamente) ou console (caso tenha ocorrido localmente).
A data do login/logout, a hora do login/down se estiver fora do sistema/ still logged in se ainda estiver usando o sistema
Tempo (em Horas:Minutos) que esteve conectado ao sistema.
A listagem é mostrada em ordem inversa, ou seja, da data mais atual para a mais antiga. A listagem feita pelo last é obtida de /var/log/wtmp.
last [opções]
Onde:
opções
-n [num]
Mostra [num] linhas. Caso não seja usada, todas as linhas são mostradas.
-R
Não mostra o campo HostName.
-a
Mostra o hostname na última coluna. Será muito útil se combinada com a opção -d.
-d
Usa o DNS para resolver o IP de sistemas remotos para nomes DNS.
-x
Mostra as entradas de desligamento do sistema e alterações do nível de execução do sistema.
O comando last pode ser seguido de um argumento que será pesquisado como uma expressão regular durante a listagem.
O comando last usa o arquivo /var/log/wtmp para gerar sua listagem, mas alguns sistemas podem não possuir este arquivo. O arquivo /var/log/wtmp somente é usado caso existir. Você pode cria-lo com o comando "echo -n >/var/log/wtmp" ou touch /var/log/wtmp.
last - Mostra a listagem geral
last -a - Mostra a listagem geral incluindo o nome da máquina
last gleydson - Mostra somente atividades do usuário gleydson
last reboot - Mostra as reinicializações do sistema
Executa um comando com outra identificação de grupo. A identificação do grupo de usuário é modificada somente durante a execução do comando. Para alterar a identificação de grupo durante sua seção shell, use o comando [#s-cmdc-newgrp newgrp, Seção 12.4].
sg [-] [grupo] [comando]
Onde:
-
Se usado, inicia um novo ambiente durante o uso do comando (semelhante a um novo login e execução do comando), caso contrário, o ambiente atual do usuário é mantido.
grupo
Nome do grupo que o comando será executado.
comando
Comando que será executado. O comando será executado pelo bash.
Quando este comando é usado, é pedida a senha do grupo que deseja acessar. Caso a senha do grupo esteja incorreta ou não exista senha definida, a execução do comando é negada.
Para adicionar um usuário em um novo grupo e assim permitir que ele acesse os arquivos/diretórios que pertencem í quele grupo, você deve estar como root e editar o arquivo /etc/group com o comando vigr. Este arquivo possui o seguinte formato:
NomedoGrupo:senha:GID:usuários
Onde:
NomedoGrupo
É o nome daquele grupo de usuários.
senha
Senha para ter acesso ao grupo. Caso esteja utilizando senhas ocultas para grupos, as senhas estarão em /etc/gshadow.
GID
Identificação numérica do grupo de usuário.
usuarios
Lista de usuários que também fazem parte daquele grupo. Caso exista mais de um nome de usuário, eles devem estar separados por vírgula.
Deste modo para acrescentar o usuário "joao" ao grupo audio para ter acesso aos dispositivos de som do Linux, acrescente o nome no final da linha: "audio:x:100:joao". Pronto, basta digitar logout e entrar novamente com seu nome e senha, você estará fazendo parte do grupo audio (confira digitando groups ou id).
Outros nomes de usuários podem ser acrescentados ao grupo audio bastando separar os nomes com vírgula. Você também pode usar o comando adduser da seguinte forma para adicionar automaticamente um usuário a um grupo:
adduser joao audio
Isto adicionaria o usuário "joao" ao grupo audio da mesma forma que fazendo-se a edição manualmente.
Mostra os nomes de usuários usando atualmente o sistema. Os nomes de usuários são mostrados através de espaços sem detalhes adicionais, para ver maiores detalhes sobre os usuários, veja os comandos [#s-cmdc-id id, Seção 12.12] e [ch-cmdn.html#s-cmdn-who who, Seção 11.1].
users
Os nomes de usuários atualmente conectados ao sistema são obtidos do arquivo /var/log/wtmp.
A permissão de acesso protege o sistema de arquivos Linux do acesso indevido de pessoas ou programas não autorizados.
A permissão de acesso do GNU/Linux também impede que um programa mal intencionado, por exemplo, apague um arquivo que não deve, envie arquivos para outra pessoa ou forneça acesso da rede para que outros usuários invadam o sistema. O sistema GNU/Linux é muito seguro e como qualquer outro sistema seguro e confiável impede que usuários iniciantes (ou mal intencionados) instalem programas enviados por terceiros sem saber para que eles realmente servem e causem danos irreversíveis em seus arquivos, seu micro ou sua empresa.
Esta seção pode se tornar um pouco difícil de se entender, então recomendo ler e ao mesmo tempo prática-la para uma ótima compreensão. Não se preocupe, também coloquei exemplos para ajuda-lo a entender o sistema de permissões de acesso do ambiente GNU/Linux.
O princípio da segurança no sistema de arquivos GNU/Linux é definir o acesso aos arquivos por donos, grupos e outros usuários:
dono
É a pessoa que criou o arquivo ou o diretório. O nome do dono do arquivo/diretório é o mesmo do usuário usado para entrar no sistema GNU/Linux. Somente o dono pode modificar as permissões de acesso do arquivo.
As permissões de acesso do dono de um arquivo somente se aplicam ao dono do arquivo/diretório. A identificação do dono também é chamada de user id (UID).
A identificação de usuário e o nome do grupo que pertence são armazenadas respectivamente nos arquivos /etc/passwd e /etc/group. Estes são arquivos textos comuns e podem ser editados em qualquer editor de texto, mas tenha cuidado para não modificar o campo que contém a senha do usuário encriptada (que pode estar armazenada neste arquivo caso não estiver usando senhas ocultas).
grupo
Para permitir que vários usuários diferentes tivessem acesso a um mesmo arquivo (já que somente o dono poderia ter acesso ao arquivo), este recurso foi criado. Cada usuário pode fazer parte de um ou mais grupos e então acessar arquivos que pertençam ao mesmo grupo que o seu (mesmo que estes arquivos tenham outro dono).
Por padrão, quando um novo usuário é criado, o grupo ele pertencerá será o mesmo de seu grupo primário (exceto pelas condições que explicarei adiante) (veja isto através do comando id, veja comando id, Seção 12.12). A identificação do grupo é chamada de gid (group id).
Um usuário pode pertencer a um ou mais grupos. Para detalhes de como incluir o usuário em mais grupos veja Adicionando o usuário a um grupo extra, Seção 12.10.
outros
É a categoria de usuários que não são donos ou não pertencem ao grupo do arquivo.
Cada um dos tipos acima possuem três tipos básicos de permissões de acesso que serão vistas na próxima seção.
Quanto aos tipos de permissões que se aplicam ao dono, grupo e outros usuários, temos 3 permissões básicas:
r - Permissão de leitura para arquivos. Caso for um diretório, permite listar seu conteúdo (através do comando ls, por exemplo).
w - Permissão de gravação para arquivos. Caso for um diretório, permite a gravação de arquivos ou outros diretórios dentro dele.
Para que um arquivo/diretório possa ser apagado, é necessário o acesso a gravação.
x - Permite executar um arquivo (caso seja um programa executável). Caso seja um diretório, permite que seja acessado através do comando cd (veja [ch-cmdd.html#s-comando-cd cd, Seção 8.2] para detalhes).
As permissões de acesso a um arquivo/diretório podem ser visualizadas com o uso do comando ls -la. Para maiores detalhes veja [ch-cmdd.html#s-comando-ls ls, Seção 8.1]. As 3 letras (rwx) são agrupadas da seguinte forma:
-rwxrwxrwx gleydson users teste
Virou uma bagunça não? Vou explicar cada parte para entender o que quer dizer as 10 letras acima (da esquerda para a direita):
A primeira letra diz qual é o tipo do arquivo. Caso tiver um "d" é um diretório, um "l" um link a um arquivo no sistema (veja [ch-cmdv.html#s-cmdv-ln ln, Seção 10.4] para detalhes) , um "-" quer dizer que é um arquivo comum, etc.
Da segunda a quarta letra (rwx) dizem qual é a permissão de acesso ao dono do arquivo. Neste caso gleydson ele tem a permissão de ler (r - read), gravar (w - write) e executar (x - execute) o arquivo teste.
Da quinta a sétima letra (rwx) diz qual é a permissão de acesso ao grupo do arquivo. Neste caso todos os usuários que pertencem ao grupo users tem a permissão de ler (r), gravar (w), e também executar (x) o arquivo teste.
Da oitava a décima letra (rwx) diz qual é a permissão de acesso para os outros usuários. Neste caso todos os usuários que não são donos do arquivo teste tem a permissão para ler, gravar e executar o programa.
Veja o comando [#s-perm-chmod chmod, Seção 13.7] para detalhes sobre a mudança das permissões de acesso de arquivos/diretórios.
O acesso a um arquivo/diretório é feito verificando primeiro se o usuário que acessará o arquivo é o seu dono, caso seja, as permissões de dono do arquivo são aplicadas. Caso não seja o dono do arquivo/diretório, é verificado se ele pertence ao grupo correspondente, caso pertença, as permissões do grupo são aplicadas. Caso não pertença ao grupo, são verificadas as permissões de acesso para os outros usuários que não são donos e não pertencem ao grupo correspondente ao arquivo/diretório.
Após verificar aonde o usuário se encaixa nas permissões de acesso do arquivo (se ele é o dono, pertence ao grupo, ou outros usuários), é verificado se ele terá permissão acesso para o que deseja fazer (ler, gravar ou executar o arquivo), caso não tenha, o acesso é negado, mostrando uma mensagem do tipo: "Permission denied" (permissão negada).
O que isto que dizer é que mesmo que você seja o dono do arquivo e definir o acesso do dono (através do comando chmod) como somente leitura (r) mas o acesso dos outros usuários como leitura e gravação, você somente poderá ler este arquivo mas os outros usuários poderão ler/grava-lo.
As permissões de acesso (leitura, gravação, execução) para donos, grupos e outros usuários são independentes, permitindo assim um nível de acesso diferenciado. Para maiores detalhes veja [#s-perm-tipos Tipos de Permissões de acesso, Seção 13.2].
Lembre-se: Somente o dono pode modificar um arquivo/diretório!
Para mais detalhes veja os comandos [#s-perm-chown chown, Seção 13.9] e [#s-perm-chgrp chgrp, Seção 13.8].
Abaixo dois exemplos práticos de permissão de acesso: [#s-perm-exemplo-a Exemplo de acesso a um arquivo, Seção 13.4.1] e a [#s-perm-exemplo-d Exemplo de acesso a um diretório, Seção 13.4.2]. Os dois exemplos são explicados passo a passo para uma perfeita compreensão do assunto. Vamos a prática!
Abaixo um exemplo e explicação das permissões de acesso a um arquivo no GNU/Linux (obtido com o comando ls -la, explicarei passo a passo cada parte:
-rwxr-xr—1 gleydson user 8192 nov 4 16:00 teste
-rwxr-xr--
Estas são as permissões de acesso ao arquivo teste. Um conjunto de 10 letras que especificam o tipo do arquivo, permissão do dono do arquivo, grupo do arquivo e outros usuários. Veja a explicação detalhada sobre cada uma abaixo:
-rwxr-xr--
A primeira letra (do conjunto das 10 letras) determina o tipo do arquivos. Se a letra for um d é um diretório, e você poderá acessa-lo usando o comando cd. Caso for um l é um link simbólico para algum arquivo ou diretório no sistema (para detalhes veja o comando [ch-cmdv.html#s-cmdv-ln ln, Seção 10.4] . Um - significa que é um arquivo normal.
-rwxr-xr--
Estas 3 letras (da segunda a quarta do conjunto das 10 letras) são as permissões de acesso do dono do arquivo teste. O dono (neste caso gleydson) tem a permissão para ler (r), gravar (w) e executar (x) o arquivo teste.
-rwxr-xr--
Estas 3 letras (da quinta a sétima do conjunto das 10 letras) são as permissões de acesso dos usuários que pertencem ao grupo user do arquivo teste. Os usuários que pertencem ao grupo user tem a permissão somente para ler (r) e executar (x) o arquivo teste não podendo modifica-lo ou apaga-lo.
-rwxr-xr--
Estas 3 letras (da oitava a décima) são as permissões de acesso para usuários que não são donos do arquivo teste e que não pertencem ao grupo user. Neste caso, estas pessoas somente terão a permissão para ver o conteúdo do arquivo teste.
Abaixo um exemplo com explicações das permissões de acesso a um diretório no GNU/Linux:
drwxr-x--- 2 gleydson user 1024 nov 4 17:55 exemplo
drwxr-x---
Permissões de acesso ao diretório exemplo. É um conjunto de 10 letras que especificam o tipo de arquivo, permissão do dono do diretório, grupo que o diretório pertence e permissão de acesso a outros usuários. Veja as explicações abaixo:
drwxr-x---
A primeira letra (do conjunto das 10) determina o tipo do arquivo. Neste caso é um diretório porque tem a letra d.
drwxr-x---
Estas 3 letras (da segunda a quarta) são as permissões de acesso do dono do diretório exemplo. O dono do diretório (neste caso gleydson) tem a permissão para listar arquivos do diretório (r), gravar arquivos no diretório (w) e entrar no diretório (x).
drwxr-x---
Estas 3 letras (da quinta a sétima) são as permissões de acesso dos usuários que pertencem ao grupo user. Os usuários que pertencem ao grupo user tem a permissão somente para listar arquivos do diretório (r) e entrar no diretório (x) exemplo.
drwxr-x---
Estas 3 letras (da oitava a décima) são as permissões de acesso para usuários que não são donos do diretório exemplo e que não pertencem ao grupo user. Com as permissões acima, nenhum usuário que se encaixe nas condições de dono e grupo do diretório tem a permissão de acessa-lo.
gleydson
Nome do dono do diretório exemplo.
user
Nome do grupo que diretório exemplo pertence.
exemplo
Nome do diretório.
Para detalhes de como alterar o dono/grupo de um arquivo/diretório, veja os comandos [#s-perm-chmod chmod, Seção 13.7], [#s-perm-chgrp chgrp, Seção 13.8] e [#s-perm-chown chown, Seção 13.9].
OBSERVAÇÕES:
O usuário root não tem nenhuma restrição de acesso ao sistema.
Se você tem permissões de gravação no diretório e tentar apagar um arquivo que você não tem permissão de gravação, o sistema perguntará se você confirma a exclusão do arquivo apesar do modo leitura. Caso você tenha permissões de gravação no arquivo, o arquivo será apagado por padrão sem mostrar nenhuma mensagem de erro (a não ser que seja especificada a opção -i com o comando rm).
Por outro lado, mesmo que você tenha permissões de gravação em um arquivo mas não tenha permissões de gravação em um diretório, a exclusão do arquivo será negada.
Isto mostra que é levado mais em consideração a permissão de acesso do diretório do que as permissões dos arquivos e sub-diretórios que ele contém. Este ponto é muitas vezes ignorado por muitas pessoas e expõem seu sistema a riscos de segurança. Imagine o problema que algum usuário que não tenha permissão de gravação em um arquivo mas que a tenha no diretório pode causar em um sistema mal administrado.
Em adição as três permissões básicas (rwx), existem permissões de acesso especiais (stX) que afetam arquivos executáveis e diretórios:
s - Quando é usado na permissão de acesso do Dono, ajusta a identificação efetiva do usuário do processo durante a execução de um programa, também chamado de bit setuid. Não tem efeito em diretórios.
Quando s é usado na permissão de acesso do Grupo, ajusta a identificação efetiva do grupo do processo durante a execução de um programa, chamado de bit setgid. É identificado pela letra s no lugar da permissão de execução do grupo do arquivo/diretório. Em diretórios, força que os arquivos criados dentro dele pertençam ao mesmo grupo do diretório, ao invés do grupo primário que o usuário pertence.
Ambos setgid e setuid podem aparecer ao mesmo tempo no mesmo arquivo/diretório. A permissão de acesso especial s somente pode aparecer no campo Dono e Grupo.
S - Idêntico a "s". Significa que não existe a permissão "x" (execução ou entrar no diretório) naquele lugar. Um exemplo é o chmod 2760 em um diretório.
t - Salva a imagem do texto do programa no dispositivo swap, assim ele será carregado mais rapidamente quando executado, também chamado de stick bit.
Em diretórios, impede que outros usuários removam arquivos dos quais não são donos. Isto é chamado de colocar o diretório em modo append-only. Um exemplo de diretório que se encaixa perfeitamente nesta condição é o /tmp, todos os usuários devem ter acesso para que seus programas possam criar os arquivos temporários lá, mas nenhum pode apagar arquivos dos outros. A permissão especial t, pode ser especificada somente no campo outros usuários das permissões de acesso.
T - Idêntico a "t". Significa que não existe a permissão "x" naquela posição (por exemplo, em um chmod 1776 em um diretório).
X - Se você usar X ao invés de x, a permissão de execução somente é afetada se o arquivo já tiver permissões de execução. Em diretórios ela tem o mesmo efeito que a permissão de execução x.
Exemplo da permissão de acesso especial X:
Crie um arquivo teste (digitando touch teste) e defina sua permissão para rw-rw-r-- (chmod ug=rw,o=r teste ou chmod 664 teste).
Agora use o comando chmod a X teste
digite ls -l
Veja que as permissões do arquivo não foram afetadas.
agora digite chmod o x teste
digite ls -l, você colocou a permissão de execução para os outros usuários.
Agora use novamente o comando chmod a X teste
digite ls -l
Veja que agora a permissão de execução foi concedida a todos os usuários, pois foi verificado que o arquivo era executável (tinha permissão de execução para outros usuários).
Agora use o comando chmod a-X teste
Ele também funcionará e removerá as permissões de execução de todos os usuários, porque o arquivo teste tem permissão de execução (confira digitando ls -l).
Agora tente novamente o chmod a X teste
Você deve ter reparado que a permissão de acesso especial X é semelhante a x, mas somente faz efeito quanto o arquivo já tem permissão de execução para o dono, grupo ou outros usuários.
Em diretórios, a permissão de acesso especial X funciona da mesma forma que x, até mesmo se o diretório não tiver nenhuma permissão de acesso (x).
Esta seção foi retirada do Manual de Instalação da Debian.
A conta root é também chamada de super usuário, este é um login que não possui restrições de segurança. A conta root somente deve ser usada para fazer a administração do sistema, e usada o menor tempo possível.
Qualquer senha que criar deverá conter de 6 a 8 caracteres (em sistemas usando crypto) ou até frases inteiras (caso esteja usando MD5, que garante maior segurança), e também poderá conter letras maiúsculas e minúsculas, e também caracteres de pontuação. Tenha um cuidado especial quando escolher sua senha root, porque ela é a conta mais poderosa. Evite palavras de dicionário ou o uso de qualquer outros dados pessoais que podem ser adivinhados.
Se qualquer um lhe pedir senha root, seja extremamente cuidadoso. Você normalmente nunca deve distribuir sua conta root, a não ser que esteja administrando um computador com mais de um administrador do sistema.
Utilize uma conta de usuário normal ao invés da conta root para operar seu sistema. Porque não usar a conta root? Bem, uma razão para evitar usar privilégios root é por causa da facilidade de se cometer danos irreparáveis como root. Outra razão é que você pode ser enganado e rodar um programa Cavalo de Troia -- que é um programa que obtém poderes do super usuário para comprometer a segurança do seu sistema sem que você saiba.
Muda a permissão de acesso a um arquivo ou diretório. Com este comando você pode escolher se usuário ou grupo terá permissões para ler, gravar, executar um arquivo ou arquivos. Sempre que um arquivo é criado, seu dono é o usuário que o criou e seu grupo é o grupo do usuário (exceto para diretórios configurados com a permissão de grupo "s", será visto adiante).
chmod [opções] [permissões] [diretório/arquivo]
Onde:
diretório/arquivo
Diretório ou arquivo que terá sua permissão mudada.
opções
-v, --verbose
Mostra todos os arquivos que estão sendo processados.
-f, --silent
Não mostra a maior parte das mensagens de erro.
-c, --change
Semelhante a opção -v, mas só mostra os arquivos que tiveram as permissões alteradas.
-R, --recursive
Muda permissões de acesso do diretório/arquivo no diretório atual e sub-diretórios.
ugoa -=rwxXst
:* ugoa - Controla que nível de acesso será mudado. Especificam, em ordem, usuário (u), grupo (g), outros (o), todos (a).
-= - coloca a permissão, - retira a permissão do arquivo e = define a permissão exatamente como especificado.
rwx - r permissão de leitura do arquivo. w permissão de gravação. x permissão de execução (ou acesso a diretórios).
chmod não muda permissões de links simbólicos, as permissões devem ser mudadas no arquivo alvo do link. Também podem ser usados códigos numéricos octais para a mudança das permissões de acesso a arquivos/diretórios. Para detalhes veja [#s-perm-octal Modo de permissão octal, Seção 13.10].
DICA: É possível copiar permissões de acesso do arquivo/diretório, por exemplo, se o arquivo teste.txt tiver a permissão de acesso r-xr----- e você digitar chmod o=u, as permissões de acesso dos outros usuários (o) serão idênticas ao do dono (u). Então a nova permissão de acesso do arquivo teste.txt será r-xr—r-x
Exemplos de permissões de acesso:
chmod g r *
Permite que todos os usuários que pertençam ao grupo dos arquivos (g) tenham ( ) permissões de leitura (r) em todos os arquivos do diretório atual.
chmod o-r teste.txt
Retira (-) a permissão de leitura (r) do arquivo teste.txt para os outros usuários (usuários que não são donos e não pertencem ao grupo do arquivo teste.txt).
chmod uo x teste.txt
Inclui ( ) a permissão de execução do arquivo teste.txt para o dono e outros usuários do arquivo.
chmod a x teste.txt
Inclui ( ) a permissão de execução do arquivo teste.txt para o dono, grupo e outros usuários.
chmod a=rw teste.txt
Define a permissão de todos os usuários exatamente (=) para leitura e gravação do arquivo teste.txt.
Muda dono de um arquivo/diretório. Opcionalmente pode também ser usado para mudar o grupo.
chown [opções] [dono.grupo] [diretório/arquivo]
onde:
dono.grupo
Nome do dono.grupo que será atribuído ao diretório/arquivo. O grupo é opcional.
diretório/arquivo
Diretório/arquivo que o dono.grupo será modificado.
opções
-v, --verbose
Mostra os arquivos enquanto são alterados.
-f, --supress
Não mostra mensagens de erro durante a execução do programa.
-c, --changes
Mostra somente arquivos que forem alterados.
-R, --recursive
Altera dono e grupo de arquivos no diretório atual e sub-diretórios.
O dono.grupo pode ser especificado usando o nome de grupo ou o código numérico correspondente ao grupo (GID).
Você deve ter permissões de gravação no diretório/arquivo para alterar seu dono/grupo.
chown joao teste.txt - Muda o dono do arquivo teste.txt para joao.
chown joao.users teste.txt - Muda o dono do arquivo teste.txt para joao e seu grupo para users.
chown -R joao.users * - Muda o dono/grupo dos arquivos do diretório atual e sub-diretórios para joao/users (desde que você tenha permissões de gravação no diretórios e sub-diretórios).
Ao invés de utilizar os modos de permissão r, -r, etc, pode ser usado o modo octal para se alterar a permissão de acesso a um arquivo. O modo octal é um conjunto de oito números onde cada número define um tipo de acesso diferente.
É mais flexível gerenciar permissões de acesso usando o modo octal ao invés do comum, pois você especifica diretamente a permissão do dono, grupo, outros ao invés de gerenciar as permissões de cada um separadamente. Abaixo a lista de permissões de acesso octal:
0 - Nenhuma permissão de acesso. Equivalente a -rwx.
1 - Permissão de execução (x).
2 - Permissão de gravação (w).
3 - Permissão de gravação e execução (wx).
4 - Permissão de leitura (r).
5 - Permissão de leitura e execução (rx).
6 - Permissão de leitura e gravação (rw).
7 - Permissão de leitura, gravação e execução. Equivalente a rwx.
O uso de um deste números define a permissão de acesso do dono, grupo ou outros usuários. Um modo fácil de entender como as permissões de acesso octais funcionam, é através da seguinte tabela:
1 = Executar
2 = Gravar
4 = Ler
* Para Dono e Grupo, multiplique as permissões acima por x100 e x10.
e para as permissões de acesso especiais:
1000 = Salva imagem do texto no dispositivo de troca
2000 = Ajusta o bit setgid na execução
4000 = Ajusta o bit setuid na execução
Basta agora fazer o seguinte:
Somente permissão de execução, use 1.
Somente a permissão de leitura, use 4.
Somente permissão de gravação, use 2.
Permissão de leitura/gravação, use 6 (equivale a 2 4 / Gravar Ler).
Permissão de leitura/execução, use 5 (equivale a 1 4 / Executar Ler).
Permissão de execução/gravação, use 3 (equivale a 1 2 / Executar Gravar).
Permissão de leitura/gravação/execução, use 7 (equivale a 1 2 4 / Executar Gravar Ler).
Salvar texto no dispositivo de troca, use 1000.
Ajustar bit setgid, use 2000.
Ajustar bip setuid, use 4000.
Salvar texto e ajustar bit setuid, use 5000 (equivale a 1000 4000 / Salvar texto bit setuid).
Ajustar bit setuid e setgid, use 6000 (equivale a 4000 2000 / setuid setgid).
Vamos a prática com alguns exemplos:
"chmod 764 teste"
Os números são interpretados da direita para a esquerda como permissão de acesso aos outros usuários (4), grupo (6), e dono (7). O exemplo acima faz os outros usuários (4) terem acesso somente leitura (r) ao arquivo teste, o grupo (6) ter a permissão de leitura e gravação (w), e o dono (7) ter permissão de leitura, gravação e execução (rwx) ao arquivo teste.
Outro exemplo:
"chmod 40 teste"
O exemplo acima define a permissão de acesso dos outros usuários (0) como nenhuma, e define a permissão de acesso do grupo (4) como somente leitura (r). Note usei somente dois números e então a permissão de acesso do dono do arquivo não é modificada (leia as permissões de acesso da direita para a esquerda!). Para detalhes veja a lista de permissões de acesso em modo octal no inicio desta seção.
"chmod 751 teste"
O exemplo acima define a permissão de acesso dos outros usuários (1) para somente execução (x), o acesso do grupo (5) como leitura e execução (rx) e o acesso do dono (7) como leitura, gravação e execução (rwx).
"chmod 4751 teste"
O exemplo acima define a permissão de acesso dos outros usuários (1) para somente execução (x), acesso do grupo (5) como leitura e execução (rx), o acesso do dono (7) como leitura, gravação e execução (rwx) e ajusta o bit setgid (4) para o arquivo teste.
A umask (user mask) são 3 números que definem as permissões iniciais do dono, grupo e outros usuários que o arquivo/diretório receberá quando for criado ou copiado. Digite umask sem parâmetros para retornar o valor de sua umask atual.
A umask tem efeitos diferentes caso o arquivo que estiver sendo criado for binário (um programa executável) ou texto ([ch-bas.html#s-basico-arquivo-bintext Arquivo texto e binário, Seção 2.2.3]) . Veja a tabela a seguir para ver qual é a mais adequada a sua situação:
Um arquivo texto criado com o comando umask 012;touch texto.txt receberá as permissões -rw-rw-r--, pois 0 (dono) terá permissões rw-, 1 (grupo), terá permissões rw- e 2 (outros usuários) terão permissões r--. Um arquivo binário copiado com o comando umask 012;cp /bin/ls /tmp/ls receberá as permissões -r-xr—r-x (confira com a tabela acima).
Por este motivo é preciso um pouco de atenção antes de escolher a umask, um valor mal escolhido poderia causar problemas de acesso a arquivos, diretórios ou programas não sendo executados. O valor padrão da umask na maioria das distribuições atuais é 022. A umask padrão no sistema Debian é a 022 .
A umask é de grande utilidade para programas que criam arquivos/diretórios temporários, desta forma pode-se bloquear o acesso de outros usuários desde a criação do arquivo, evitando recorrer ao chmod.
Redireciona a saída de um programa/comando/script para algum dispositivo ou arquivo ao invés do dispositivo de saída padrão (tela). Quando é usado com arquivos, este redirecionamento cria ou substitui o conteúdo do arquivo.
Por exemplo, você pode usar o comando ls para listar arquivos e usar ls >listagem para enviar a saída do comando para o arquivo listagem. Use o comando cat para visualizar o conteúdo do arquivo listagem.
O mesmo comando pode ser redirecionado para o segundo console /dev/tty2 usando: ls >/dev/tty2, o resultado do comando ls será mostrado no segundo console (pressione ALT e F2 para mudar para o segundo console e ALT e F1 para retornar ao primeiro).
Redireciona a saída de um programa/comando/script para algum dispositivo ou final de arquivo em lugar do dispositivo de saída padrão (tela). A diferença entre esse redirecionamento duplo e o simples é que, se for usado com arquivos, adiciona a saída do comando ao final do arquivo existente, em vez de substituir seu conteúdo.
Por exemplo, você pode acrescentar a saída do comando ls ao arquivo listagem do capítulo anterior usando ls / >>listagem. Use o comando cat para visualizar o conteúdo do arquivo listagem.
Direciona a entrada padrão de arquivo/dispositivo para um comando. Este comando faz o contrário do anterior, ele envia dados ao comando.
Você pode usar o comando cat < teste.txt para enviar o conteúdo do arquivo teste.txt ao comando cat que mostrará seu conteúdo (é claro que o mesmo resultado pode ser obtido com cat teste.txt mas este exemplo serviu para mostrar a funcionalidade do < ).
Este redirecionamento serve principalmente para marcar o fim de exibição de um bloco. Este é especialmente usado em conjunto com o comando cat, mas também tem outras aplicações. Por exemplo:
cat << final
este arquivo
será mostrado
até que a palavra final seja
localizada no inicio da linha
final
Envia a saída de um comando para a entrada do próximo comando para continuidade do processamento. Os dados enviados são processados pelo próximo comando que mostrará o resultado do processamento.
Por exemplo: ls -la|more, este comando faz a listagem longa de arquivos que é enviado ao comando more (que tem a função de efetuar uma pausa a cada 25 linhas do arquivo).
Outro exemplo é o comando "locate find|grep bin/", neste comando todos os caminhos/arquivos que contém find na listagem serão mostrados (inclusive man pages, bibliotecas, etc.), então enviamos a saída deste comando para grep bin/ para mostrar somente os diretórios que contém binários. Mesmo assim a listagem ocupe mais de uma tela, podemos acrescentar o more: locate find|grep bin/|more.
Podem ser usados mais de um comando de redirecionamento (<, >, |) em um mesmo comando.
A principal diferença entre o "|" e o ">", é que o Pipe envolve processamento entre comandos, ou seja, a saída de um comando é enviado a entrada do próximo e o ">" redireciona a saída de um comando para um arquivo/dispositivo.
Você pode notar pelo exemplo acima (ls -la|more) que ambos ls e more são comandos porque estão separados por um "|"! Se um deles não existir ou estiver digitado incorretamente, será mostrada uma mensagem de erro.
Um resultado diferente seria obtido usando um ">" no lugar do "|"; A saída do comando ls -la seria gravada em um arquivo chamado more.
Este capítulo descreve o que é uma rede, os principais dispositivos de rede no GNU/Linux, a identificação de cada um, como configurar os dispositivos, escolha de endereços IP, roteamento.
Parte deste capítulo, uns 70% pelo menos, é baseado no documento NET3-4-HOWTO. (seria perda de tempo reescrever este assunto pois existe um material desta qualidade já disponível).
Rede é a conexão de duas ou mais máquinas com o objetivo de compartilhar recursos entre uma máquina e outra. Os recursos podem ser:
Compartilhamento do conteúdo de seu disco rígido (ou parte dele) com outros usuários. Os outros usuários poderão acessar o disco como se estivesse instalado na própria máquina). Também chamado de servidor de arquivos.
Compartilhamento de uma impressora com outros usuários. Os outros usuários poderão enviar seus trabalhos para uma impressora da rede. Também chamado de servidor de impressão.
Compartilhamento de acesso a Internet. Outros usuários poderão navegar na Internet, pegar seus e-mails, ler noticias, bate-papo no IRC, ICQ através do servidor de acesso Internet. Também chamado de servidor Proxy.
Servidor de Internet/Intranet. Outros usuários poderão navegar nas páginas Internet localizadas em seu computador, pegar e-mails, usar um servidor de IRC para chat na rede, servidor de ICQ, etc
Com os ítens acima funcionando é possível criar permissões de acesso da rede, definindo quem terá ou não permissão para acessar cada compartilhamento ou serviço existente na máquina (www, ftp, irc, icq, etc), e registrando/avisando sobre eventuais tentativas de violar a segurança do sistema, firewalls, pontes, etc.
Entre outras ilimitadas possibilidades que dependem do conhecimento do indivíduo no ambiente GNU/Linux, já que ele permite muita flexibilidade para fazer qualquer coisa funcionar em rede.
A comunicação entre computadores em uma rede é feita através do Protocolo de Rede.
O protocolo de rede é a linguagem usada para a comunicação entre um computador e outro. Existem vários tipos de protocolos usados para a comunicação de dados, alguns são projetados para pequenas redes (como é o caso do NetBios) outros para redes mundiais (TCP/IP que possui características de roteamento).
Dentre os protocolos, o que mais se destaca atualmente é o TCP/IP devido ao seu projeto, velocidade e capacidade de roteamento.
O endereço IP são números que identificam seu computador em uma rede. Inicialmente você pode imaginar o IP como um número de telefone. O IP é compostos por quatro bytes e a convenção de escrita dos números é chamada de "notação decimal pontuada". Por convenção, cada interface (placa usada p/ rede) do computador ou roteador tem um endereço IP. Também é permitido que o mesmo endereço IP seja usado em mais de uma interface de uma mesma máquina mas normalmente cada interface tem seu próprio endereço IP.
As Redes do Protocolo Internet são sequências contínuas de endereços IP's. Todos os endereços dentro da rede tem um número de dígitos dentro dos endereços em comum. A porção dos endereços que são comuns entre todos os endereços de uma rede são chamados de porção da rede. Os dígitos restantes são chamados de porção dos hosts. O número de bits que são compartilhados por todos os endereços dentro da rede são chamados de netmask (máscara da rede) e o papel da netmask é determinar quais endereços pertencem ou não a rede. Por exemplo, considere o seguinte:
----------------- ---------------
Endereço do Host 192.168.110.23
Máscara da Rede 255.255.255.0
Porção da Rede 192.168.110.
Porção do Host .23
----------------- ---------------
Endereço da Rede 192.168.110.0
Endereço Broadcast 192.168.110.255
----------------- ---------------
Qualquer endereço que é finalizado em zero em sua netmask, revelará o endereço da rede que pertence. O endereço e rede é então sempre o menor endereço numérico dentro da escalas de endereços da rede e sempre possui a porção host dos endereços codificada como zeros.
O endereço de broadcast é um endereço especial que cada computador em uma rede "escuta" em adição a seu próprio endereço. Este é um endereço onde os datagramas enviados são recebidos por todos os computadores da rede. Certos tipos de dados como informações de roteamento e mensagens de alerta são transmitidos para o endereço broadcast, assim todo computador na rede pode recebe-las simultaneamente.
Existe dois padrões normalmente usados para especificar o endereço de broadcast. O mais amplamente aceito é para usar o endereço mais alto da rede como endereço broadcast. No exemplo acima este seria 192.168.110.255. Por algumas razões outros sites tem adotado a convenção de usar o endereço de rede como o endereço broadcast. Na prática não importa muito se usar este endereço, mas você deve ter certeza que todo computador na rede esteja configurado para escutar o mesmo endereço broadcast.
Por razões administrativas após algum pouco tempo no desenvolvimento do protocolo IP alguns grupos arbitrários de endereços foram formados em redes e estas redes foram agrupadas no que foram chamadas de classes. Estas classes armazenam um tamanho padrão de redes que podem ser usadas. As faixas alocadas são:
--------------------------------------------------------
| Classe | Máscara de | Endereço da Rede |
| | Rede | |
--------------------------------------------------------
| A | 255.0.0.0 | 0.0.0.0 - 127.255.255.255 |
| B | 255.255.0.0 | 128.0.0.0 - 191.255.255.255 |
| C | 255.255.255.0 | 192.0.0.0 - 223.255.255.255 |
|Multicast| 240.0.0.0 | 224.0.0.0 - 239.255.255.255 |
--------------------------------------------------------
O tipo de endereço que você deve utilizar depende exatamente do que estiver fazendo.
Para instalar uma máquina usando o Linux em uma rede existente
Se você quiser instalar uma máquina GNU/Linux em uma rede TCP/IP existente então você deve contactar qualquer um dos administradores da sua rede e perguntar o seguinte:
Endereço IP de sua máquina
Endereço IP da rede
Endereço IP de broadcast
Máscara da Rede IP
Endereço do Roteador
Endereço do Servidor de Nomes (DNS)
Você deve então configurar seu dispositivo de rede GNU/Linux com estes detalhes. Você não pode simplesmente escolhe-los e esperar que sua configuração funcione.
Se você estiver construindo uma rede privada que nunca será conectada a Internet, então você pode escolher qualquer endereço que quiser. No entanto, para sua segurança e padronização, existem alguns endereços IP's que foram reservados especificamente para este propósito. Eles estão especificados no RFC1597 e são os seguintes:
---------------------------------------------------------
| ENDEREÇOS RESERVADOS PARA REDES PRIVADAS |
---------------------------------------------------------
| Classe | Máscara de | Endereço da Rede |
| de Rede | Rede | |
--------- --------------- -------------------------------
| A | 255.0.0.0 | 10.0.0.0 - 10.255.255.255 |
| B | 255.255.0.0 | 172.16.0.0 - 172.31.255.255 |
| C | 255.255.255.0 | 192.168.0.0 - 192.168.255.255 |
---------------------------------------------------------
Você deve decidir primeiro qual será a largura de sua rede e então escolher a classe de rede que será usada.
As interfaces de rede no GNU/Linux estão localizadas no diretório /dev e a maioria é criada dinamicamente pelos softwares quando são requisitadas. Este é o caso das interfaces ppp e plip que são criadas dinamicamente pelos softwares.
Abaixo a identificação de algumas interfaces de rede no Linux (a ? significa um número que identifica as interfaces sequencialmente, iniciando em 0):
eth? - Placa de rede Ethernet e WaveLan.
ppp? - Interface de rede PPP (protocolo ponto a ponto).
slip? - Interface de rede serial
eql - Balanceador de tráfego para múltiplas linhas
plip? - Interface de porta paralela
arc?e, arc?s - Interfaces Arcnet
sl?, ax? - Interfaces de rede AX25 (respectivamente para kernels 2.0.xx e 2.2.xx.
fddi? - Interfaces de rede FDDI.
dlci??, sdla? - Interfaces Frame Relay, respectivamente para para dispositivos de encapsulamento DLCI e FRAD.
nr? - Interface Net Rom
rs? - Interfaces Rose
st? - Interfaces Strip (Starmode Radio IP)
tr? - Token Ring
Para maiores detalhes sobre as interfaces acima, consulte o documento NET3-4-HOWTO.
A interface loopback é um tipo especial de interface que permite fazer conexões com você mesmo. Todos os computadores que usam o protocolo TCP/IP utilizam esta interface e existem várias razões porque precisa fazer isto, por exemplo, você pode testar vários programas de rede sem interferir com ninguém em sua rede. Por convenção, o endereço IP 127.0.0.1 foi escolhido especificamente para a loopback, assim se abrir uma conexão telnet para 127.0.0.1, abrirá uma conexão para o próprio computador local.
A configuração da interface loopback é simples e você deve ter certeza que fez isto (mas note que esta tarefa é normalmente feita pelos scripts padrões de inicialização existentes em sua distribuição).
ifconfig lo 127.0.0.1
Caso a interface loopback não esteja configurada, você poderá ter problemas quando tentar qualquer tipo de conexão com as interfaces locais, tendo problemas até mesmo com o comando ping.
Atribuindo um endereço de rede a uma interface (ifconfig)
Após configurada fisicamente, a interface precisa receber um endereço IP para ser identificada na rede e se comunicar com outros computadores, além de outros parâmetros como o endereço de broadcast e a máscara de rede. O comando usado para fazer isso é o ifconfig (interface configure).
Para configurar a interface de rede Ethernet (eth0) com o endereço 192.168.1.1, máscara de rede 255.255.255.0, podemos usar o comando:
ifconfig eth0 192.168.1.1 netmask 255.255.255.0 up
O comando acima ativa a interface de rede. A palavra up pode ser omitida, pois a ativação da interface de rede é o padrão. Para desativar a mesma interface de rede, basta usar usar o comando:
ifconfig eth0 down
Digitando ifconfig são mostradas todas as interfaces ativas no momento, pacotes enviados, recebidos e colisões de datagramas. Para mostrar a configuração somente da interface eth0, use o comando: ifconfig eth0 Em sistemas Debian, o arquivo correto para especificar os dados das interfaces é o /etc/network/interfaces (veja [ch-etc.html#s-etc-network-interfaces Arquivo /etc/network/interfaces, Seção 27.8]).
Para mais detalhes, veja a página de manual do ifconfig ou o NET3-4-HOWTO.
Roteamento é quando uma máquina com múltiplas conexões de rede decide onde entregar os pacotes IP que recebeu, para que cheguem ao seu destino.
Pode ser útil ilustrar isto com um exemplo. Imagine um simples roteador de escritório, ele pode ter um link intermitente com a Internet, um número de segmentos ethernet alimentando as estações de trabalho e outro link PPP intermitente fora de outro escritório. Quando o roteador recebe um datagrama de qualquer de suas conexões de rede, o mecanismo que usa determina qual a próxima interface deve enviar o datagrama. Computadores simples também precisam rotear, todos os computadores na Internet tem dois dispositivos de rede, um é a interface loopback (explicada acima) o outro é um usado para falar com o resto da rede, talvez uma ethernet, talvez uma interface serial PPP ou SLIP.
OK, viu como o roteamento funciona? cada computador mantém uma lista de regras especiais de roteamento, chamada tabela de roteamento. Esta tabela contém colunas que tipicamente contém no mínimo três campos, o primeiro é o endereço de destino, o segundo é o nome da interface que o datagrama deve ser roteado e o terceiro é opcionalmente o endereço IP da outra máquina que levará o datagrama em seu próximo passo através da rede. No GNU/Linux você pode ver a tabela de roteamento usando um dos seguintes comandos:
cat /proc/net/route
route -n
netstat -r
O processo de roteamento é muito simples: um datagrama (pacote IP) é recebido, o endereço de destino (para quem ele é) é examinado e comparado com cada item da tabela de roteamento. O item que mais corresponder com o endereço é selecionado e o datagrama é direcionado a interface especificada.
Se o campo gateway estiver preenchido, então o datagrama é direcionado para aquele computador pela interface especificada, caso contrário o endereço de destino é assumido sendo uma rede suportada pela interface.
A configuração da rota é feita através da ferramenta route. Para adicionar uma rota para a rede 192.168.1.0 acessível através da interface eth0 basta digitar o comando:
route add -net 192.168.1.0 eth0
Para apagar a rota acima da tabela de roteamento, basta substituir a palavra add por del. A palavra net quer dizer que 192.168.1.0 é um endereço de rede (lembra-se das explicações em [#s-rede-ip Endereço IP, Seção 15.3]?)) para especificar uma máquina de destino, basta usar a palavra -host. Endereços de máquina de destino são muito usadas em conexões de rede apenas entre dois pontos (como ppp, plip, slip). Por padrão, a interface é especificada como último argumento. Caso a interface precise especifica-la em outro lugar, ela deverá ser precedida da opção -dev.
Para adicionar uma rota padrão para um endereço que não se encontre na tabela de roteamento, utiliza-se o gateway padrão da rede. Através do gateway padrão é possível especificar um computador (normalmente outro gateway) que os pacotes de rede serão enviados caso o endereço não confira com os da tabela de roteamento. Para especificar o computador 192.168.1.1 como gateway padrão usamos:
route add default gw 192.168.1.1 eth0
O gateway padrão pode ser visualizado através do comando route -n e verificando o campo gateway. A opção gw acima, especifica que o próximo argumento é um endereço IP (de uma rede já acessível através das tabelas de roteamento).
O computador gateway está conectado a duas ou mais redes ao mesmo tempo. Quando seus dados precisam ser enviados para computadores fora da rede, eles são enviados através do computador gateway e o gateway os encaminham ao endereço de destino. Desta forma, a resposta do servidor também é enviada através do gateway para seu computador (é o caso de uma típica conexão com a Internet).
DNS significa Domain Name System (sistema de nomes de domínio). O DNS converte os nomes de máquinas para endereços IPs que todas as máquinas da Internet possuem. Ele faz o mapeamento do nome para o endereço e do endereço para o nome e algumas outras coisas. Um mapeamento é simplesmente uma associação entre duas coisas, neste caso um nome de computador, como www.cipsga.org.br, e o endereço IP desta máquina (ou endereços) como 200.245.157.9.
O DNS foi criado com o objetivo de tornar as coisas mais fáceis para o usuário, permitindo assim, a identificação de computadores na Internet ou redes locais através de nomes (é como se tivéssemos apenas que decorar o nome da pessoa ao invés de um número de telefone). A parte responsável por traduzir os nomes como www.nome.com.br em um endereço IP é chamada de resolvedor de nomes.
O resolvedor de nomes pode ser um banco de dados local (controlador por um arquivo ou programa) que converte automaticamente os nomes em endereços IP ou através de servidores DNS que fazem a busca em um banco de dados na Internet e retornam o endereço IP do computador desejado. Um servidor DNS mais difundido na Internet é o bind.
Através do DNS é necessário apenas decorar o endereço sem precisar se preocupar com o endereço IP (alguns usuários simplesmente não sabem que isto existe...). Se desejar mais detalhes sobre DNS, veja o documento DNS-HOWTO.
Você deve estar acostumado com o uso dos nomes de computadores na Internet, mas pode não entender como eles são organizados. Os nomes de domínio na Internet são uma estrutura hierárquica, ou seja, eles tem uma estrutura semelhante aos diretórios de seu sistema.
Um domínio é uma família ou grupo de nomes. Um domínio pode ser colocado em um sub-domínio. Um domínio principal é um domínio que não é um sub-domínio. Os domínios principais são especificados na RFC-920. Alguns exemplos de domínios principais comuns são:
COM - Organizações Comerciais
EDU - Organizações Educacionais
GOV - Organizações Governamentais
MIL - Organizações Militares
ORG - Outras Organizações
NET - Organizações relacionadas com a Internet
Identificador do País - São duas letras que representam um país em particular.
Cada um dos domínios principais tem sub-domínios. Os domínios principais baseados no nome do país são frequentemente divididos em sub-domínios baseado nos domínios .com, .edu, .gov, .mil e .org. Assim, por exemplo, você pode finaliza-lo com: com.au e gov.au para organizações comerciais e governamentais na Austrália; note que isto não é uma regra geral, as organizações de domínio atuais dependem da autoridade na escolha de nomes de cada domínio. Quando o endereço não especifica o domínio principal, como o endereço www.unicamp.br, isto quer dizer que é uma organização acadêmica.
O próximo nível da divisão representa o nome da organização. Subdomínios futuros variam em natureza, frequentemente o próximo nível do sub-domínio é baseado na estrutura departamental da organização mas ela pode ser baseada em qualquer critério considerado razoável e significantes pelos administradores de rede para a organização.
A porção mais a esquerda do nome é sempre o nome único da máquina chamado hostname, a porção do nome a direita do hostname é chamado nome de domínio e o nome completo é chamado nome do domínio completamente qualificado (Fully Qualified Domain Name).
Usando o computador www.debian.org.br como exemplo:
br - País onde o computador se encontra
org - Domínio principal
debian - Nome de Domínio
www - Nome do computador
A localização do computador www.debian.org.br através de servidores DNS na Internet obedece exatamente a sequência de procura acima. Os administradores do domínio debian.org.br podem cadastrar quantos sub-domínios e computadores quiserem (como www.non-us.debian.org.br ou cvs.debian.org.br).
Arquivos de configuração usados na resolução de nomes
O /etc/resolv.conf é o arquivo de configuração principal do código do resolvedor de nomes. Seu formato é um arquivo texto simples com um parâmetro por linha, e os endereços de servidores DNS externos são especificados nele. Existem três palavras chaves normalmente usadas que são:
domain
Especifica o nome do domínio local.
search
Especifica uma lista de nomes de domínio alternativos ao procurar por um computador, separados por espaços. A linha search pode conter no máximo 6 domínios ou 256 caracteres.
nameserver
Especifica o endereço IP de um servidor de nomes de domínio para resolução de nomes. Pode ser usado várias vezes.
Como exemplo, o /etc/resolv.conf se parece com isto:
Este exemplo especifica que o nome de domínio a adicionar ao nome não qualificado (i.e. hostnames sem o domínio) é maths.wu.edu.au e que se o computador não for encontrado naquele domínio então a procura segue para o domínio wu.edu.au diretamente. Duas linhas de nomes de servidores foram especificadas, cada uma pode ser chamada pelo código resolvedor de nomes para resolver o nome.
O arquivo /etc/host.conf é o local onde é possível configurar alguns ítens que gerenciam o código do resolvedor de nomes. O formato deste arquivo é descrito em detalhes na página de manual resolv . Em quase todas as situações, o exemplo seguinte funcionará:
order hosts,bind
multi on
Este arquivo de configuração diz ao resolvedor de nomes para checar o arquivo /etc/hosts (parâmetro hosts) antes de tentar verificar um servidor de nomes (parâmetro bind) e retornar um endereço IP válido para o computador procurado e multi on retornará todos os endereços IP resolvidos no arquivo /etc/hosts ao invés do primeiro.
Os seguintes parâmetros podem ser adicionados para evitar ataques de IP spoofing:
nospoof on
spoofalert on
O parâmetro nospoof on ativa a resolução reversa do nome da biblioteca resolv (para checar se o endereço pertence realmente í quele nome) e o spoofalert on registra falhas desta operação no syslog.
O arquivo /etc/hosts faz o relacionamento entre um nome de computador e endereço IP local. Recomendado para IPs constantemente acessados e para colocação de endereços de virtual hosts (quando deseja referir pelo nome ao invés de IP). A inclusão de um computador neste arquivo dispenda a consulta de um servidor de nomes para obter um endereço IP, sendo muito útil para máquinas que são acessadas frequentemente. A desvantagem de fazer isto é que você mesmo precisará manter este arquivo atualizado e se o endereço IP de algum computador for modificado, esta alteração deverá ser feita em cada um dos arquivos hosts das máquinas da rede. Em um sistema bem gerenciado, os únicos endereços de computadores que aparecerão neste arquivo serão da interface loopback e os nomes de computadores.
Você pode especificar mais que um nome de computador por linha como demonstrada pela primeira linha, a que identifica a interface loopback. Certifique-se de que a entrada do nome de domínio neste arquivo aponta para a interface de rede e não para a interface loopback, ou terá problema com o comportamento de alguns serviços.
OBS: Caso encontre problemas de lentidão para resolver nomes e até para executar os aplicativos (como o mc, etc), verifique se existem erros neste arquivo de configuração.
Estes sintomas se confundem com erros de memória ou outro erro qualquer de configuração de hardware, e somem quando a interface de rede é desativada (a com o IP não loopback). Isto é causados somente pela má configuração do arquivo /etc/hosts. O bom funcionamento do Unix depende da boa atenção do administrador de sistemas para configurar os detalhes de seu servidor.
O arquivo /etc/networks tem uma função similar ao arquivo /etc/hosts. Ele contém um banco de dados simples de nomes de redes contra endereços de redes. Seu formato se difere por dois campos por linha e seus campos são identificados como:
Quando usar comandos como route, se um destino é uma rede e esta rede se encontra no arquivo /etc/networks, então o comando route mostrará o nome da rede ao invés de seu endereço.
Se você planeja executar um servidor de nomes, você pode fazer isto facilmente. Por favor veja o documento DNS-HOWTO e quaisquer documentos incluídos em sua versão do BIND (Berkeley Internet Name Domain).
Serviços de rede é o que está disponível para ser acessado pelo usuário. No TCP/IP, cada serviço é associado a um número chamado porta que é onde o servidor espera pelas conexões dos computadores clientes. Uma porta de rede pode ser referenciada tanto pelo número como pelo nome do serviço.
Abaixo, alguns exemplos de portas padrões usadas em serviços TCP/IP:
21 - FTP (transferência de arquivos)
23 - Telnet (terminal virtual remoto)
25 - Smtp (envio de e-mails)
53 - DNS (resolvedor de nomes)
79 - Finger (detalhes sobre usuários do sistema)
80 - http (protocolo www - transferência de páginas Internet)
110 - Pop-3 (recebimento de mensagens)
119 - NNTP (usado por programas de noticias)
O arquivo padrão responsável pelo mapeamento do nome dos serviços e das portas mais utilizadas é o /etc/services (para detalhes sobre o seu formato, veja a [#s-rede-outros-services /etc/services, Seção 15.9.1]).
Serviços de rede iniciados como daemons ficam residente o tempo todo na memória esperando que alguém se conecte (também chamado de modo standalone). Um exemplo de daemon é o servidor proxy squid e o servidor web Apache operando no modo daemon.
Alguns programas servidores oferecem a opção de serem executados como daemons ou através do inetd. É recomendável escolher daemon se o serviço for solicitado frequentemente (como é o caso dos servidores web ou proxy).
Para verificar se um programa está rodando como daemon, basta digitar ps ax e procurar o nome do programa, em caso positivo ele é um daemon.
Normalmente os programas que são iniciados como daemons possuem seus próprios recursos de segurança/autenticação para decidir quem tem ou não permissão de se conectar.
Serviços iniciados pelo inetd são carregados para a memória somente quando são solicitados. O controle de quais serviços podem ser carregados e seus parâmetros, são feitos através do arquivo /etc/inetd.conf.
Um daemon chamado inetd lê as configurações deste arquivo e permanece residente na memória, esperando pela conexão dos clientes. Quando uma conexão é solicitada, o daemon inetd verifica as permissões de acesso nos arquivos /etc/hosts.allow e /etc/hosts.deny e carrega o programa servidor correspondente no arquivo /etc/inetd.conf. Um arquivo também importante neste processo é o /etc/services que faz o mapeamento das portas e nomes dos serviços.
Alguns programas servidores oferecem a opção de serem executados como daemons ou através do inetd. É recomendável escolher inetd se o serviço não for solicitado frequentemente (como é o caso de servidores ftp, telnet, talk, etc).
O arquivo /etc/inetd.conf é um arquivo de configuração para o daemon servidor inetd. Sua função é dizer ao inetd o que fazer quando receber uma requisição de conexão para um serviço em particular. Para cada serviço que deseja aceitar conexões, você precisa dizer ao inetd qual daemon servidor executar e como executa-lo.
Seu formato é também muito simples. É um arquivo texto com cada linha descrevendo um serviço que deseja oferecer. Qualquer texto em uma linha seguindo uma "#" é ignorada e considerada um comentário. Cada linha contém sete campos separados por qualquer número de espaços em branco (tab ou espaços). O formato geral é o seguinte:
serviço tipo_soquete proto opções.num usuário caminho_serv. opções_serv.
serviço
É o serviço relevante a este arquivo de configuração pego do arquivo /etc/services.
tipo_soquete
Este campo descreve o tipo do soquete que este item utilizará, valores permitidos são: stream, dgram, raw, rdm, ou seqpacket. Isto é um pouco técnico de natureza, mas como uma regra geral, todos os serviços baseados em tcp usam stream e todos os protocolos baseados em udp usam dgram. Somente alguns tipos de daemons especiais de servidores usam os outros valores.
protocolo
O protocolo é considerado válido para esta item. Isto deve bater com um item apropriado no arquivo /etc/services e tipicamente será tcp ou udp. Servidores baseados no Sun RPC (Remote Procedure Call), utilizam rpc/tcp ou rpc/udp.
opções
Existem somente duas configurações para este campo. A configuração deste campo diz ao inetd se o programa servidor de rede libera o soquete após ele ser iniciado e então se inetd pode iniciar outra cópia na próxima requisição de conexão, ou se o inetd deve aguardar e assumir que qualquer servidor já em execução pegará a nova requisição de conexão.
Este é um pequeno truque de trabalho, mas como uma regra, todos os servidores tcp devem ter este parâmetro ajustado para nowait e a maior parte dos servidores udp deve tê-lo ajustado para wait. Foi alertado que existem algumas exceções a isto, assim deixo isto como exemplo se não estiver seguro.
O número especificado após o "." é opcional e define a quantidade máxima de vezes que o serviço poderá ser executado durante 1 minuto. Se o serviço for executado mais vezes do que este valor, ele será automaticamente desativado pelo inetd e uma mensagem será mostrada no log do sistema avisando sobre o fato.
Para reativar o serviço interrompido, reinicie o inetd com: killall -HUP inetd. O valor padrão é 40.
usuário
Este campo descreve que conta de usuário usuário no arquivo /etc/passwd será escolhida como dono do daemon de rede quando este for iniciado. Isto é muito útil se você deseja diminuir os riscos de segurança. Você pode ajustar o usuário de qualquer item para o usuário nobody, assim se a segurança do servidor de redes é quebrada, a possibilidade de problemas é minimizada. Normalmente este campo é ajustado para root, porque muitos servidores requerem privilégios de usuário root para funcionarem corretamente.
caminho_servidor
Este campo é o caminho para o programa servidor atual que será executado.
argumentos_servidor
Este campo inclui o resto da linha e é opcional. Você pode colocar neste campo qualquer argumento da linha de comando que deseje passar para o daemon servidor quando for iniciado.
Uma dica que pode aumentar significativamente a segurança de seu sistema é comentar (colocar uma #no inicio da linha) os serviços que não serão utilizados.
Abaixo um modelo de arquivo /etc/inetd.conf usado em sistemas Debian:
# /etc/inetd.conf: veja inetd(8) para mais detalhes.
#
# Banco de Dados de configurações do servidor Internet
#
#
# Linhas iniciando com "#:LABEL:" ou "#<off>#" não devem
# ser alteradas a não ser que saiba o que está fazendo!
#
#
# Os pacotes devem modificar este arquivo usando update-inetd(8)
#
# <nome_serviço> <tipo_soquete> <proto> <opções> <usuário> <caminho_servidor> <args>
#
#:INTERNO: Serviços internos
#echo stream tcp nowait root internal
#echo dgram udp wait root internal
#chargen stream tcp nowait root internal
#chargen dgram udp wait root internal
#discard stream tcp nowait root internal
#discard dgram udp wait root internal
#daytime stream tcp nowait root internal
#daytime dgram udp wait root internal
time stream tcp nowait root internal
#time dgram udp wait root internal
#:PADRÕES: Estes são serviços padrões.
#:BSD: Shell, login, exec e talk são protocolos BSD.
#shell stream tcp nowait root /usr/sbin/tcpd /usr/sbin/in.rshd
#login stream tcp nowait root /usr/sbin/tcpd /usr/sbin/in.rlogind
#exec stream tcp nowait root /usr/sbin/tcpd /usr/sbin/in.rexecd
talk dgram udp wait.10 nobody.tty /usr/sbin/tcpd /usr/sbin/in.talkd
ntalk dgram udp wait.10 nobody.tty /usr/sbin/tcpd /usr/sbin/in.ntalkd
#:MAIL: Mail, news e serviços uucp.
smtp stream tcp nowait.60 mail /usr/sbin/exim exim -bs
#:INFO: Serviços informativos
#:BOOT: O serviço Tftp é oferecido primariamente para a inicialização. Alguns sites
# o executam somente em máquinas atuando como "servidores de inicialização".
#:RPC: Serviços baseados em RPC
#:HAM-RADIO: serviços de rádio amador
#:OTHER: Outros serviços
Deixe-me iniciar esta seção lhe alertando que a segurança da rede em sua máquina e ataques maliciosos são uma arte complexa. Uma regra importante é: "Não ofereça serviços de rede que não deseja utilizar".
Muitas distribuições vem configuradas com vários tipos de serviços que são iniciados automaticamente. Para melhorar, mesmo que insignificantemente, o nível de segurança em seu sistema você deve editar se arquivo /etc/inetd.conf e comentar (colocar uma "#") as linhas que contém serviços que não utiliza.
Bons candidatos são serviços tais como: shell, login, exec, uucp, ftp e serviços de informação tais como finger, netstat e sysstat.
Existem todos os tipos de mecanismos de segurança e controle de acesso, eu descreverei os mais importantes deles.
O arquivo /etc/ftpusers é um mecanismo simples que lhe permite bloquear a conexão de certos usuários via ftp. O arquivo /etc/ftpusers é lido pelo programa daemon ftp (ftpd) quando um pedido de conexão é recebido. O arquivo é uma lista simples de usuários que não tem permissão de se conectar. Ele se parece com:
# /etc/ftpusers - login de usuários bloqueados via ftp
root
uucp
bin
mail
O arquivo /etc/securetty lhe permite especificar que dispositivos tty que o usuário root pode se conectar. O arquivo /etc/securetty é lido pelo programa login (normalmente /bin/login). Seu formato é uma lista de dispositivos tty onde a conexão é permitida, em todos os outros, a entrada do usuário root é bloqueada.
# /etc/securetty - terminais que o usuário root pode se conectar
tty1
tty2
tty3
tty4
O programa tcpd que você deve ter visto listado no mesmo arquivo /etc/inetd.conf, oferece mecanismos de registro e controle de acesso para os serviços que esta configurado para proteger. Ele é um tipo de firewall simples e fácil de configurar que pode evitar tipos indesejados de ataques e registrar possíveis tentativas de invasão.
Quando é executado pelo programa inetd, ele lê dos arquivos contendo regras de acesso e permite ou bloqueia o acesso ao servidor protegendo adequadamente.
Ele procura nos arquivos de regras até que uma regra confira. Se nenhuma regra conferir, então ele assume que o acesso deve ser permitido a qualquer um. Os arquivos que ele procura em sequência são: /etc/hosts.allow e /etc/hosts.deny. Eu descreverei cada um destes arquivos separadamente.
Para uma descrição completa desta facilidade, você deve verificar a página de manual apropriada (hosts_access (5) é um bom ponto de partida).
O arquivo /etc/hosts.allow é um arquivo de configuração do programa /usr/sbin/tcpd. O arquivo hosts.allow contém regras descrevendo que hosts tem permissão de acessar um serviço em sua máquina.
O formato do arquivo é muito simples:
# /etc/hosts.allow
#
# lista de serviços: lista de hosts : comando
lista de serviços
É uma lista de nomes de serviços separados por vírgula que esta regra se aplica. Exemplos de nomes de serviços são: ftpd, telnetd e fingerd.
lista de hosts
É uma lista de nomes de hosts separada por vírgula. Você também pode usar endereços IP's aqui. Adicionalmente, você pode especificar nomes de computadores ou endereço IP usando caracteres coringas para atingir grupos de hosts.
Exemplos incluem: gw.vk2ktj.ampr.org para conferir com um endereço de computador específico, .uts.edu.au para atingir qualquer endereço de computador finalizando com aquele string. Use 200.200.200. para conferir com qualquer endereço IP iniciando com estes dígitos. Existem alguns parâmetros especiais para simplificar a configuração, alguns destes são: ALL atinge todos endereços, LOCAL atinge qualquer computador que não contém um "." (ie. está no mesmo domínio de sua máquina) e PARANOID atinge qualquer computador que o nome não confere com seu endereço (falsificação de nome). Existe também um último parâmetro que é também útil: o parâmetro EXCEPT lhe permite fazer uma lista de exceções. Isto será coberto em um exemplo adiante.
comando
É um parâmetro opcional. Este parâmetro é o caminho completo de um comando que deverá ser executado toda a vez que esta regra conferir. Ele pode executar um comando para tentar identificar quem esta conectado pelo host remoto, ou gerar uma mensagem via E-Mail ou algum outro alerta para um administrador de rede que alguém está tentando se conectar.
Existem um número de expansões que podem ser incluídas, alguns exemplos comuns são: %h expande o endereço do computador que está conectado ou endereço se ele não possuir um nome, %d o nome do daemon sendo chamado.
Se o computador tiver permissão de acessar um serviço através do /etc/hosts.allow, então o /etc/hosts.deny não será consultado e o acesso será permitido.
Como exemplo:
# /etc/hosts.allow
#
# Permite que qualquer um envie e-mails
in.smtpd: ALL
# Permitir telnet e ftp somente para hosts locais e myhost.athome.org.au
in.telnetd, in.ftpd: LOCAL, myhost.athome.org.au
# Permitir finger para qualquer um mas manter um registro de quem é
in.fingerd: ALL: (finger @%h | mail -s "finger from %h" root)
Qualquer modificação no arquivo /etc/hosts.allow entrará em ação após reiniciar o daemon inetd. Isto pode ser feito com o comando kill -HUP [pid do inetd], o pid do inetd pode ser obtido com o comando ps ax|grep inetd.
O arquivo /etc/hosts.deny é um arquivo de configuração das regras descrevendo quais computadores não tem a permissão de acessar um serviço em sua máquina.
Um modelo simples deste arquivo se parece com isto:
# /etc/hosts.deny
#
# Bloqueia o acesso de computadores com endereços suspeitos
ALL: PARANOID
#
# Bloqueia todos os computadores
ALL: ALL
A entrada PARANOID é realmente redundante porque a outra entrada nega tudo. Qualquer uma destas linhas pode fazer uma segurança padrão dependendo de seu requerimento em particular.
Tendo um padrão ALL: ALL no arquivo /etc/hosts.deny e então ativando especificamente os serviços e permitindo computadores que você deseja no arquivo /etc/hosts.allow é a configuração mais segura.
Qualquer modificação no arquivo /etc/hosts.deny entrará em ação após reiniciar o daemon inetd. Isto pode ser feito com o comando kill -HUP [pid do inetd], o pid do inetd pode ser obtido com o comando ps ax|grep inetd.
O arquivo /etc/hosts.equiv é usado para garantir/bloquear certos computadores e usuários o direito de acesso aos serviços "r*" (rsh, rexec, rcp, etc) sem precisar fornecer uma senha. O /etc/shosts.equiv é equivalente mas é lido somente pelo serviço ssh. Esta função é útil em um ambiente seguro onde você controla todas as máquinas, mesmo assim isto é um perigo de segurança (veja nas observações). O formato deste arquivo é o seguinte:
O primeiro campo especifica se o acesso será permitido ou negado caso o segundo e terceiro campo confiram. Por razões de segurança deve ser especificado o FQDN no caso de nomes de máquinas. Grupos de rede podem ser especificados usando a sintaxe " @grupo".
Para aumentar a segurança, não use este mecanismo e encoraje seus usuários a também não usar o arquivo .rhosts.
ATENÇÃO O uso do sinal " " sozinho significa permitir acesso livre a qualquer pessoa de qualquer lugar. Se este mecanismo for mesmo necessário, tenha muita atenção na especificação de seus campos.
Evita também A TODO CUSTO uso de nomes de usuários (a não ser para negar o acesso), pois é fácil forjar o login, entrar no sistema tomar conta de processos (como por exemplo do servidor Apache rodando sob o usuário www-data ou até mesmo o root), causando enormes estragos.
Verificando a segurança do TCPD e a sintaxe dos arquivos
O utilitário tcpdchk é útil para verificar problemas nos arquivos hosts.allow e hosts.deny. Quando é executado ele verifica a sintaxe destes arquivos e relata problemas, caso eles existam.
Outro utilitário útil é o tcpdmatch, o que ele faz é permitir que você simule a tentativa de conexões ao seu sistema e observar ser ela será permitida ou bloqueada pelos arquivos hosts.allow e hosts.deny.
É importante mostrar na prática como o tcpdmatch funciona através de um exemplo simulando um teste simples em um sistema com a configuração padrão de acesso restrito:
O arquivo hosts.allow contém as seguintes linhas:
ALL: 127.0.0.1
in.talkd, in.ntalkd: ALL
in.fingerd: 192.168.1. EXCEPT 192.168.1.30
A primeira linha permite o loopback (127.0.0.1) acessar qualquer serviço TCP/UDP em nosso computador, a segunda linha permite qualquer um acessar os servidor TALK (nós desejamos que o sistema nos avise quando alguém desejar conversar) e a terceira somente permite enviar dados do finger para computadores dentro de nossa rede privada (exceto para 192.168.1.30).
O arquivo hosts.deny contém a seguinte linha:
ALL: ALL
Qualquer outra conexão será explicitamente derrubada.
Vamos aos testes, digitando: "tcpdmatch in.fingerd 127.0.0.1" (verificar se o endereço 127.0.0.1 tem acesso ao finger):
client: address 127.0.0.1
server: process in.fingerd
matched: /etc/hosts.allow line 1
access: granted
Ok, temos acesso garantido com especificado pela linha 1 do hosts.allow (a primeira linha que confere é usada). Agora "tcpdmatch in.fingerd 192.168.1.29":
client: address 192.168.1.29
server: process in.fingerd
matched: /etc/hosts.allow line 3
access: granted
O acesso foi permitido através da linha 3 do hosts.allow. Agora "tcpdmatch in.fingerd 192.168.1.29":
client: address 192.168.1.30
server: process in.fingerd
matched: /etc/hosts.deny line 1
access: denied
O que aconteceu? como a linha 2 do hosts.allow permite o acesso a todos os computadores 192.168.1.* exceto 192.168.1.30, ela não bateu, então o processamento partiu para o hosts.deny que nega todos os serviços para qualquer endereço. Agora um último exemplo: "tcpdmatch in.talkd www.debian.org"
client: address www.debian.org
server: process in.talkd
matched: /etc/hosts.allow line 2
access: granted
Ok, na linha 2 qualquer computador pode te chamar para conversar via talk na rede, mas para o endereço DNS conferir com um IP especificado, o GNU/Linux faz a resolução DNS, convertendo o endereço para IP e verificando se ele possui acesso.
No lugar do endereço também pode ser usado a forma daemon@computador ou cliente@computador para verificar respectivamente o acesso de daemons e cliente de determinados computadores aos serviços da rede.
Como pode ver o TCPD ajuda a aumentar a segurança do seu sistema, mas não confie nele além do uso em um sistema simples, é necessário o uso de um firewall verdadeiro para controlar minuciosamente a segurança do seu sistema e dos pacotes que atravessam os protocolos, roteamento e as interfaces de rede. Se este for o caso aprenda a trabalhar a fundo com firewalls e implemente a segurança da sua rede da forma que melhor planejar.
Dentre todos os métodos de segurança, o Firewall é o mais seguro. A função do Firewall é bloquear determinados tipos de tráfego de um endereço ou para uma porta local ou permitir o acesso de determinados usuários mas bloquear outros, bloquear a falsificação de endereços, redirecionar tráfego da rede, ping da morte, etc.
A implementação de um bom firewall dependerá da experiência, conhecimentos de rede (protocolos, roteamento, interfaces, endereçamento, masquerade, etc), da rede local, e sistema em geral do Administrador de redes, a segurança de sua rede e seus dados dependem da escolha do profissional correto, que entenda a fundo o TCP/IP, roteamento, protocolos, serviços e outros assuntos ligados a rede.
Frequentemente tem se ouvido falar de empresas que tiveram seus sistemas invadidos, em parte isto é devido a escolha do sistema operacional indevido mas na maioria das vezes o motivo é a falta de investimento da empresa em políticas de segurança, que algumas simplesmente consideram a segurança de seus dados e sigilo interno como uma despesa a mais.
Um bom firewall que recomendo é o ipchains, Sinus e o TIS. Particularmente gosto muito de usar o ipchains e o Sinus e é possível fazer coisas inimagináveis programando scripts para interagirem com estes programas...
Outros arquivos de configuração relacionados com a rede
O arquivo /etc/services é um banco de dados simples que associa um nome amigável a humanos a uma porta de serviço amigável a máquinas. É um arquivo texto de formato muito simples, cada linha representa um item no banco de dados. Cada item é dividido em três campos separados por qualquer número de espaços em branco (tab ou espaços). Os campos são:
nome porta/protocolo apelido # comentário
name
Uma palavra simples que representa o nome do serviço sendo descrito.
porta/protocolo
Este campo é dividido em dois sub-campos.
porta - Um número que especifica o número da porta em que o serviço estará disponível. Muitos dos serviços comuns tem designados um número de serviço. Estes estão descritos no RFC-1340.
protocolo - Este sub-campo pode ser ajustado para tcp ou udp. É importante notar que o item 18/tcp é muito diferente do item 18/udp e que não existe razão técnica porque o mesmo serviço precisa existir em ambos. Normalmente o senso comum prevalece e que somente se um serviço esta disponível em ambos os protocolos tcp e udp, você precisará especificar ambos.
apelidos
Outros nomes podem ser usados para se referir a entrada deste serviço.
comentário
Qualquer texto aparecendo em uma linha após um caracter "#" é ignorado e tratado como comentário.
O arquivo /etc/protocols é um banco de dados que mapeia números de identificação de protocolos novamente em nomes de protocolos. Isto é usado por programadores para permiti-los especificar protocolos por nomes em seus programas e também por alguns programas tal como tcpdump permitindo-os mostrar nomes ao invés de números em sua saída. A sintaxe geral deste arquivo é:
É a peça central do sistema operacional (o Linux), é ele que controla os dispositivos e demais periféricos do sistema (como memória, placas de som, vídeo, discos rígidos, disquetes, sistemas de arquivos, redes e outros recursos disponíveis). Muitos confundem isto e chamam a distribuição de sistema operacional. Isto é errado!
O kernel faz o controle dos periféricos do sistema e para isto ele deve ter o seu suporte incluído. Para fazer uma placa de som Sound Blaster funcionar, por exemplo, é necessário que o kernel ofereça suporte a este placa e você deve configurar seus parâmetros (como interrupção, I/O e DMA) com comandos específicos para ativar a placa e faze-la funcionar corretamente. Existe um documento que contém quais são os periféricos suportados/ não suportados pelo GNU/Linux, ele se chama Hardware-HOWTO.
Suas versões são identificadas por números como 2.2.30, 2.4.33, 2.6.23.6, as versões que contém um número par entre o primeiro e segundo ponto são versões estáveis e que contém números ímpares neste mesmo local são versões instáveis (em desenvolvimento). Usar versões instáveis não quer dizer que ocorrerá travamentos ou coisas do tipo, mas algumas partes do kernel podem não estar testadas o suficiente ou alguns controladores podem ainda estar incompletos para obter pleno funcionamento. Se opera sua máquina em um ambiente crítico, prefira pegar versões estáveis do kernel.
Após inicializar o sistema, o kernel e seus arquivos podem ser acessados ou modificados através do ponto de montagem /proc. Para detalhes veja [ch-disc.html#s-disc-proc O sistema de arquivos /proc, Seção 5.8].
Caso você tenha um dispositivo (como uma placa de som) que tem suporte no GNU/Linux mas não funciona veja [#s-kern-suporte Como adicionar suporte a Hardwares e outros dispositivos no kernel, Seção 16.3].
São partes do kernel que são carregadas somente quando são solicitadas por algum aplicativo ou dispositivo e descarregadas da memória quando não são mais usadas. Este recurso é útil por 2 motivos: Evita a construção de um kernel grande (estático) que ocupe grande parte da memória com todos os drivers compilados e permite que partes do kernel ocupem a memória somente quando forem necessários.
Os módulos do kernel estão localizados no diretório /lib/modules/versão_do_kernel/* (onde versão_do_kernel é a versão atual do kernel em seu sistema, caso seja 2.6.23.6 o diretório que contém seus módulos será /lib/modules/2.6.23.6.
Os módulos são carregados automaticamente quando solicitados através do programa kmod ou manualmente através do arquivo /etc/modules , insmod ou modprobe. Atenção: Não compile o suporte ao seu sistema de arquivos raíz como módulo, isto o tornará inacessível, a não ser que esteja usando initrd.
Como adicionar suporte a Hardwares e outros dispositivos no kernel
Quando seu hardware não funciona mas você tem certeza que é suportado pelo GNU/Linux, é preciso seguir alguns passos para faze-lo funcionar corretamente:
Verifique se o kernel atual foi compilado com suporte ao seu dispositivo. Também é possível que o suporte ao dispositivo esteja compilado como módulo. Dê o comando dmesg para ver as mensagens do kernel durante a inicialização e verifique se aparece alguma coisa referente ao dispositivo que deseja instalar (alguma mensagem de erro, etc). Caso não aparecer nada é possível que o driver esteja compilado como módulo, para verificar isto entre no diretório /lib/modules/versao_do_kernel e veja se encontra o módulo correspondente ao seu dispositivo (o módulo da placa NE 2000 tem o nome de ne.ko e o da placa Sound Blaster de sb.ko, por exemplo).
OBS: Nos kernel 2.4 e anteriores, a extensão dos módulos era .o.
Caso o kernel não tiver o suporte ao seu dispositivo, você precisará recompilar seu kernel ativando seu suporte. Veja [#s-kern-recompilando Recompilando o Kernel, Seção 16.11].
Caso seu hardware esteja compilado no kernel, verifique se o módulo correspondente está carregado (com o comando lsmod). Caso não estiver, carregue-o com o modprobe (por exemplo, modprobe sb io=0x220 irq=5 dma=1 dma16=5 mpuio=0x330), para detalhes veja [#s-kern-modprobe modprobe, Seção 16.8].
O uso deste comando deverá ativar seu hardware imediatamente, neste caso configure o módulo para ser carregado automaticamente através do programa modconf ou edite os arquivos relacionados com os módulos (veja [#s-kern-arquivos Arquivos relacionados com o Kernel e Módulos, Seção 16.12]). Caso não tenha sucesso, será retornada uma mensagem de erro.
Este é o programa usado para carregar os módulos automaticamente quando são requeridos pelo sistema. Ele é um daemon que funciona constantemente fazendo a monitoração, quando verifica que algum dispositivo ou programa está solicitando o suporte a algum dispositivo, ele carrega o módulo correspondente.
Ele pode ser desativado através da recompilação do kernel, dando um kill no processo ou através do arquivo /etc/modules (veja [#s-kern-arquivos-modules /etc/modules, Seção 16.12.1]. Caso seja desativado, é preciso carregar manualmente os módulos através do modprobe ou insmod.
Lista quais módulos estão carregados atualmente pelo kernel. O nome lsmod é uma contração de ls módulos - Listar Módulos. A listagem feita pelo lsmod é uma alternativa ao uso do comando cat /proc/modules.
A saída deste comando tem a seguinte forma:
Module Size Pages Used by
nls_iso8859_1 8000 1 1 (autoclean)
nls_cp437 3744 1 1 (autoclean)
ne 6156 2 1
8390 8390 2 [ne] 0
A coluna Module indica o nome do módulo que está carregado, a coluna Used mostra qual módulos está usando aquele recurso. O parâmetro (autoclean) no final da coluna indica que o módulo foi carregado manualmente (pelo insmod ou modprobe) ou através do kmod e será automaticamente removido da memória quando não for mais usado.
No exemplo acima os módulos ne e 8390 não tem o parâmetro (autoclean) porque foram carregados pelo arquivo /etc/modules (veja [#s-kern-arquivos-modules /etc/modules, Seção 16.12.1]). Isto significa que não serão removidos da memória caso estiverem sem uso.
Qualquer módulo carregado pode ser removido manualmente através do comandos rmmod.
Carrega um módulo manualmente. Para carregar módulos que dependem de outros módulos para que funcionem, você duas opções: Carregar os módulos manualmente ou usar o modprobe que verifica e carrega as dependências correspondentes.
A sintaxe do comando é: insmod [módulo] [opções_módulo]
Onde:
módulo
É o nome do módulo que será carregado.
opções_módulo
Opções que serão usadas pelo módulo. Variam de módulo para módulo, alguns precisam de opções outros não, tente primeiro carregar sem opções, caso seja mostrada uma mensagem de erro verifique as opções usadas por ele. Para detalhes sobre que opções são suportadas por cada módulo, veja a sua documentação no código fonte do kernel em /usr/src/linux/Documentation
Remove módulos carregados no kernel. Para ver os nomes dos módulos atualmente carregados no kernel digite lsmod e verifique na primeira coluna o nome do módulo. Caso um módulo tenha dependências e você tentar remover suas dependências, uma mensagem de erro será mostrada alertando que o módulo está em uso.
Carrega um módulo e suas dependências manualmente. Este comando permite carregar diversos módulos e dependências de uma só vez. O comportamento do modprobe é modificado pelo arquivo /etc/modules.conf .
O programa deve ser rodado pela conta root.
A sintaxe deste comando é: modprobe [módulo] [opções_módulo]
Onde:
módulo
É o nome do módulo que será carregado.
opções_módulo
Opções que serão usadas pelo módulo. Variam de módulo para módulo, alguns precisam de opções outros não, tente primeiro carregar sem opções, caso seja mostrada uma mensagem de erro verifique as opções usadas por ele. Para detalhes sobre que opções são suportadas por cada módulo, veja a sua documentação no código fonte do kernel em /usr/src/linux/Documentation
Nem todos os módulos são carregados corretamente pelo modprobe, o plip, por exemplo, mostra uma mensagem sobre porta I/O inválida mas não caso seja carregado pelo insmod.
Existem casos em que dois ou mais módulos suportam o mesmo device, ou um módulo alega suportar mas tem bug. Para isto, pode-se usar a palavra mágica blacklist no arquivo /etc/modprobe.d/blacklist para ignorar estes módulos.
Existem duas formas de colocar um módulo na lista negra, dependendo do método usado para carregá-lo e do modo como ele é configurado.
Um método é editando o arquivo /etc/modprobe.d/blacklist na forma abaixo:
O segundo método é mais complicado[1] mas parece ser mais potente (ou seja, pode resolver casos em que o método acima não funciona). Consiste em editar o arquivo que instalaria estes módulos problemáticos, e forçar a instalação como /bin/true. Por exemplo:
Verifica a dependência de módulos. As dependências dos módulos são verificadas pelos scripts em /etc/init.d usando o comando depmod -a e o resultado gravado no arquivo /lib/modules/versao_do_kernel/modules.dep. Esta checagem serve para que todas as dependências de módulos estejam corretamente disponíveis na inicialização do sistema. O comportamento do depmod pode ser modificado através do arquivo /etc/modules.conf . É possível criar a dependência de módulos imediatamente após a compilação do kernel digitando depmod -a [versão_do_kernel].
Este programa permite um meio mais fácil de configurar a ativação de módulos e opções através de uma interface através de menus. Selecione a categoria de módulos através das setas acima e abaixo e pressione enter para selecionar os módulos existentes. Serão pedidas as opções do módulo (como DMA, IRQ, I/O) para que sua inicialização seja possível, estes parâmetros são específicos de cada módulo e devem ser vistos na documentação do código fonte do kernel no diretório /usr/src/linux/Documentation. Note que também existem módulos com auto-detecção mas isto deixa o sistema um pouco mais lento, porque ele fará uma varredura na faixa de endereços especificados pelo módulo para achar o dispositivo. As opções são desnecessárias em alguns tipos de módulos.
As modificações feitas por este programa são gravadas no diretório /etc/modutils em arquivos separados como /etc/modutils/alias - alias de módulos, /etc/modutils/modconf - opções usadas por módulos, /etc/modutils/paths - Caminho onde os módulos do sistema são encontrados. Dentro de /etc/modutils é ainda encontrado um sub-diretório chamado arch que contém opções específicas por arquiteturas.
A sincronização dos arquivos gerados pelo modconf com o /etc/modules.conf é feita através do utilitário update-modules. Ele é normalmente executado após modificações nos módulos feitas pelo modconf.
Será que vou precisar recompilar o meu kernel? você deve estar se perguntando agora. Abaixo alguns motivos para esclarecer suas dúvidas:
Melhora o desempenho do kernel. O kernel padrão que acompanha as distribuições GNU/Linux foi feito para funcionar em qualquer tipo de sistema e garantir seu funcionamento e inclui suporte a praticamente tudo. Isto pode gerar desde instabilidade até uma grade pausa do kernel na inicialização quando estiver procurando pelos dispositivos que simplesmente não existem em seu computador!
A compilação permite escolher somente o suporte aos dispositivos existentes em seu computador e assim diminuir o tamanho do kernel, desocupar a memória RAM com dispositivos que nunca usará e assim você terá um desempenho bem melhor do que teria com um kernel pesado.
Incluir suporte a alguns hardwares que estão desativados no kernel padrão (SMP, APM, ACPI, Virtualização, Firewall, Bridge, memory cards, drivers experimentais, etc).
Se aventurar em compilar um kernel (sistema operacional) personalizado em seu sistema.
Tornar seu sistema mais seguro
Impressionar os seus amigos, tentando coisas novas.
Serão necessários uns 300Mb de espaço em disco disponível para copiar e descompactar o código fonte do kernel e alguns pacotes de desenvolvimento como o gcc, cpp, binutils, gcc-i386-gnu, bin86, make, dpkg-dev, perl, kernel-package (os três últimos somente para a distribuição Debian).
Na distribuição Debian, o melhor método é através do kernel-package que faz tudo para você (menos escolher o que terá o não o suporte no kernel) e gera um pacote .deb que poderá ser usado para instalar o kernel em seu sistema ou em qualquer outro que execute a Debian ou distribuições baseadas (Ubuntu, etc). Devido a sua facilidade, a compilação do kernel através do kernel-package é muito recomendado para usuários iniciantes e para aqueles que usam somente um kernel no sistema (é possível usar mais de dois ao mesmo tempo, veja o processo de compilação manual adiante neste capítulo). Siga este passos para recompilar seu kernel através do kernel-package:
Descompacte o código fonte do kernel (através do arquivo linux-2.6.XX.XX.tar.bz2) para o diretório /usr/src. Caso use os pacotes da Debian eles terão o nome de kernel-source-2.6.XX.XX, para detalhes de como instalar um pacote, veja [ch-dpkg.html#s-dpkg-instalar Instalar pacotes, Seção 20.1.2].
Após isto, entre no diretório onde o código fonte do kernel foi instalado com cd /usr/src/linux (este será assumido o lugar onde o código fonte do kernel se encontra).
Como usuário root, digite make config. Você também pode usar make menuconfig (configuração através de menus) ou make xconfig (configuração em modo gráfico) mas precisará de pacotes adicionais para que estes dois funcionem corretamente.
Serão feitas perguntas sobre se deseja suporte a tal dispositivo, etc. Pressione Y para incluir o suporte diretamente no kernel, M para incluir o suporte como módulo ou N para não incluir o suporte. Note que nem todos os drivers podem ser compilados como módulos.
Escolha as opções que se encaixam em seu sistema. se estiver em dúvida sobre a pergunta digite ? e tecle Enter para ter uma explicação sobre o que aquela opção faz. Se não souber do que se trata, recomendo incluir a opção (pressionando Y ou M. Este passo pode levar entre 5 minutos e 1 Hora (usuários que estão fazendo isto pela primeira vez tendem a levar mais tempo lendo e conhecendo os recursos que o GNU/Linux possui, antes de tomar qualquer decisão). Não se preocupe se esquecer de incluir o suporte a alguma coisa, você pode repetir o passo make config (todas as suas escolhas são gravadas no arquivo .config), recompilar o kernel e instalar em cima do antigo a qualquer hora que quiser.
Após o make config chegar ao final, digite make-kpkg clean para limpar construções anteriores do kernel.
Agora compile o kernel digitando make-kpkg—revision=teste.1.0 kernel-image. A palavra teste pode ser substituída por qualquer outra que você quiser e número da versão 1.0 serve apenas como controle de suas compilações (pode ser qualquer número).
Observação: Não inclua hífens (-) no parâmetro—revision, use somente pontos.
Agora após compilar, o kernel será gravado no diretório superior (..) com um nome do tipo linux-image-2.6.23.6-i386_teste.1.0.deb. Basta você digitar dpkg -i kernel-image-2.6.23.6-i386_teste.1.0.deb e o dpkg fará o resto da instalação do kernel para você e perguntará se deseja criar um disquete de inicialização (recomendável).
Reinicie seu computador, seu novo kernel iniciará e você já perceberá a primeira diferença pela velocidade que o GNU/Linux é iniciado (você inclui somente suporte a dispositivos em seu sistema). O desempenho dos programas também melhorará pois cortou o suporte a dispositivos/funções que seu computador não precisa.
Caso alguma coisa sair errada, coloque o disquete que gravou no passo anterior e reinicie o computador para fazer as correções.
Para recompilar o kernel usando o método manual, siga os seguintes passos:
Descompacte o código fonte do kernel (através do arquivo linux-2.6.XX.XX.tar.bz2) para o diretório /usr/src. O código fonte do kernel pode ser encontrado em ftp://ftp.kernel.org/.
Após isto, entre no diretório onde o código fonte do kernel foi instalado com cd /usr/src/linux (este será assumido o lugar onde o código fonte do kernel se encontra).
Como usuário root, digite make config. Você também pode usar make menuconfig (configuração através de menus) ou make xconfig (configuração em modo gráfico) mas precisará de pacotes adicionais.
Serão feitas perguntas sobre se deseja suporte a tal dispositivo, etc. Pressione Y para incluir o suporte diretamente no kernel, M para incluir o suporte como módulo ou N para não incluir o suporte. Note que nem todos os drivers podem ser compilados como módulos.
Escolha as opções que se encaixam em seu sistema. se estiver em dúvida sobre a pergunta digite ? e tecle Enter para ter uma explicação sobre o que aquela opção faz. Se não souber do que se trata, recomendo incluir a opção (pressionando Y ou M. Este passo pode levar entre 5 minutos e 1 Hora (usuários que estão fazendo isto pela primeira vez tendem a levar mais tempo lendo e conhecendo os recursos que o GNU/Linux possui antes de tomar qualquer decisão). Não se preocupe se esquecer de incluir o suporte a alguma coisa, você pode repetir o passo make config, recompilar o kernel e instalar em cima do antigo a qualquer hora que quiser.
Caso esteja compilando um kernel 2.4 ou inferior, Digite o comando make dep para verificar as dependências dos módulos. Se estiver compilando um kernel 2.6 ou superior, pule esse comando.
Digite o comando make clean para limpar construções anteriores do kernel.
Digite o comando make para iniciar a compilação do kernel e seus módulos. Aguarde a compilação, o tempo pode variar dependendo da quantidade de recursos que adicionou ao kernel, a velocidade de seu computador e a quantidade de memória RAM disponível.
Caso tenha acrescentado muitos ítens no Kernel, é possível que o comando make zImage falhe no final (especialmente se o tamanho do kernel estático for maior que 505Kb). Neste caso use make bzImage. A diferença entre zImage e bzImage é que o primeiro possui um limite de tamanho porque é descompactado na memória básica (recomendado para alguns Notebooks), já a bzImage, é descompactada na memória estendida e não possui as limitações da zImage.
A compilação neste ponto está completa, você agora tem duas opções para instalar o kernel: Substituir o kernel anterior pelo recém compilado ou usar os dois. A segunda questão é recomendável se você não tem certeza se o kernel funcionará corretamente e deseja iniciar pelo antigo no caso de alguma coisa dar errado.
Se você optar por substituir o kernel anterior:
É recomendável renomear o diretório /lib/modules/versão_do_kernel para /lib/modules/versão_do_kernel.old, isto será útil para restauração completa dos módulos antigos caso alguma coisa der errado.
Execute o comando make modules_install para instalar os módulos do kernel recém compilado em /lib/modules/versão_do_kernel.
Copie o arquivo zImage que contém o kernel de /usr/src/linux/arch/i386/boot/zImage para /boot/vmlinuz-2.XX.XX (2.XX.XX é a versão do kernel anterior)
Verifique se o link simbólico /vmlinuz aponta para a versão do kernel que compilou atualmente (com ls -la /). Caso contrário, apague o arquivo /vmlinuz do diretório raíz e crie um novo link com ln -s /boot/vmlinuz-2.XX.Xx /vmlinuz apontando para o kernel correto.
Execute o comando lilo para gerar um novo setor de partida no disco rígido. Para detalhes veja [ch-boot.html#s-boot-lilo LILO, Seção 6.1].
Reinicie o sistema (shutdown -r now).
Caso tudo esteja funcionando normalmente, apague o diretório antigo de módulos que salvou e o kernel antigo de /boot. Caso algo tenha dado errado e seu sistema não inicializa, inicie a partir de um disquete, apague o novo kernel, apague os novos módulos, renomeie o diretório de módulos antigos para o nome original, ajuste o link simbólico /vmlinuz para apontar para o antigo kernel e execute o lilo. Após reiniciar seu computador voltará como estava antes.
Se você optar por manter o kernel anterior e selecionar qual será usado na partida do sistema (útil para um kernel em testes):
Execute o comando make modules_install para instalar os módulos recém compilados do kernel em /lib/modules/versao_do_kernel.
Copie o arquivo zImage que contém o kernel de /usr/src/linux/arch/i386/boot/zImage para /boot/vmlinuz-2.XX.XX (2.XX.XX é a versão do kernel anterior)
Crie um link simbólico no diretório raíz (/) apontando para o novo kernel. Como exemplos será usado /vmlinuz-novo.
Modifique o arquivo /etc/lilo.conf para incluir a nova imagem de kernel. Por exemplo:
Se você digitar 1 no aviso de boot: do Lilo, o kernel antigo será carregado, caso digitar 2 o novo kernel será carregado. Para detalhes veja [ch-boot.html#s-boot-lilo-cfg Criando o arquivo de configuração do LILO, Seção 6.1.1] e [ch-boot.html#s-boot-lilo-exemplo Um exemplo do arquivo de configuração lilo.conf, Seção 6.1.3].
Execute o comando lilo para gravar o novo setor de boot para o disco rígido.
Reinicie o computador
Carregue o novo kernel escolhendo a opção 2 no aviso de boot: do Lilo. Caso tiver problemas, escolha a opção 1 para iniciar com o kernel antigo e verifique os passos de configuração (o arquivo lilo.conf foi modificado corretamente?.
Em alguns casos (como nos kernels empacotados em distribuições GNU/Linux) o código fonte do kernel é gravado em um diretório chamado kernel-source-xx.xx.xx. É recomendável fazer um link com um diretório GNU/Linux, pois é o padrão usado pelas atualização do código fonte através de patches (veja [#s-kern-patches Aplicando Patches no kernel, Seção 16.13]).
Para criar o link simbólico, entre em /usr/src e digite: ln -s kernel-source-xx.xx.xx linux.
Se quiser mais detalhes sobre a compilação do kernel, consulte o documento kernel-howto.
A função deste arquivo é carregar módulos especificados na inicialização do sistema e mantê-los carregado todo o tempo. É útil para módulos de placas de rede que precisam ser carregados antes da configuração de rede feita pela distribuição e não podem ser removidos quando a placa de rede estiver sem uso (isto retiraria seu computador da rede).
Seu conteúdo é uma lista de módulos (um por linha) que serão carregados na inicialização do sistema. Os módulos carregados pelo arquivo /etc/modules pode ser listados usando o comando lsmod (veja [#s-kern-lsmod lsmod, Seção 16.5].
Se o parâmetro auto estiver especificado como um módulo, o kmod será ativado e carregará os módulos somente em demanda, caso seja especificado noauto o programa kmod será desativado. O kmod é ativado por padrão nos níveis de execução 2 ao 5.
Ele pode ser editado em qualquer editor de textos comum ou modificado automaticamente através do utilitário modconf.
O arquivo /etc/modules.conf permite controlar as opções de todos os módulos do sistema. Ele é consultado pelos programas modprobe e depmod. As opções especificadas neste arquivo facilita o gerenciamento de módulos, evitando a digitação de opções através da linha de comando.
Note que é recomendado o uso do utilitário modconf para configurar quaisquer módulos em seu sistema e o utilitário update-modules para sincronização dos arquivos gerados pelo modconf em /etc/modutils com o /etc/modules.conf (geralmente isto é feito automaticamente após o uso do modconf). Por este motivo não é recomendável modifica-lo manualmente, a não ser que seja um usuário experiente e saiba o que está fazendo. Veja [#s-kern-modconf modconf, Seção 16.10]
Por exemplo: adicionando as linhas:
alias sound sb
options sb io=0x220 irq=5 dma=1 dma16=5 mpuio=0x330
permitirá que seja usado somente o comando modprobe sb para ativar a placa de som.
Patches são modificações geradas pelo programa diff em que servem para atualizar um programa ou texto. Este recurso é muito útil para os desenvolvedores, pois podem gerar um arquivo contendo as diferenças entre um programa antigo e um novo (usando o comando diff) e enviar o arquivo contendo as diferenças para outras pessoas.
As pessoas interessadas em atualizar o programa antigo, podem simplesmente pegar o arquivo contendo as diferenças e atualizar o programa usando o patch.
Isto é muito usado no desenvolvimento do kernel do GNU/Linux em que novas versões são lançadas frequentemente e o tamanho kernel completo compactado ocupa cerca de 18MB. Você pode atualizar seu kernel pegando um patch seguinte a versão que possui em ftp://ftp.kernel.org/.
Para aplicar um patch que atualizará seu kernel 2.6.23 para a versão 2.6.24 você deve proceder da seguinte forma:
Descompacte o código fonte do kernel 2.6.23 em /usr/src/linux ou certifique-se que existe um link simbólico do código fonte do kernel para /usr/src/linux.
Use o comando gzip -dc patch-2.6.24|patch -p0 -N -E para atualizar o código fonte em /usr/src/linux para a versão 2.6.24.
Alternativamente você pode primeiro descompactar o arquivo patch-2.6.24.gz com o gzip e usar o comando patch -p0 -N -E <patch-2.6.24 para atualizar o código fonte do kernel. O GNU/Linux permite que você obtenha o mesmo resultado através de diferentes métodos, a escolha é somente sua.
Caso deseja atualizar o kernel 2.6.20 para 2.6.24, como no exemplo acima, você deverá aplicar os patches em sequência (do patch 2.6.20 ao 2.6.24). Vale a pena observar se o tamanho total dos patches ultrapassa ou chega perto o tamanho do kernel completo, pois dependendo da quantidade de alterações pode ser mais viável baixar diretamente a nova versão.
Esta seção explica o que são e como usar programas compactadores no GNU/Linux, as características de cada um, como identificar um arquivo compactado e como descompactar um arquivo compactado usando o programa correspondente.
A utilização de arquivos compactados é método útil principalmente para reduzir o consumo de espaço em disco ou permitir grandes quantidades de texto serem transferidas para outro computador através de disquetes.
Compactadores são programas que diminuem o tamanho de um arquivo (ou arquivos) através da substituição de caracteres repetidos. Para entender melhor como eles funcionam, veja o próximo exemplo:
compactadores compactam e deixam arquivos compactados.
-- após a compactação da frase --
%dores %m e deixam arquivos %dos
O que aconteceu realmente foi que a palavra compacta se encontrava 3 vezes na frase acima, e foi substituída por um sinal de %. Para descompactar o processo seria o contrário: Ele substituiria % por compacta e nós temos a frase novamente restaurada.
Você deve ter notado que o tamanho da frase compactada caiu quase pela metade. A quantidade de compactação de um arquivo é chamada de taxa de compactação. Assim se o tamanho do arquivo for diminuído a metade após a compactação, dizemos que conseguiu uma taxa de compactação de 2:1 (lê-se dois para um), se o arquivo diminuiu 4 vezes, dizemos que conseguiu uma compactação de 4:1 (quatro para um) e assim por diante.
Para controle dos caracteres que são usados nas substituições, os programas de compactação mantém cabeçalhos com todas as substituições usadas durante a compactação. O tamanho do cabeçalho pode ser fixo ou definido pelo usuário, depende do programa usado na compactação.
Este é um exemplo bem simples para entender o que acontece durante a compactação, os programas de compactação executam instruções muito avançadas e códigos complexos para atingir um alta taxa de compactação.
Observações:
Não é possível trabalhar diretamente com arquivos compactados! É necessário descompactar o arquivo para usa-lo. Note que alguns programas atualmente suportam a abertura de arquivos compactados, mas na realidade eles apenas simplificam a tarefa descompactando o arquivo, abrindo e o recompactando assim que o trabalho estiver concluído.
Arquivos de texto tem uma taxa de compactação muito melhor que arquivos binários, porque possuem mais caracteres repetidos. É normal atingir taxas de compactação de 10 para 1 ou mais quando se compacta um arquivo texto. Arquivos binários, como programas, possuem uma taxa de compactação média de 2:1.
Note que também existem programas compactadores especialmente desenvolvidos para compactação de músicas, arquivos binários, imagens, textos.
Existem basicamente dois tipos de compactação, a compactação sem perdas e a compactação com perdas.
Os exemplos a seguir tentam explicar de forma simples os conceitos envolvidos.
A compactação sem perdas, como o próprio nome diz não causa nenhuma perda nas informações contidas no arquivo. Quando você compacta e descompacta um arquivo, o conteúdo é o mesmo do original.
A compactação com perdas é um tipo específico de compactação desenvolvido para atingir altas taxas, porém com perdas parciais dos dados. É aplicada a tipos de arquivos especiais, como músicas e imagens ou arquivos que envolvam a percepção humana.
Sabe-se que o ouvido humano não é tão sensível a determinados sons e frequências, então a compactação de um arquivo de música poderia deixar de gravar os sons que seriam pouco percebidos, resultando em um arquivo menor. Uma compactação do tipo ogg ou mp3 utiliza-se destes recursos. O arquivo resultante é muito menor que o original, porém alguns dados sonoros são perdidos. Você só notaria se estivesse reproduzindo a música em um equipamento de alta qualidade e se tivesse um ouvido bem aguçado. Para efeitos práticos, você está ouvindo a mesma música e economizando muito espaço em disco.
Outro exemplo de compactação com perdas são as imagens jpg. Imagine que você tem uma imagem com 60000 tons de cor diferentes, mas alguns tons são muito próximos de outros, então o compactador resume para 20000 tons de cor e a imagem terá 1/3 do tamanho original e o nosso olho conseguirá entender a imagem sem problemas e quase não perceberá a diferença. Exemplos de extensões utilizadas em imagens compactadas são jpg, png, gif.
Apesar das vantagens da grande taxa de compactação conseguida nos processos com perdas, nem sempre podemos utilizá-lo. Quando compactamos um texto ou um programa, não podemos ter perdas, senão o nosso texto sofre alterações ou o programa não executa. Nem mesmo podemos tem perdas quando compactamos imagens ou musicas que serão utilizadas em processos posteriores de masterização, mixagem ou impressão em alta qualidade.
As extensões identificam o tipo de um arquivo e assim o programa o programa necessário para trabalhar com aquele tipo de arquivo. Existem dezenas de extensões que identificam arquivos compactados. Quando um arquivo (ou arquivos) é compactado, uma extensão correspondente ao programa usado é adicionada ao nome do arquivo (caso o arquivo seja compactado pelo gzip receberá a extensão .gz, por exemplo). Ao descompactar acontece o contrário: a extensão é retirada do arquivo. Abaixo segue uma listagem de extensões mais usadas e os programas correspondentes:
.gz - Arquivo compactado pelo gzip. Use o programa gzip para descompacta-lo (para detalhes veja [#s-cpctd-gzip gzip, Seção 18.3]). .bz2 - Arquivo compactado pelo bzip2. Use o programa bzip2 para descompacta-lo (para detalhes veja [#s-cpctd-bzip2 bzip2, Seção 18.7]).
.Z - Arquivo compactado pelo programa compress. Use o programa uncompress para descompacta-lo.
.zip - Arquivo compactado pelo programa zip. Use o programa unzip para descompacta-lo.
.rar - Arquivo compactado pelo programa rar. Use o programa rar para descompacta-lo.
.tar.gz - Arquivo compactado pelo programa gzip no utilitário de arquivamento tar. Para descompacta-lo, você pode usar o gzip e depois o tar ou somente o programa tar usando a opção -z. Para detalhes veja [#s-cpctd-gzip gzip, Seção 18.3] e [#s-cpctd-tar tar, Seção 18.6].
.tgz - Abreviação de .tar.gz.
.tar.bz2 - Arquivo compactado pelo programa bzip2 no utilitário de arquivamento tar. Para descompacta-lo, você pode usar o bzip2 e depois o tar ou somente o programa tar usando a opção -j. Para detalhes veja [#s-cpctd-bzip2 bzip2, Seção 18.7] e [#s-cpctd-tar tar, Seção 18.6].
.tar.Z - Arquivo compactado pelo programa compress no utilitário de arquivamento tar. Para descompacta-lo, você pode usar o uncompress e depois o tar ou somente o programa tar usando a opção -Z. Para detalhes veja [#s-cpctd-tar tar, Seção 18.6].
É praticamente o compactador padrão do GNU/Linux, possui uma ótima taxa de compactação e velocidade. A extensão dos arquivos compactados pelo gzip é a .gz, na versão para DOS, Windows NT é usada a extensão .z.
gzip [opções] [arquivos]
Onde:
arquivos
Especifica quais arquivos serão compactados pelo gzip. Caso seja usado um -, será assumido a entrada padrão. Curingas podem ser usados para especificar vários arquivos de uma só vez (veja [ch-bas.html#s-basico-curingas Curingas, Seção 2.12]).
Opções
-d, --decompress [arquivo]
Descompacta um arquivo.
-f
Força a compactação, compactando até mesmo links.
-l [arquivo]
Lista o conteúdo de um arquivo compactado pelo gzip.
-r
Compacta diretórios e sub-diretórios.
-c [arquivo]
Descompacta o arquivo para a saída padrão.
-t [arquivo]
Testa o arquivo compactado pelo gzip.
-[num], --fast, --best
Ajustam a taxa de compactação/velocidade da compactação. Quanto melhor a taxa menor é a velocidade de compactação e vice versa. A opção --fast permite uma compactação rápida e tamanho do arquivo maior. A opção --best permite uma melhor compactação e uma velocidade menor.
O uso da opção -[número] permite especificar uma compactação individualmente usando números entre 1 (menor compactação) e 9 (melhor compactação). É útil para buscar um bom equilibro entre taxa de compactação/velocidade (especialmente em computadores muito lentos).
Quando um arquivo é compactado pelo gzip, é automaticamente acrescentada a extensão .gz ao seu nome.
O gzip também reconhece arquivos compactados pelos programas zip, compress, compress -H e pack. As permissões de acesso dos arquivos são também armazenadas no arquivo compactado.
Exemplos:
gzip -9 texto.txt - Compacta o arquivo texto.txt usando a compactação máxima (compare o tamanho do arquivo compactado usando o comando ls -la).
gzip -d texto.txt.gz - Descompacta o arquivo texto.txt
gzip -c texto.txt.gz - Descompacta o arquivo texto.txt para a tela
gzip -9 *.txt - Compacta todos os arquivos que terminam com .txt
gzip -t texto.txt.gz - Verifica o arquivo texto.txt.gz.
Utilitário de compactação compatível com pkzip (do DOS) e trabalha com arquivos de extensão .zip. Possui uma ótima taxa de compactação e velocidade no processamento dos arquivos compactados (comparando-se ao gzip).
zip [opções] [arquivo-destino] [arquivos-origem]
Onde:
arquivo-destino
Nome do arquivo compactado que será gerado.
arquivos-origem
Arquivos/Diretórios que serão compactados. Podem ser usados curingas para especificar mais de um arquivo de uma só vez (veja [ch-bas.html#s-basico-curingas Curingas, Seção 2.12]).
opções
-r
Compacta arquivos e sub-diretórios.
-e
Permite encriptar o conteúdo de um arquivo .zip através de senha. A senha será pedida no momento da compactação.
-f
Somente substitui um arquivo compactado existente dentro do arquivo .zip somente se a versão é mais nova que a atual. Não acrescenta arquivos ao arquivo compactado. Deve ser executado no mesmo diretório onde o programa zip foi executado anteriormente.
-F
Repara um arquivo .zip danificado.
-[NUM]
Ajusta a qualidade/velocidade da compactação. Pode ser especificado um número de 1 a 9. O 1 permite mínima compactação e máxima velocidade, 9 permite uma melhor compactação e menor velocidade.
-i [arquivos]
Compacta somente os [arquivos] especificados.
-j
Se especificado, não armazena caminhos de diretórios.
-m
Apaga os arquivos originais após a compactação.
-T [arquivo]
Procura por erros em um arquivo .zip. Caso sejam detectados problemas, utilize a opção -F para corrigi-los.
-y
Armazena links simbólicos no arquivo .zip. Por padrão, os links simbólicos são ignorados durante a compactação.
-k [arquivo]
Modifica o [arquivo] para ter compatibilidade total com o pkzip do DOS.
-l
Converte saltos de linha UNIX (LF) para o formato CR LF (usados pelo DOS). Use esta opção com arquivos Texto.
-ll
Converte saltos de linha DOS (CR LF) para o formato UNIX (LF). Use esta opção com arquivos texto.
-n [extensão]
Não compacta arquivos identificados por [extensão]. Ele é armazenado sem compactação no arquivo .zip, muito útil para uso com arquivos já compactados.
Caso sejam especificados diversas extensões de arquivos, elas devem ser separadas por : - Por exemplo, zip -n .zip:.tgz arquivo.zip *.txt.
-q
Não mostra mensagens durante a compactação do arquivo.
-u
Atualiza/adiciona arquivos ao arquivo .zip
-X
Não armazena detalhes de permissões, UID, GID e datas dos arquivos.
-z
Permite incluir um comentário no arquivo .zip.
Caso o nome de arquivo de destino não termine com .zip, esta extensão será automaticamente adicionada. Para a descompactação de arquivos .zip no GNU/Linux, é necessário o uso do utilitário unzip. Exemplos:
zip textos.zip *.txt - Compacta todos os arquivos com a extensão .txt para o arquivo textos.zip (compare o tamanho do arquivo compactado digitando ls -la).
zip -r textos.zip /usr/*.txt - Compacta todos os arquivos com a extensão .txt do diretório /usr e sub-diretórios para o arquivo textos.zip.
zip -9 textos.zip * - Compacta todos os arquivos do diretório atual usando a compactação máxima para o arquivo textos.zip.
zip -T textos.zip - Verifica se o arquivo textos.zip contém erros.
Nome do arquivo que deseja descompactar. Podem ser usados curingas para especificar mais de um arquivo para ser descompactado.
arquivos-extrair
Nome dos arquivos (separados por espaço) que serão descompactados do arquivo .zip. Caso não seja especificado, é assumido * (todos os arquivos serão descompactados).
Se for usado -x arquivos, os arquivos especificados não serão descompactados. O uso de curingas é permitido.
-d diretório
Diretório onde os arquivos serão descompactados. Caso não for especificado, os arquivos serão descompactados no diretório atual.
opções
-c
Descompacta os arquivos para stdout (saída padrão) ao invés de criar arquivos. Os nomes dos arquivos também são mostrados (veja a opção -p).
-f
Descompacta somente arquivos que existam no disco e mais novos que os atuais.
-l
Lista os arquivos existentes dentro do arquivo .zip.
-M
Efetua uma pausa a cada tela de dados durante o processamento (a mesma função do comando more).
-n
Nunca substitui arquivos já existentes. Se um arquivo existe ele é pulado.
-o
Substitui arquivos existentes sem perguntar. Tem a função contrária a opção -n.
-P [SENHA]
Permite descompactar arquivos .zip usando a [SENHA]. CUIDADO! qualquer usuário conectado em seu sistema pode ver a senha digitada na linha de comando digitada.
-p
Descompacta os arquivos para stdout (saída padrão) ao invés de criar arquivos. Os nomes dos arquivos não são mostrados (veja a opção -c).
-q
Não mostra mensagens.
-t
Verifica o arquivo .zip em busca de erros.
-u
Idêntico a opção -f só que também cria arquivos que não existem no diretório.
-v
Mostra mais detalhes sobre o processamento do unzip.
-z
Mostra somente o comentário existente no arquivo.
Por padrão o unzip também descompacta sub-diretórios caso o arquivo .zip tenha sido gerado com zip -r.
Exemplos:
unzip texto.zip - Descompacta o conteúdo do arquivo texto.zip no diretório atual.
unzip texto.zip carta.txt - Descompacta somente o arquivo carta.txt do arquivo texto.zip.
unzip texto.zip -d /tmp/texto - Descompacta o conteúdo do arquivo texto.zip para o diretório /tmp/texto.
unzip -l texto.zip - Lista o conteúdo do arquivo texto.zip.
unzip -t texto.zip - Verifica o arquivo texto.zip.
Na verdade o tar não é um compactador e sim um "arquivador" (ele junta vários arquivos em um só), mas pode ser usado em conjunto com um compactar (como o gzip ou zip) para armazena-los compactados. O tar também é muito usado para cópias de arquivos especiais ou dispositivos do sistema. É comum encontrar arquivos com a extensão .tar, .tar.gz, .tgz, .tar.bz2, .tar.Z, .tgZ, o primeiro é um arquivo normal gerado pelo tar e todos os outros são arquivos gerados através tar junto com um programa de compactação (gzip (.gz), bzip2 (.bz2) e compress (.Z).
tar [opções] [arquivo-destino] [arquivos-origem]
Onde:
arquivo-destino
É o nome do arquivo de destino. Normalmente especificado com a extensão .tar caso seja usado somente o arquivamento ou .tar.gz/.tgz caso seja usada a compactação (usando a opção -z).
arquivos-origem
Especifica quais arquivos/diretórios serão compactados.
opções
-c, --create
Cria um novo arquivo .tar
-t, --list
Lista o conteúdo de um arquivo .tar
-u, --update
Atualiza arquivos compactados no arquivo .tar
-f, --file [HOST
]F
Usa o arquivo especificado para gravação ou o dispositivo /dev/rmt0.
-j, --bzip2
Usa o programa bzip2 para processar os arquivos do tar
-l, --one-file-system
Não processa arquivos em um sistema de arquivos diferentes de onde o tar foi executado.
-M, --multi-volume
Cria/lista/descompacta arquivos em múltiplos volumes. O uso de arquivos em múltiplos volumes permite que uma grande cópia de arquivos que não cabe em um disquete, por exemplo, seja feita em mais de um disquete.
-o
Grava o arquivo no formato VT7 ao invés do ANSI.
-O, --to-stdout
Descompacta arquivos para a saída padrão ao invés de gravar em um arquivo.
--remove-files
Apaga os arquivos de origem após serem processados pelo tar.
-R, --record-number
Mostra o número de registros dentro de um arquivo tar em cada mensagem.
--totals
Mostra o total de bytes gravados com a opção --create.
-v
Mostra os nomes dos arquivos enquanto são processados.
-V [NOME]
Inclui um [NOME] no arquivo tar.
-W, --verify
Tenta verificar o arquivo gerado pelo tar após grava-lo.
x
Extrai arquivos gerados pelo tar
-X [ARQUIVO]
Tenta apagar o [ARQUIVO] dentro de um arquivo compactado .tar.
-Z
Usa o programa compress durante o processamento dos arquivos.
-z
Usa o programa gzip durante o processamento dos arquivos.
--use-compress-program [PROGRAMA]
Usa o [PROGRAMA] durante o processamento dos arquivos. Ele deve aceitar a opção -d.
-[0-7][lmh]
Especifica a unidade e sua densidade.
A extensão precisa ser especificada no arquivo de destino para a identificação correta:
Arquivos gerados pelo tar precisam ter a extensão .tar
Caso seja usada a opção -j para compactação, a extensão deverá ser .tar.bz2
Caso seja usada a opção -z para compactação, a extensão deverá ser .tar.gz ou .tgz
Caso seja usada a opção -Z para a compactação, a extensão deverá ser .tar.Z ou .tgZ
É importante saber qual qual o tipo de compactador usado durante a geração do arquivo .tar pois será necessário especificar a opção apropriada para descompacta-lo (para detalhes veja [#s-cpctd-extensoes Extensões de arquivos compactados, Seção 18.2]).
Exemplos:
tar -cf index.txt.tar index.txt - Cria um arquivo chamado index.txt.tar que armazenará o arquivo index.txt. Você pode notar digitando ls -la que o arquivo index.txt foi somente arquivado (sem compactação), isto é útil para juntar diversos arquivos em um só.
tar -xf index.txt.tar - Desarquiva o arquivo index.txt criado pelo comando acima.
tar -czf index.txt.tar.gz index.txt - O mesmo que o exemplo de arquivamento anterior, só que agora é usado a opção -z (compactação através do programa gzip). Você agora pode notar digitando ls -la que o arquivo index.txt foi compactado e depois arquivado no arquivo index.txt.tar.gz (você também pode chama-lo de index.txt.tgz que também identifica um arquivo .tar compactado pelo gzip)
tar -xzf index.txt.tar.gz - Descompacta e desarquiva o arquivo index.txt.tar.gz criado com o comando acima.
gzip -dc index.tar.gz | tar -xf - - Faz o mesmo que o comando acima só que de uma forma diferente: Primeiro descompacta o arquivo index.txt.tar.gz e envia a saída do arquivo descompactado para o tar que desarquivará o arquivo index.txt.
tar -cjf index.txt.tar.bz2 index.txt - Arquiva o arquivo index.txt em index.txt.tar.bz2 compactando através do bzip2 (opção -j).
tar -xjf index.txt.tar.bz2 - Descompacta e desarquiva o arquivo index.txt.tar.bz2 criado com o comando acima.
bzip2 -dc index.txt.tar.bz2 | tar -xf - - Faz o mesmo que o comando acima só que de uma forma diferente: Primeiro descompacta o arquivo index.txt.tar.bz2 e envia a saída do arquivo descompactado para o tar que desarquivará o arquivo index.txt.
tar -t index.txt.tar - Lista o conteúdo de um arquivo .tar.
tar -tz index.txt.tar.gz - Lista o conteúdo de um arquivo .tar.gz.
É um novo compactador que vem sendo cada vez mais usado porque consegue atingir a melhor compactação em arquivos texto se comparado aos já existentes (em consequência sua velocidade de compactação também é menor; quase duas vezes mais lento que o gzip). Suas opções são praticamente as mesmas usadas no gzip e você também pode usa-lo da mesma forma. A extensão dos arquivos compactados pelo bzip2 é a .bz2
bzip2 [opções] [arquivos]
Onde:
arquivos
Especifica quais arquivos serão compactados pelo bzip2. Caso seja usado um -, será assumido a entrada padrão. Curingas podem ser usados para especificar vários arquivos de uma só vez (veja [ch-bas.html#s-basico-curingas Curingas, Seção 2.12]).
Opções
-d, --decompress [arquivo]
Descompacta um arquivo.
-f
Força a compactação, compactando até mesmo links.
-l [arquivo]
Lista o conteúdo de um arquivo compactado pelo bzip2.
-r
Compacta diretórios e sub-diretórios.
-c [arquivo]
Descompacta o arquivo para a saída padrão.
-t [arquivo]
Testa o arquivo compactado pelo bzip2.
-[num], --fast, --best
Ajustam a taxa de compactação/velocidade da compactação. Quanto melhor a taxa menor é a velocidade de compactação e vice versa. A opção --fast permite uma compactação rápida e tamanho do arquivo maior. A opção --best permite uma melhor compactação e uma velocidade menor.
O uso da opção -[número] permite especificar uma compactação individualmente usando números entre 1 (menor compactação) e 9 (melhor compactação). É útil para buscar um bom equilibro entre taxa de compactação/velocidade (especialmente em computadores muito lentos).
Quando um arquivo é compactado pelo bzip2, é automaticamente acrescentada a extensão .bz2 ao seu nome. As permissões de acesso dos arquivos são também armazenadas no arquivo compactado.
Exemplos:
bzip2 -9 texto.txt - Compacta o arquivo texto.txt usando a compactação máxima (compare o tamanho do arquivo compactado usando o comando ls -la).
bzip2 -d texto.txt.bz2 - Descompacta o arquivo texto.txt
bzip2 -c texto.txt.bz2 - Descompacta o arquivo texto.txt para a saída padrão (tela)
bzip2 -9 *.txt - Compacta todos os arquivos que terminam com .txt
bzip2 -t texto.txt.bz2 - Verifica o arquivo texto.txt.bz2.
rar é um compactador desenvolvido por Eugene Roshal e possui versões para GNU/Linux, DOS, Windows, OS/2 e Macintosh. Trabalha com arquivos de extensão .rar e permite armazenar arquivos compactados em vários disquetes (múltiplos volumes). Se trata de um produto comercial, mas decidi coloca-lo aqui porque possui boas versões Shareware e pode ser muito útil em algumas situações.
Arquivos que serão compactados. Podem ser usados curingas para especificar mais de um arquivo.
ações
a
Compacta arquivos
x
Descompacta arquivos
d
Apaga arquivos especificados
t
Verifica o arquivo compactado em busca de erros.
c
Inclui comentário no arquivo compactado
r
Repara um arquivo .rar danificado
l
Lista arquivos armazenados no arquivo compactado
u
Atualiza arquivos existentes no arquivo compactado.
m
Compacta e apaga os arquivos de origem (move).
e
Descompacta arquivos para o diretório atual
p
Mostra o conteúdo do arquivo na saída padrão
rr
Adiciona um registro de verificação no arquivo
s
Converte um arquivo .rar normal em arquivo auto-extráctil. Arquivos auto-extrácteis são úteis para enviar arquivos a pessoas que não tem o programa rar. Basta executar o arquivo e ele será automaticamente descompactado (usando o sistema operacional que foi criado). Note que esta opção requer que o arquivo default.sfx esteja presente no diretório home do usuário. Use o comando find para localiza-lo em seu sistema.
opções
o
Substitui arquivos já existentes sem perguntar
o-
Não substitui arquivos existentes
sfx
Cria arquivos auto-extrácteis. Arquivos auto-extrácteis são úteis para enviar arquivos a pessoas que não tem o programa rar. Basta executar o arquivo e ele será automaticamente descompactado. Note que este processo requer que o arquivo default.sfx esteja presente no diretório home do usuário. Use o comando find para localiza-lo em seu sistema.
y
Assume sim para todas as perguntas
r
Inclui sub-diretórios no arquivo compactado
x [ARQUIVO]
Processa tudo menos o [ARQUIVO]. Pode ser usados curingas
v[TAMANHO]
Cria arquivos com um limite de tamanho. Por padrão, o tamanho é especificado em bytes, mas o número pode ser seguido de k (kilobytes) ou m(megabytes).
Exemplo: rar a -v1440k ... ou rar a -v10m ...
p [SENHA]
Inclui senha no arquivo. CUIDADO, pessoas conectadas em seu sistema podem capturar a linha de comando facilmente e descobrir sua senha.
m [0-5]
Ajusta a taxa de compactação/velocidade de compactação. 0 não faz compactação alguma (mais rápido) somente armazena os arquivos, 5 é o nível que usa mais compactação (mais lento).
ed
Não inclui diretórios vazios no arquivo
isnd
Ativa emissão de sons de alerta pelo programa
ierr
Envia mensagens de erro para stderr
inul
Desativa todas as mensagens
ow
Salva o dono e grupo dos arquivos.
ol
Salva links simbólicos no arquivo ao invés do arquivo físico que o link faz referência.
mm[f]
Usa um método especial de compactação para arquivos multimídia (sons, vídeos, etc). Caso for usado mmf, força o uso do método multimídia mesmo que o arquivo compactado não seja deste tipo.
Os arquivos gerados pelo rar do GNU/Linux podem ser usados em outros sistemas operacionais, basta ter o rar instalado. Quando é usada a opção -v para a criação de múltiplos volumes, a numeração dos arquivos é feita na forma: arquivo.rar, arquivo.r00, arquivo.r01, etc, durante a descompactação os arquivos serão pedidos em ordem. Se você receber a mensagem cannot modify volume durante a criação de um arquivo .rar, provavelmente o arquivo já existe. Apague o arquivo existente e tente novamente.
Exemplos:
rar a texto.rar texto.txt - Compacta o arquivo texto.txt em um arquivo com o nome texto.rar
rar x texto.rar - Descompacta o arquivo texto.rar
rar a -m5 -v1400k textos.rar * - Compacta todos os arquivos do diretório atual, usando a compactação máxima no arquivo textos.rar. Note que o tamanho máximo de cada arquivo é 1440 para ser possível grava-lo em partes para disquetes.
rar x -v -y textos.rar - Restaura os arquivos em múltiplos volumes criados com o processo anterior. Todos os arquivos devem ter sido copiados dos disquetes para o diretório atual antes de prosseguir. A opção -y é útil para não precisar-mos responder yes a toda pergunta que o rar fizer.
rar t textos.rar - Verifica se o arquivo textos.rar possui erros.
rar r textos.rar - Repara um arquivo .rar danificado.
O dpkg (Debian Package) é o programa responsável pelo gerenciamento de pacotes em sistemas Debian. Sua operação é feita em modo texto e funciona através de comandos, assim caso deseje uma ferramenta mais amigável para a seleção e instalação de pacotes, prefira o dselect (que é um front-end para o dpkg) ou o apt (veja [#s-dpkg-apt apt, Seção 20.2]).
dpkg é muito usado por usuários avançados da Debian e desenvolvedores para fins de instalação, manutenção e construção de pacotes.
Pacotes Debian são programas colocados dentro de um arquivo identificados pela extensão .deb incluindo arquivos necessários para a instalação do programa, um sistemas de listagem/checagem de dependências, scripts de automatização para remoção parcial/total do pacote, listagem de arquivos, etc.
Um nome de pacote tem a forma nome-versão_revisão.deb
Use o comando: dpkg -i [NomedoPacote] (ou --install) para instalar um pacote em seu sistema. Talvez ele peça que seja instalado algum pacote que depende para seu funcionamento. Para detalhes sobre dependências veja [#s-dpkg-dependencias Dependências, Seção 20.1.3]. É preciso especificar o nome completo do pacote (com a versão e revisão).
Dependências são pacotes requeridos para a instalação de outro pacote. Na Debian cada pacote contém um programa com uma certa função. Por exemplo, se você tentar instalar o pacote de edição de textos supertext que usa o programa sed, você precisará verificar se o pacote sed está instalado em seu sistema antes de tentar instalar o supertext, caso contrário, o pacote supertext pedirá o sed e não funcionará corretamente. Note que o pacote supertext é apenas um exemplo e não existe (pelo menos até agora :-). O programa dselect faz o trabalho de checagem de dependências automaticamente durante a instalação dos pacotes.
A colocação de cada programa em seu próprio pacote parece ser uma dificuldade a mais para a instalação manual de um certo programa. Mas para os desenvolvedores que mantém os mais de 18730 pacotes existentes na distribuição Debian, é um ponto fundamental, porque não é preciso esperar uma nova versão do supertext ser lançada para instalar a versão mais nova do pacote sed. Por este motivo também é uma vantagem para o usuário.
Use o comando: dpkg -l [pacote] (--list) para isto.
Na listagem de pacotes também será mostrado o "status" de cada um na coluna da esquerda, acompanhado do nome do pacote, versão e descrição básica. Caso o nome do [pacote] seja omitido, todos os pacotes serão listados.
É recomendado usar "dpkg -l|less" para ter um melhor controle da listagem (pode ser longa dependendo da quantidade de programas instalados).
Use o comando: dpkg -r NomedoPacote (--remove) para remover um pacote do sistema completamente. Somente é necessário digitar o nome e versão do pacote que deseja remover, não sendo necessário a revisão do pacote.
O comando dpkg -r não remove os arquivos de configuração criados pelo programa. Para uma remoção completa do programa veja [#s-dpkg-purge Removendo completamente um pacote, Seção 20.1.6].
Use o comando: dpkg -P [NomedoPacote|-a] (--purge) para remover um pacote e todos os diretórios e arquivos de configuração criados. Não é necessário especificar a revisão do pacote. O comando dpkg --purge pode ser usado após uma remoção normal do pacote (usando dpkg -r).
Caso você usar diretamente o comando dpkg --purge, dpkg primeiro removerá o pacote normalmente (como explicado em [#s-dpkg-r Removendo pacotes do sistema, Seção 20.1.5]) e após removido apagará todos os arquivos de configuração.
Caso especifique a opção -a (ou sua equivalente --pending) no lugar do nome do pacote, todos os pacotes marcados para remoção serão removidos completamente do sistema.
Note que o dpkg --purge somente remove arquivos de configuração conhecidos pelo pacote. Em especial, os arquivos de configuração criados para cada usuário do sistema devem ser removidos manualmente. Seria pedir demais que o dpkg também conhecesse os usuários de nosso sistema ;-).
Use o comando: dpkg -I NomedoPacote (--info) para mostrar a descrição do pacote. Entre a descrição são mostradas as dependências do pacote, pacotes sugeridos, recomendados, descrição do que o pacote faz, tamanho e número de arquivos que contém.
Use o comando: dpkg -s pacote (--status) para verificar o status de um pacote em seu sistema, se esta ou não instalado, configurado, tamanho, dependências, maintainer, etc.
Se o pacote estiver instalado no sistema, o resultado será parecido com o do comando dpkg -c [pacote] (--contents).
para obter uma lista de seleção dos pacotes em seu sistema. A listagem é mostrada na saída padrão, que pode ser facilmente redirecionada para um arquivo usando dpkg --get-selections >dpkg.lista.
A listagem obtida com este comando é muito útil para repetir os pacotes usados no sistema usando o dpkg --set-selections.
Obtendo uma lista de pacotes para instalar no sistema
para obter a lista de pacotes que serão instalados no sistema. O uso do dpkg --get-selections e dpkg --set-selections é muito útil durante uma necessidade de reinstalação do sistema GNU/Linux ou repetir a instalação em várias máquinas sem precisar selecionar algumas dezenas entre os milhares de pacotes no dselect.
Após obter a lista com dpkg --get-selections, use dpkg --set-selections <arquivo e então entre no dselect e escolha a opção INSTALL, todos os pacotes obtidos via dpkg --set-selections serão automaticamente instalados.
Pacotes estão desconfigurados quando, por algum motivo, a instalação do mesmo não foi concluída com sucesso. Pode ter faltado alguma dependência, acontecido algum erro de leitura do arquivo de pacote, etc. Quando um erro deste tipo acontece, os arquivos necessários pelo pacote podem ter sido instalados, mas os scripts de configuração pós-instalação não são executados.
Use o comando:
dpkg --configure [NomedoPacote]
Para configurar um pacote. O NomedoPacote não precisa conter a revisão do pacote e extensão.
Use o comando: dpkg -c arquivo (--contents) para obter a listagem dos arquivos contidos no pacote. É necessário digitar o nome completo do pacote. O comando dpkg -c é útil para listarmos arquivos de pacotes que não estão instalados no sistema.
Para obter a listagem de arquivos de pacotes já instalados no sistema, use o comando: dpkg -L arquivo. É necessário digitar somente o nome do pacote (sem a revisão e extensão).
O apt é sistema de gerenciamento de pacotes de programas que possui resolução automática de dependências entre pacotes, método fácil de instalação de pacotes, facilidade de operação, permite atualizar facilmente sua distribuição, etc. Ele funciona através de linha de comando sendo bastante fácil de usar. Mesmo assim, existem interfaces gráficas para o apt como o synaptic (modo gráfico) e o aptitude (modo texto) que permitem poderosas manipulações de pacotes sugeridos, etc.
O apt pode utilizar tanto com arquivos locais como remotos na instalação ou atualização, desta maneira é possível atualizar toda a sua distribuição Debian via ftp ou http com apenas 2 simples comandos!
É recomendável o uso do método apt no programa dselect pois ele permite a ordem correta de instalação de pacotes e checagem e resolução de dependências, etc. Devido a sua facilidade de operação, o apt é o método preferido para os usuários manipularem pacotes da Debian.
O apt é exclusivo da distribuição Debian e distribuições baseadas nela e tem por objetivo tornar a manipulação de pacotes poderosa por qualquer pessoa e tem dezenas de opções que podem ser usadas em sua execução ou configuradas no arquivo /etc/apt/apt.conf. Explicarei aqui como fazer as ações básicas com o apt, portanto se desejar maiores detalhes sobre suas opções, veja a página de manual apt-get.
Este arquivo contém os locais onde o apt encontrará os pacotes, a distribuição que será verificada (stable, testing, unstable, Woody, Sarge) e a seção que será copiada (main, non-free, contrib, non-US).
Woody(Debian 3.0) e Sarge(Debian 3.1) são os nomes das versões enquanto stable e unstable são links para as versões estável e testing respectivamente. Se desejar usar sempre uma distribuição estável (como a Woody), modifique o arquivo sources.list e coloque Woody como distribuição. Caso você desejar estar sempre atualizado mas é uma pessoa cuidadosa e deseja ter sempre a última distribuição estável da Debian, coloque stable como versão. Assim que a nova versão for lançada, os links que apontam de stable para Woody serão alterados apontando para Sarge e você terá seu sistema atualizado.
Abaixo um exemplo simples de arquivo /etc/apt/sources.list com explicação das seções:
Você pode interpretar cada parte da seguinte maneira:
deb - Identifica um pacote da Debian. A palavra deb-src identifica o código fonte.
http://www.debian.org/debian - Método de acesso aos arquivos da Debian, site e diretório principal. O caminho pode ser http://, ftp://, file:/.
stable - Local onde serão procurados arquivos para atualização. Você pode tanto usar o nome de sua distribuição (Woody, Sarge) ou sua classificação (stable, testing ou unstable. Note que unstable é recomendada somente para desenvolvedores, máquinas de testes e se você tem conhecimentos para corrigir problemas. Nunca utilize unstable em ambientes de produção ou servidores críticos, use a stable.
main contrib non-us - Seções que serão verificadas no site remoto.
Note que tudo especificado após o nome da distribuição será interpretado como sendo as seções dos arquivos (main, non-free, contrib, non-US). As linhas são processadas na ordem que estão no arquivo, então é recomendável colocar as linhas que fazem referência a pacotes locais primeiro e mirrors mais perto de você para ter um melhor aproveitamento de banda. O caminho percorrido pelo apt para chegar aos arquivos será o seguinte:
Você notou que o diretório dists foi adicionado entre http://www.debian.org/debian e stable, enquanto as seções main, non-free e contrib são processadas separadamente e finalizando com o caminho binary-[arquitetura], onde [arquitetura] pode ser i386, alpha, sparc, powerpc, arm, etc. dependendo do seu sistema. Entendendo isto, você poderá manipular o arquivo sources.list facilmente.
OBS: Caso tenha mais de uma linha em seu arquivo sources.list de onde um pacote pode ser instalado, ele será baixado da primeira encontrada no arquivo. í‹ recomendável colocar primeiro repositórios locais ou mais perto de você, como recomendado nesta seção.
Endereços de servidores e mirrors nacionais da Debian
Você pode copiar o modelo do sources.list abaixo para ser usado em sua distribuição Stable ou personaliza-lo modificando a distribuição utilizada e servidores:
Você pode especificar opções neste arquivo que modificarão o comportamento do programa apt durante a manipulação de pacotes (ao invés de especificar na linha de comando). Se estiver satisfeito com o funcionamento do programa apt, não é necessário modifica-lo. Para detalhes sobre o formato do arquivo, veja a página de manual do apt.conf. Na página de manual do apt-get são feitas referências a parâmetros que podem ser especificados neste arquivo ao invés da linha de comando.
O apt utiliza uma lista de pacotes para verificar se os pacotes existentes no sistema precisam ou não ser atualizados. A lista mais nova de pacotes é copiada através do comando apt-get update.
Este comando pode ser usado com alguma frequência se estiver usando a distribuição stable e sempre se estiver usando a unstable (os pacotes são modificados com muita frequência). Sempre utilize o apt-get update antes de atualizar toda a distribuição.
Utilizando CDs oficiais/não-oficiais/terceiros com o apt
Para usar CDs da Debian ou de programas de terceiros, use o seguinte comando com cada um dos CDs que possui:
apt-cdrom add
Este comando adicionará automaticamente uma linha para cada CD no arquivo /etc/apt/sources.list e atualizará a lista de pacotes em /var/state/apt/lists. Por padrão, a unidade acessada através de /cdrom é usada. Use a opção -d /dev/scd? para especificar um outra unidade de CDs (veja [ch-disc.html#s-disc-id Identificação de discos e partições em sistemas Linux, Seção 5.12] para detalhes sobre essa identificação).
Durante a instalação de um novo programa, o apt pede que o CD correspondente seja inserido na unidade e pressionado <Enter> para continuar. O método acesso do apt através de CDs é inteligente o bastante para instalar todos os pacotes necessários daquele CD, instalar os pacotes do próximo CD e iniciar a configuração após instalar todos os pacotes necessários.
Observação: - CDs de terceiros ou contendo programas adicionais também podem ser usados com o comando "apt-cdrom add".
Use o comando apt-get install [pacotes] para instalar novos pacotes em sua distribuição. Podem ser instalados mais de um pacotes ao mesmo tempo separando os nomes por espaços. Somente é preciso especificar o nome do pacote (sem a versão e revisão).
Se preciso, o apt instalará automaticamente as dependências necessárias para o funcionamento correto do pacote. Quando pacotes além do solicitado pelo usuário são requeridos para a instalação, o apt mostrará o espaço total que será usado no disco e perguntará ao usuário se ele deseja continuar. Após a instalação, o pacote será automaticamente configurado pelo dpkg para ser executado corretamente em seu sistema.
Use o comando apt-get remove [pacotes] para remover completamente um pacote do sistema. Podem ser removidos mais de um pacote ao mesmo tempo separando os nomes dos pacotes com espaços. O apt-get remove remove completamente o pacote mas mantém os arquivos de configuração, exceto se for adicionada a opção—purge.
É preciso especificar somente o nome do pacote (sem a versão e revisão).
O apt tem uma grande característica: Atualizar toda a sua distribuição de uma forma inteligente e segura. O apt lê a listagem de pacotes disponíveis no servidor remoto, verifica quais estão instalados e suas versões, caso a versão do pacote seja mais nova que a já instalada em seu sistema, o pacote será imediatamente atualizado.
A cópia dos arquivos pelo apt pode ser feita via FTP, HTTP ou através de uma cópia local dos arquivos no disco rígido (um mirror local). Em nenhuma circunstância os pacotes existentes em seu sistema serão removidos ou sua configuração apagada durante um upgrade na distribuição.
Os arquivos de configuração em /etc que foram modificados são identificados e podem ser mantidos ou substituídos por versões existentes nos pacotes que estão sendo instalado, esta escolha é feita por você. Se estiver atualizando a Debian Potato (2.2) para Woody (3.0) (ou versão superior), execute os seguintes comandos antes de iniciar a atualização:
para retornar as variáveis de localização ao valor padrão (inglês). Isto é necessário por causa de modificações no sistema de locales, e o excesso de mensagens de erro do perl causaram alguns problemas em meus testes.
Após isto, a atualização da distribuição Debian pode ser feita através de dois simples comandos:
apt-get update #Para atualizar a lista de pacotes (obrigatório)
apt-get -f dist-upgrade #Para atualizar a distribuição
A opção -f faz com que o apt verifique e corrija automaticamente problemas de dependências entre pacotes. Recomendo executa o comando apt-get -f --dry-run dist-upgrade|less para ver o que vai acontecer sem atualizar a distribuição, se tudo ocorrer bem, retire o --dry-run e vá em frente.
A distribuição usada na atualização pode ser:
Para a mesma versão que utiliza - Para quem deseja manter os pacotes sempre atualizados entre revisões, copiar pacotes que contém correções para falhas de segurança (veja a página web em http://www.debian.org/ para acompanhar o boletim de segurança).
Para uma distribuição stable - Mesmo que o acima, mas quando uma nova distribuição for lançada, o link simbólico de stable será apontado para próxima distribuição, atualizando instantaneamente seu sistema.
Para a distribuição testing - Atualiza para a futura distribuição Debian que será lançada, é como a unstable, mas seus pacotes passam por um período de testes de 2 semanas na unstable antes de serem copiados para esta.
unstable - Versão em desenvolvimento, recomendada somente para desenvolvedores ou usuários que conhecem a fundo o sistema GNU/Linux e saibam resolver eventuais problemas que apareçam.
A unstable é uma distribuição em constante desenvolvimento e pode haver pacotes problemáticos ou com falhas de segurança. Após o período de desenvolvimento, a distribuição unstable se tornará frozen.
frozen - Versão congelada, nenhum pacote novo é aceito e somente são feitas correções de falhas. Após todas as falhas estarem corrigidas, a distribuição frozen se tornará stable
A distribuição que será usada na atualização pode ser especificada no arquivo /etc/apt/sources.list (veja a seção correspondente acima). Caso o método de atualização usado seja via HTTP ou FTP, será necessário usar o comando apt-get clean para remover os pacotes copiados para seu sistema (para detalhes veja a seção seguinte).
Use o comando apt-get clean para apagar qualquer arquivo baixado durante uma atualização ou instalação de arquivos com o apt. Os arquivos baixados residem em /var/cache/apt/archives (download completo) e /var/cache/apt/archives/partial (arquivos sendo baixados - parciais).
Este local de armazenamento é especialmente usado com o método http e ftp para armazenamento de arquivos durante o download para instalação (todos os arquivos são primeiro copiados para serem instalados e configurados).
O apt-get clean é automaticamente executado caso seja usado o método de acesso apt do dselect.
O utilitário apt-cache pode ser usado para esta função. Ele também possui outras utilidades interessante para a procura e manipulação da lista de pacotes.
Por exemplo, o comando apt-cache search clock mostrará todos os pacotes que possuem a palavra clock na descrição do pacote.
Procurando um pacote que contém determinado arquivo
Suponha que algum programa esteja lhe pedindo o arquivo perlcc e você não tem a mínima idéia de que pacote instalar no seu sistema. O utilitário auto-apt pode resolver esta situação. Primeiro instale o pacote auto-apt e execute o comando auto-apt update para que ele copie o arquivo Contents-i386.gz que será usado na busca desses dados.
Agora, basta executar o comando:
auto-apt search perlcc
para que ele retorne o resultado:
usr/bin/perlcc interpreters/perl
O pacote que contém este arquivo é o perl e se encontra na seção interpreters dos arquivos da Debian. Para uma pesquisa que mostra mais resultados (como auto-apt search a2ps), é interessante usar o grep para filtrar a saída:
O Debian como qualquer distribuição de Linux, possui o diretório /usr/local que segundo a FHS é o local apropriado para colocação de programas que não fazem parte da distribuição, que seria no caso o de fontes compilados manualmente. Um dos grandes trabalhos de quem pega o código fonte para compilação é a instalação de bibliotecas de desenvolvimento para a compilação ocorrer com sucesso.
O auto-apt facilita magicamente o processo de compilação da seguinte forma: durante o passo ./configure no momento que é pedida uma bibliotecas, dependência, etc. o auto-apt para o processo, busca por pacotes no repositório da Debian, pergunta qual pacote será instalado (caso tenha mais de uma opção), instala e retorna o ./configure do ponto onde havia parado.
Use o comando apt-get check para verificar arquivos corrompidos. A correção é feita automaticamente. A lista de pacotes também é atualizada quando utiliza este comando.
Corrigindo problemas de dependências e outros erros
Use o comando apt-get -f install (sem o nome do pacote) para que o apt-get verifique e corrija problemas com dependências de pacotes e outros problemas conhecidos.
É um método simples e prático que permite a especificação de opções de configuração de programas sem precisar mexer com arquivos no disco ou opções. Algumas variáveis do GNU/Linux afetam o comportamento de todo o Sistema Operacional, como o idioma utilizado e o path (veja [ch-run.html#s-run-path path, Seção 7.2]) . Variáveis de ambientes são nomes que contém algum valor e tem a forma Nome=Valor. As variáveis de ambiente são individuais para cada usuário do sistema ou consoles virtuais e permanecem residentes na memória RAM até que o usuário saia do sistema (logo-off) ou até que o sistema seja desligado.
As variáveis de ambiente são visualizadas/criadas através do comando set ou echo $NOME (apenas visualiza) e exportadas para o sistemas com o comando export NOME=VALOR.
Nos sistemas Debian, o local usado para especificar variáveis de ambiente é o /etc/environment (veja [#s-pers-environment Arquivo /etc/environment, Seção 21.8]). Todas as variáveis especificadas neste arquivos serão inicializadas e automaticamente exportadas na inicialização do sistema.
Exemplo: Para criar uma variável chamada TESTE que contenha o valor 123456 digite: export TESTE=123456. Agora para ver o resultado digite: echo $TESTE ou set|grep TESTE. Note que o $ que antecede o nome TESTE serve para identificar que se trata de uma variável e não de um arquivo comum.
não acontecer o que seria esperado (a criação do arquivo teste2.txt com a string "Teste 2"). O motivo é que, ao definir n=1, temos que n é uma variável string, então $n+1 simplesmente pega a string e acrescenta +1, formando a string "1+1".
Para fazer aritmética com números inteiros, é preciso definir n como um inteiro, por exemplo, usando-se typeset.
O idioma usado em seu sistema pode ser modificado facilmente através das variáveis de ambiente. Atualmente a maioria dos programas estão sendo localizados. A localização é um recurso que especifica arquivos que contém as mensagens do programas em outros idiomas. Você pode usar o comando locale para listar as variáveis de localização do sistema e seus respectivos valores. As principais variáveis usadas para determinar qual idioma os programas localizados utilizarão são:
LANG - Especifica o idioma_PAIS local. Podem ser especificados mais de um idioma na mesma variável separando-os com :, desta forma caso o primeiro não esteja disponível para o programa o segundo será verificado e assim por diante. A língua Inglesa é identificada pelo código C e usada como padrão caso nenhum locale seja especificado.
Por exemplo: export LANG=pt_BR, export LANG=pt_BR:pt_PT:C
LC_MESSAGES - Especifica o idioma que serão mostradas as mensagens dos programas. Seu formato é o mesmo de LANG.
LC_ALL - Configura todas as variáveis de localização de uma só vez. Seu formato é o mesmo de LANG.
As mensagens de localização estão localizadas em arquivos individuais de cada programa em /usr/share/locale/[Idioma]/LC_MESSAGES . Elas são geradas através de arquivos potfiles (arquivos com a extensão .po ou .pot e são gerados catálogos de mensagens .mo. As variáveis de ambiente podem ser especificadas no arquivo /etc/environment desta forma as variáveis serão carregadas toda a vez que seu sistema for iniciado. Você também pode especificar as variáveis de localização em seu arquivos de inicialização .bash_profile, .bashrc ou .profile assim toda a vez que entrar no sistema, as variáveis de localização personalizadas serão carregadas.
Siga as instruções a seguir de acordo com a versão de sua distribuição Debian:
Debian 4.0
Acrescente a linha pt_BR ISO-8859-1 no arquivo /etc/locale.gen, rode o utilitário locale-gen para gerar os locales. Agora acrescente as variáveis de localização no arquivo /etc/locale.def seguindo a forma:
Note que o arquivo /etc/environment também pode ser usado para tal tarefa, mas o locales.def foi criado especialmente para lidar com variáveis de localização na Debian 4.0.
Para as mensagens e programas do X-Window usarem em seu idioma local, é preciso colocar as variáveis no arquivo ~/.xserverrc do diretório home de cada usuário e dar a permissão de execução neste arquivo (chmod 755 .xserverrc). Lembre-se de incluir o caminho completo do arquivo executável do seu gerenciador de janelas na última linha deste arquivo (sem o & no final), caso contrário o Xserver será finalizado logo após ler este arquivo.
Abaixo exemplos de localização com as explicações:
export LANG=pt_BR - Usa o idioma pt_BR como língua padrão do sistema. Caso o idioma Portugues do Brasil não esteja disponível, C é usado (Inglês).
export LANG=C - Usa o idioma Inglês como padrão (é a mesma coisa de não especificar LANG, pois o idioma Inglês é usado como padrão).
export LANG=pt_BR:pt_PT:es_ES:C - Usa o idioma Português do Brasil como padrão, caso não esteja disponível usa o Português de Portugal, se não estiver disponível usa o Espanhol e por fim o Inglês.
LANG=es_ES ls—help - Executa apenas o comando ls—help usando o idioma es_ES (sem alterar o locale do sistema).
É recomendável usar a variável LC_ALL para especificar o idioma, desta forma todos os outras variáveis (LANG, MESSAGES, LC_MONETARY, LC_NUMERIC, LC_COLLATE, LC_CTYPE e LC_TIME) serão configuradas automaticamente.
Permite criar um apelido a um comando ou programa. Por exemplo, se você gosta de digitar (como eu) o comando ls—color=auto para ver uma listagem longa e colorida, você pode usar o comando alias para facilitar as coisas digitando: alias ls='ls—color=auto' (não se esqueça da meia aspa 'para identificar o comando'). Agora quando você digitar ls, a listagem será mostrada com cores.
Se você digitar ls -la, a opção -la será adicionada no final da linha de comando do alias: ls—color=auto -la, e a listagem também será mostrada em cores.
Se quiser utilizar isto toda vez que entrar no sistema, veja [#s-pers-bashprofile Arquivo .bash_profile, Seção 21.5] e [#s-pers-bashrc Arquivo .bashrc, Seção 21.6].
Este arquivo contém comandos que são executados para todos os usuários do sistema no momento do login. Somente o usuário root pode ter permissão para modificar este arquivo.
Este arquivo é lido antes do arquivo de configuração pessoal de cada usuário (.profile(root) e .bash_profile).
Quando é carregado através de um shell que requer login (nome e senha), o bash procura estes arquivos em sequência e executa os comandos contidos, caso existam:
/etc/profile
~/.bash_profile
~/.bash_login
~/.profile
Ele interrompe a pesquisa assim que localiza o primeiro arquivo no diretório do usuário (usando a sequência acima). Por exemplo, se você tem o arquivo ~/.bash_login e ~/.bash_profile em seu diretório de usuário, ele processará o /etc/profile e após isto o ~/.bash_profile, mas nunca processará o ~/.bash_login (a menos que o ~/.bash_profile seja apagado ou renomeado).
Caso o bash seja carregado através de um shell que não requer login (um terminal no X, por exemplo), o seguinte arquivo é executado: ~/.bashrc.
Observação: Nos sistemas Debian, o profile do usuário root está configurado no arquivo /root/.profile. A razão disto é porque se o bash for carregado através do comando sh, ele fará a inicialização clássica deste shell lendo primeiro o arquivo /etc/profile e após o ~/.profile e ignorando o .bash_profile e .bashrc que são arquivos de configuração usados somente pelo Bash. Exemplo, inserindo a linha mesg y no arquivo /etc/profile permite que todos os usuários do sistema recebam pedidos de talk de outros usuários. Caso um usuário não quiser receber pedidos de talk, basta somente adicionar a linha mesg n no arquivo pessoal .bash_profile.
Este arquivo reside no diretório pessoal de cada usuário. É executado por shells que usam autenticação (nome e senha). .bash_profile contém comandos que são executados para o usuário no momento do login no sistema após o /etc/profile. Note que este é um arquivo oculto pois tem um "." no inicio do nome.
Por exemplo colocando a linha: alias ls='ls—colors=auto' no .bash_profile, cria um apelido para o comando ls --colors=auto usando ls, assim toda vez que você digitar ls será mostrada a listagem colorida.
Possui as mesmas características do .bash_profile mas é executado por shells que não requerem autenticação (como uma seção de terminal no X).
Os comandos deste arquivo são executados no momento que o usuário inicia um shell com as características acima. Note que este é um arquivo oculto pois tem um "." no inicio do nome.
Deve ser colocado no diretório pessoal do usuário. Este arquivo faz o bash pular as mensagens do /etc/motd, número de e-mails, etc. Exibindo imediatamente o aviso de comando após a digitação da senha.
Armazena as variáveis de ambiente que são exportadas para todo o sistema. Uma variável de ambiente controla o comportamento de um programa, registram detalhes úteis durante a seção do usuário no sistema, especificam o idioma das mensagens do sistema, etc.
Exemplo do conteúdo de um arquivo /etc/environment:
Este diretório contém os modelos de arquivos .bash_profile e .bashrc que serão copiados para o diretório pessoal dos usuários no momento que for criada uma conta no sistema. Desta forma você não precisará configurar estes arquivos separadamente para cada usuário.
Uma porta de impressora é o local do sistema usado para se comunicar com a impressora. Em sistemas GNU/Linux, a porta de impressora é identificada como lp0, lp1, lp2 no diretório /dev, correspondendo respectivamente a LPT1, LPT2 e LPT3 no DOS e Windows. Recomendo que o suporte a porta paralela esteja compilado como módulo no kernel.
Isto é feito direcionando a saída ou o texto com > diretamente para a porta de impressora no diretório /dev.
Supondo que você quer imprimir o texto contido do arquivo trabalho.txt e a porta de impressora em seu sistema é /dev/lp0, você pode usar os seguintes comandos:
cat trabalho.txt >/dev/lp0 - Direciona a saída do comando cat para a impressora.
cat <trabalho.txt >/dev/lp0. Faz a mesma coisa que o acima.
cat -n trabalho.txt >/dev/lp0 - Numera as linhas durante a impressão.
head -n 30 trabalho.txt >/dev/lp0 - Imprime as 30 linhas iniciais do arquivo.
cat trabalho.txt|tee /dev/lp0 - Mostra o conteúdo do cat na tela e envia também para a impressora.
Os métodos acima servem somente para imprimir em modo texto (letras, números e caracteres semi-gráficos).
A impressão via spool tem por objetivo liberar logo o programa do serviço de impressão deixando um outro programa especifico tomar conta. Este programa é chamado de daemon de impressão, normalmente é o lpr ou o lprng (recomendado) em sistemas GNU/Linux.
Logo após receber o arquivo que será impresso, o programa de spool gera um arquivo temporário (normalmente localizado em /var/spool/lpd) que será colocado em fila para a impressão (um trabalho será impresso após o outro, em sequência). O arquivo temporário gerado pelo programa de spool é apagado logo após concluir a impressão.
Antes de se imprimir qualquer coisa usando os daemons de impressão, é preciso configurar os parâmetros de sua impressora no arquivo /etc/printcap. Um arquivo /etc/printcap para uma impressora local padrão se parece com o seguinte:
lp|Impressora compatível com Linux
:lp=/dev/lp0
:sd=/var/spool/lpd/lp
:af=/var/log/lp-acct
:lf=/var/log/lp-errs
:pl#66
:pw#80
:pc#150
:mx#0
:sh
É possível também compartilhar a impressora para a impressão em sistemas remotos, isto será visto em uma seção separada neste guia.
Usando os exemplos anteriores da seção Imprimindo diretamente para uma porta de impressora, vamos acelerar as coisas:
cat trabalho.txt |lpr - Direciona a saída do comando cat para o programa de spool lpr.
cat <trabalho.txt |lpr. Faz a mesma coisa que o acima.
cat -n trabalho.txt |lpr - Numera as linhas durante a impressão.
head -n 30 trabalho.txt |lpr - Imprime as 30 linhas iniciais do arquivo.
A fila de impressão pode ser controlada com os comandos:
lpq - Mostra os trabalhos de impressão atuais
lprm - Remove um trabalho de impressão
Ou usado o programa de administração lpc para gerenciar a fila de impressão (veja a página de manual do lpc ou digite ? ao iniciar o programa para detalhes).
OBS1: Se a impressora não imprimir ou não for possível compartilhar a porta de impressora paralela com outros dispositivos (tal como o plip), verifique se o módulo parport_pc foi carregado e com os valores de irq e I/O corretos (por exemplo, modprobe parport_pc io=0x378 irq=7). Muitas vezes sua porta paralela pode funcionar sem problemas durante a impressão, mas se ao utilizar plip ocorrerem erros, a causa pode ser essa. Na distribuição Debian, use o programa modconf para configurar os valores permanentemente para o módulo parport_pc.
OBS2: Se tiver mais de uma impressora instalada na máquina, será necessário especificar a opção "-P impressora" para especificar qual impressora deseja imprimir/controlar.
A impressão em modo gráfico requer que conheça a marca e modelo de sua impressora e os métodos usados para imprimir seus documentos. Este guia abordará somente a segunda recomendação :-)
O método mais usados pelos aplicativos do GNU/Linux para a impressão de gráficos do Ghost Script. O Ghost Script (chamado de gs) é um interpretador do formato Pos Script (arquivos .ps) e pode enviar o resultado de processamento tanto para a tela como impressora. Ele está disponível para diversas plataformas e sistema operacionais além do GNU/Linux, inclusive o DOS, Windows, OS/2, etc.
O formato .ps esta se tornando uma padronização para a impressão de gráficos em GNU/Linux devido a boa qualidade da impressão, liberdade de configuração, gerenciamento de impressão feito pelo gs e por ser um formato universal, compatíveis com outros sistemas operacionais.
Para imprimir um documento via Ghost Script, você precisará do pacote gs, gsfonts (para a distribuição Debian e distribuições baseadas, ou outros de acordo com sua distribuição Linux) e suas dependências. A distribuição Debian vem com vários exemplos Pos Script no diretório /usr/share/doc/gs/example que são úteis para o aprendizado e testes com o Ghost Script.
Hora da diversão:
Copie os arquivos tiger.ps.gz e alphabet.ps.gz do diretório /usr/share/doc/gs/examples (sistemas Debian) para /tmp e descompacte-os com o comando gzip -d tiger.ps.gz e gzip -d alphabet.ps.gz. Se a sua distribuição não possui arquivos de exemplo ou você não encontra nenhuma referência de onde se localizam, mande um e-mail que os envio os 2 arquivos acima (são 32Kb).
O Ghost Script requer um monitor EGA, VGA ou superior para a visualização dos seus arquivos (não tenho certeza se ele funciona com monitores CGA ou Hércules Monocromático) .
Para visualizar os arquivos na tela digite:
gs tiger.ps
gs alphabet.ps
Para sair do Ghost Script pressione CTRL C. Neste ponto você deve ter visto um desenho de um tigre e (talvez) letras do alfabeto.
Se o comando gs alphabet.ps mostrou somente uma tela em branco, você se esqueceu de instalar as fontes do Ghost Script (estão localizadas no pacote gsfonts na distribuição Debian).
Para imprimir o arquivo alphabet.ps use o comando:
O arquivo alphabet.ps deve ser impresso. Caso aparecerem mensagens como Error: /invalidfont in findfont no lugar das letras, você se esqueceu de instalar ou configurar as fontes do Ghost Script. Instale o pacote de fontes (gsfonts na Debian) ou verifique a documentação sobre como configurar as fontes.
Cada uma das opções acima descrevem o seguinte:
-q, -dQUIET - Não mostra mensagens de inicialização do Ghost Script.
-dSAFER - É uma opção para ambientes seguros, pois desativa a operação de mudança de nome e deleção de arquivo e permite somente a abertura dos arquivos no modo somente leitura.
-dNOPAUSE - Desativa a pausa no final de cada página processada.
-sDEVICE=dispositivo - Dispositivo que receberá a saída do Ghost Script. Neste local pode ser especificada a marca o modelo de sua impressora ou um formato de arquivo diferente (como pcxmono, bmp256) para que o arquivo .ps seja convertido para o formato designado.
Para detalhes sobre os dispositivos disponíveis em seu Ghost Script, digite gs—help|less ou veja a página de manual. Normalmente os nomes de impressoras e modelos são concatenados, por exemplo, bjc600 para a impressora Canon BJC 600, epson para impressoras padrão epson, stcolor para Epson Stylus color, etc.
O Hardware-HOWTO contém referências sobre hardware suportados pelo GNU/Linux, tal como impressoras e sua leitura pode ser útil.
-r<ResH>x<ResV> - Define a resolução de impressão (em dpi) Horizontal e Vertical. Os valores dependem de sua impressora.
-sPAPERSIZE=tamanho - Tamanho do papel. Podem ser usados a4, legal, letter, etc. Veja a página de manual do gs para ver os outros tipos suportados e suas medidas.
-sOutputFile=dispositivo - Dispositivo que receberá a saída de processamento do gs. Você pode especificar
arquivo.epson - Nome do arquivo que receberá todo o resultado do processamento. O arquivo.epson terá toda a impressão codificada no formato entendido por impressoras epson e poderá ser impresso com o comando cat arquivo.epson >/dev/lp0.
Uma curiosidade útil: É possível imprimir este arquivo em outros sistemas operacionais, tal como o DOS digitando: copy /b arquivo.eps prn (lembre-se que o DOS tem um limite de 8 letras no nome do arquivo e 3 na extensão. Você deve estar compreendendo a flexibilidade que o GNU/Linux e suas ferramentas permitem, isso é só o começo.
impressao%d.epson - Nome do arquivo que receberá o resultado do processamento. Cada página será gravada em arquivos separados como impressao1.epson, impressao2.epson.
Os arquivos podem ser impressos usando os mesmos métodos acima.
/dev/lp0 para uma impressora em /dev/lp0
- para redirecionar a saída de processamento do gs para a saída padrão. É útil para usar o gs com pipes |.
\|lpr - Envia a saída do Ghost Script para o daemon de impressão. O objetivo é deixar a impressão mais rápida.
Se você é curioso ou não esta satisfeito com as opções mostradas acima, veja a página de manual do gs.
O Magic Filter é um filtro de impressão inteligente. Ele funciona acionado pelo spool de impressão (mais especificamente o arquivo /etc/printcap) e permite identificar e imprimir arquivos de diversos tipos diretamente através do comando lpr arquivo.
É um ótimo programa e ALTAMENTE RECOMENDADO se você deseja apenas clicar no botão imprimir e deixar os programas fazerem o resto :-) A intenção do programa é justamente automatizar os trabalhos de impressão e spool.
A maioria dos programas para ambiente gráfico X11, incluindo o Netscape, Word Perfect, Gimp e Star Office trabalham nativamente com o magicfilter.
O Magic Filter é encontrado no pacote magicfilter da distribuição Debian e baseadas.
Sua configuração pode ser feita com o programa magicfilterconfig que torna o processo de configuração rápido e fácil para quem não conhece a sintaxe do arquivo /etc/printcap ou não tem muitas exigências sobre a configuração detalhada da impressora.
Após instalar o magicfilter reinicie o daemon de impressão (se estiver usando a Debian, entre no diretório /etc/init.d e como usuário root digite ./lpr restart ou ./lprng restart).
Para testar o funcionamento do magicfilter, digite lpr alphabet.ps e lpr tiger.ps, os arquivos serão enviados para o magicfilter que identificará o arquivo como Pos Script, executará o Ghost Script e retornará o resultado do processamento para o daemon de impressão. O resultado será visto na impressora.
Se tiver problemas, verifique se a configuração feita com o magicfilterconfig está correta. Caso precise re-configurar o magicfilter, digite magicfilterconfig—force (lembre-se que a opção—force substitui qualquer configuração personalizada que tenha adicionado ao arquivo /etc/printcap).
Durante a configuração do magicfilter, a seguinte linha é adicionada ao arquivo /etc/printcap:
:if=/etc/magicfilter/epson9-filter
Não tenho nenhum contrato de divulgação com a epson :-) estou usando esta marca de impressora porque é a mais tradicional e facilmente encontrada. A linha que começa com :if no magicfilter identifica um arquivo de filtro de impressão.
O arquivo /etc/magicfilter/epson9-filter é criado usando o formato do magicfilter, e não é difícil entender seu conteúdo e fazer algumas modificações:
#! /usr/sbin/magicfilter
#
# Magic filter setup file for 9-pin Epson (or compatible) printers
#
# This file is in the public domain.
#
# This file has been automatically adapted to your system.
#
# wild guess: native control codes start with ESC
0 \033 cat
# PostScript
0 %! filter /usr/bin/gs -q -dSAFER -dNOPAUSE -r120x72 -sDEVICE=epson -sOutputFile=- - -c quit
0 \004%! filter /usr/bin/gs -q -dSAFER -dNOPAUSE -r120x72 -sDEVICE=epson -sOutputFile=- - -c quit
# PDF
0 %PDF fpipe /usr/bin/gs -q -dSAFER -dNOPAUSE -r120x72 -sDEVICE=epson -sOutputFile=- $FILE -c quit
# TeX DVI
0 \367\002 fpipe /usr/bin/dvips -X 120 -Y 72 -R -q -f
# compress'd data
0 \037\235 pipe /bin/gzip -cdq
# packed, gzipped, frozen and SCO LZH data
0 \037\036 pipe /bin/gzip -cdq
0 \037\213 pipe /bin/gzip -cdq
0 \037\236 pipe /bin/gzip -cdq
0 \037\240 pipe /bin/gzip -cdq
0 BZh pipe /usr/bin/bzip2 -cdq
# troff documents
0 .\?\?\040 fpipe `/usr/bin/grog -Tps $FILE`
0 .\\\" fpipe `/usr/bin/grog -Tps $FILE`
0 '\\\" fpipe `/usr/bin/grog -Tps $FILE`
0 '.\\\" fpipe `/usr/bin/grog -Tps $FILE`
0 \\\" fpipe `/usr/bin/grog -Tps $FILE`
Você deve ter notado que para cada tipo de arquivo existe o respectivo programa que é executado, basta você modificar as opções usadas nos programas neste arquivo (como faria na linha de comando) para afetar o comportamento da impressão.
Por exemplo, modificando a resolução para -r240x72 no processamento de arquivos Pos Script (gs), a impressora passará a usar esta resolução.
Este capítulo traz explicações sobre algumas configurações úteis que podem ser feitas no sistema. Neste documento assumimos que o kernel do seus sistema já possui suporte a página de código 860 (Portuguesa) e o conjunto de caracteres ISO-8859-1.
Permite que o GNU/Linux use a acentuação. A acentuação do modo texto é independente do modo gráfico; você pode configurar tanto um como o outro ou ambos. Para maiores detalhes veja [#s-cfg-acentuacao-t Acentuação em modo Texto, Seção 23.1.1] e/ou [#s-cfg-acentuacao-g Acentuação em modo gráfico, Seção 23.1.2].
Note que os mapas de teclado usados em modo texto são diferentes dos usados em modo gráfico. Geralmente os mapas de teclados para o modo gráfico tem uma letra X no nome.
Caso sua distribuição Debian esteja acentuando corretamente no modo texto você não precisará ler esta seção. Antes de prosseguir, verifique se você possui o pacote console-data instalado em seu sistema com o comando: dpkg -l console-data. Caso não existam, alguns programas de configuração e arquivos de fontes não estarão disponíveis.
Siga os passos abaixo para colocar e acentuação em funcionamento para o modo Texto na Debian:
Mapa de Teclados
;; Debian 4.0 (Etch)
Digite dpkg-reconfigure console-data. Após a tela inicial, selecione a opção Selecionar o mapa de teclados da lista de arquiteturas, qwerty e selecione os passos seguintes de acordo com seu tipo de teclado:
Us Internacional - Selecione US American na lista de opções e em seguida Standard e US International (ISO-8859-1).
ABNT2 (com cedilha) - Selecione Brazilian na lista de opções.
Configurando o Mapa de Teclados
Digite dpkg-reconfigure console-data. Após a tela inicial, selecione a opção Selecionar o mapa de teclados da lista de arquiteturas, qwerty e selecione os passos seguintes de acordo com o seu tipo de teclado:
US Inernacional - Selecione US American na lista de opções de layout e em seguida Standard e depois US International (ISO-8859-1).
ABNT2 (com dedilha) - Selecione Brazilian na lista de opções
Após isso, o mapa de teclados correto será carregado de /usr/share/keymaps e será ativado no sistema.
Se desejar usar o comando loadkeys manualmente , você precisa copiar o mapa de teclados para um local conhecido no sistema, então copie o arquivo arquivo.kmap para /usr/share/keymaps/i386/qwerty (em sistemas Debian) ou algum outro local apropriado. Note que o arquivo pode ser compactado pelo gzip e copiado para /usr/share/keymaps/i386/qwerty que será lido sem problemas pelo sistema encarregado de configurar o teclado e acentuação.
Configurando a fonte de Tela
Descomente a linha SCREEN_FONT=LatArCyrHeb-16 e modifique-a para CONSOLE_FONT=lat1u-16.psf no arquivo /etc/console-tools/config.
Esta linha diz ao sistema que fonte deve carregar para mostrar os caracteres na tela. A fonte de caracteres deve ser compatível com o idioma local, pois nem todas suportam caracteres acentuados. A fonte preferível para exibir os caracteres acentuados usando padrão ISO é a lat1u-16, o -16 no nome do arquivo significa o tamanho da fonte. As fontes de tela estão disponíveis no diretório /usr/share/consolefonts.
Neste ponto você pode verificar se o seu sistema esta reconhecendo corretamente a acentuação entrando no editor de textos ae e digitando: áãâí . Se todos os acentos apareceram corretamente, parabéns! você já passou pela parte mais difícil. Agora o próximo passo é a acentuação no Bash.
Acentuação no aviso de comando (bash)
Para acentuar no Bash (interpretador de comandos) é necessário alterar o arquivo /etc/inputrc e fazer as seguintes modificações:
Descomente a linha: "#set convert-meta off" você faz isto apagando o símbolo "#" antes do nome.
Um comentário faz com que o programa ignore linha(s) de comando. É muito útil para descrever o funcionamento de comandos/programas (você vai encontrar muito isso no sistema GNU/Linux, tudo é muito bem documentado).
Inclua a seguinte linha no final do arquivo:
set meta-flag on
O conteúdo deste arquivo deve ficar assim:
set convert-meta off
set input-meta on
set output-meta on
Digite exit ou pressione CTRL D para fazer o logout. Entre novamente no sistema para que as alterações façam efeito.
Pronto! você já esta acentuando em modo texto!. Talvez seja necessário que faça alguma alteração em arquivos de configuração de outros programas para que possa acentuar corretamente (veja se existe algum arquivo com o nome correspondente ao programa no diretório /etc).
A distribuição Debian também traz o utilitário kbdconfig que também faz a configuração do mapa de teclados de forma interativa e gravando automaticamente o mapa de teclados em /etc/kbd/default.map.gz. Se preferir usar o kbdconfig ainda será necessário executar os passos acima para habilitação da fonte lat1u-16 e acentuação no bash.
A acentuação no modo gráfico é feita de maneira simples:
Configuração do mapa de teclados
Execute o comando dpkg-reconfigure xserver-xorg e informe o tipo de teclado quando perguntado pelo sistema de configuração. A configuração será gravada na seção InputDevice do arquivo /etc/X11/xorg.conf e poderá ser modificada manualmente se necessário.
O número de cores do ambiente gráfico pode ser alterado facilmente. Normalmente as distribuições realizam a instalação usando o padrão VESA (que é compatível com qualquer placa de vídeo) usando 65.000 cores (16 bits), mas por usar VESA são deixados de lado recursos como aceleração de hardware, XV, e recursos 3D necessário pela maioria dos jogos e aplicativos de vídeo atuais.
A configuração apropriada do driver exige que você execute novamente o procedimento de configuração da distribuição usando o comando dpkg-reconfigure xserver-xorg.
Por exemplo, para configurar minha placa de vídeo Intel 810, é necessário selecionar o driver i810 na tela de seleção do driver de video do dpkg-reconfigure xserver-xorg. O programa xresprobe pode ser útil caso deseja fazer manualmente ajustes finos na configuração do /etc/X11/xorg.conf. O monitor também poderá ser configurado de acordo com o tamanho da tela (em polegadas).
Com uma configuração correta é possível atingir até 32 bits de cores (pocket pixel) no X. A configuração do X utiliza o número de bits ao invés do número de cores na sua configuração. Abaixo uma tabela comparativa:
Bits Número Max. Cores Memória mínima requerida na Placa de Vídeo
------- ----------------- -----------------------------------------
4 bits 16 cores 256Kb
8 bits 256 cores 512Kb
16 bits 32.384/65536 cores 1MB
24 bits 16 milhões de cores (pixel menor) 1MB
32 bits 16 milhões de cores 1MB
Lembre-se que a tabela acima leva em consideração a resolução de vídeo de 640x480. Caso utilizar uma resolução de 800x600, 1024x768 ou superior, os requerimentos de memória de vídeo para mostrar o número de cores da tabela acima serão maiores. Para mostrar 1024x768 - 16 milhões de cores serão necessários 2MB de memória de vídeo, por exemplo. A resolução de 24 bits normalmente traz problemas em alguns chipsets, considere a utilização da resolução de 16 ou 32 bits.
O uso de uma resolução de vídeo como 800x600 ou superior, também depende do monitor de vídeo. Nem todos os monitores VGA e SVGAs do mercado suportam resoluções acima de 640x480.
OBS: Se tiver escolha, prefira placas de vídeo independentes da placa mãe. Normalmente as placas de vídeo on-board usam parte da memória RAM como memória de vídeo (memória compartilhada) e isto diminui a performance de vídeo e a performance do sistema porque se você estiver usando 2MB de memória de vídeo, terá 2 MB a menos para executar seus programas. O preço destas placas geralmente diminui na proporção do desempenho que oferecem.
Uma boa escolha para uma melhor qualidade e maior velocidade é 16 bits. O motivo disto é que quanto maior a qualidade e a resolução, mais tempo será levado para os pixels serem atualizados no monitor. Veja abaixo como configurar o número de cores para quem esta iniciando o X-Window pelo modo texto e XDM.
Configurando o número de cores para quem inicia pelo prompt
Após configurar corretamente a resolução de vídeo aceita pelo seu servidor X com dpkg-reconfigure xserver-xorg (Debian 4.0) use o comando startx -- -bpp 8 no lugar de startx. Note que estou usando 256 cores como exemplo (veja a tabela acima), se quiser usar mais cores e sua placa de vídeo tiver memória suficiente, use 16, 24 ou 32.
Uma maneira mais prática de iniciar sempre com uma mesma resolução é incluir um alias no arquivo .bashrc em seu diretório: alias startx='startx -- -bpp 8'
Desta forma toda a vez que se digitar startx, será executado o comando da direita do sinal de igual.
OBS: Se alguma coisa der errado e a imagem aparecer distorcida ou simplesmente não aparecer, não se desespere! Pressione simultaneamente CTRL ALT Back Space, esta é a combinação de teclas finaliza imediatamente o servidor X.
Configurando o número de cores para quem inicia pelo XDM
Assumindo que o seu arquivo /etc/X11/xorg.conf foi gerado corretamente, modifique o arquivo /etc/X11/xdm/Xservers e alterar o final da linha colocando -bpp resolução. Por exemplo, a última linha de meu arquivo Xservers era:
:0 local /usr/bin/X11/X vt7
eu a modifiquei para
:0 local /usr/bin/X11/X vt7 -bpp 16
Pronto, basta reiniciar o servidor X (usando CTRL ALT Back Space) ou reiniciando através do arquivo /etc/init.d/xdm usando xdm restart e seu sistema passará a usar 65.000 cores de vídeo.
OBS: Lembre-se de salvar todos os seus arquivos antes de reiniciar o servidor X, pois todos os programas que estiverem abertos no sistema serão imediatamente fechados.
Ajustando o alinhamento da imagem no X e outras configurações
Após você ter criado o arquivo de configuração do X com o dpkg-reconfigure xserver-xorg, é possível que a configuração precise de um ajuste fino para o alinhamento correto da imagem no monitor. Muitos monitores modernos possuem teclas para esta função, mas desde que monitor esteja com sua imagem aparecendo corretamente em modo texto, o ajuste deverá ser feito no servidor X. Este ajuste é feito através do utilitário xvidtune.
Entre no modo gráfico como usuário root, abra o xterm e digite xvidtune uma tela aparecerá com um aviso sobre o uso do programa, clique em OK. Recomendo que ative o botão AUTO para que a tela vá se ajustando na medida que você mexe nos ajustes.
Para restaurar a configuração anterior, pressione o botão Restore (não faz efeito caso o botão Apply tenha sido pressionado). Clicando em Quit, você sai do xvidtune sem salvar a configuração. Quando estiver satisfeito com a sua configuração/alinhamento da imagem, clique em Apply, a configuração escolhida estará salva.
Este capítulo explica como realizar tarefas específicas no sistema, como gravar um CD, assistir filmes, etc. Ele também contém nomes de programas recomendados tanto em modo texto como modo gráfico.
A gravação de CDs no Linux pode ser feita através dos programas cdrecord ou CDRDAO e a gravação de DVDs usando o dvd rw-tools. Neste capítulo vou explicar a gravação usando o cdrecord para gravar um CD de dados e audio e o growisofs para a gravação de DVDs de dados. Primeiro instale o cdrecord, mkisofs, dvd rw-tools e cdda2wav em sua máquina (apt-get install cdrecord dvd rw-tools mkisofs cdda2wav).
O processo de gravação de um CD/DVD de dados é feito em 2 etapas: primeiro é gerado um arquivo ISO com o programa mkisofs que será a imagem exata do CD que será gravado e a gravação usando o cdrecord ou growisofs (DVD). Caso ainda não tenha configurado seu gravador no Linux ou não tem certeza do seu funcionamento, veja [ch-hardw.html#s-hardw-cfgdisp-cdwritter Configurando um gravador de CD/DVD no Linux, Seção 3.11.3].
Vou assumir que os dados que deseja gravar estão no diretório /dados. Primeiro gere o arquivo ISO:
cd /dados
mkisofs -r -o dados.iso -J -V"CD_DADOS" .
Na linha acima, você permite que todos possam ler o CD alterando as permissões (-r), o arquivo de saída será dados.iso (-o dados.iso), os nomes também terão o índice no formato Joliet (Windows) (-J), o nome de volume será CD_DADOS (-V"CD_DADOS"). Foi colocado . para o diretório raíz porque estamos dentro do diretório que queremos gravar dados. Não us e "*" para especificar os arquivos, a não ser que queira que todos os arquivos do seus subdiretórios fiquem dentro do raíz do CD :-)
Antes de gravar você pode testar se o conteúdo do CD está OK montando a imagem ISO:
mkdir /tmp/iso
mount /dados/dados.iso /tmp/iso -o loop -t iso9660
Você poderá entrar no diretório /tmp/iso e ver como está o conteúdo do seu CD antes da gravação. Qualquer modificação deverá ser feita no diretório /dados e depois gerar novamente o iso com mkisofs. Desmonte o arquivo ISO antes de gravar o CD.
Agora, para gravar um CD (750Mb) execute o comando:
cdrecord -v -dev=/dev/hdc -data /dados/dados.iso
O -v mostra a progressão da gravação. Caso seu gravador de CD esteja configurado com emulação SCSI ou SCSI, o número passado como argumento a -dev deverá ser obtido pelo comando cdrecord -scanbus (por ex. 0,0,0). A opção -data especifica o arquivo iso que contém os dados que serão gravados.
Para gravar um DVD, execute o comando:
growisofs -Z /dev/hdc=/dados/dados.iso
Após isto seu CD ou DVD estará gravado e pronto para uso.
A gravação de um CD de audio se divide em 2 etapas: Extração das trilhas de audio para um diretório em formato wav e a gravação. Após inserir o CD de audio na unidade, a extração é feita pelo programa cdda2wav da seguinte forma:
A opção -x extrai usando máxima qualidade, -D/dev/cdrom diz qual é o dispositivo onde o CD de audio está inserido, -d99999 diz a duração total da extração (99999 é um valor que garante a extração de TODO o CD), -S4 diz que a velocidade de extração será de 4X, a -B audio diz para criar arquivos contendo as faixas sequencialmente como audio01.wav, audio02.wav, etc.
Após extrair, você deverá executar o comando:
cdrecord -v -dev=/dev/hdc -dao -useinfo *.wav
O comando acima usa o dispositivo gravador /dev/hdc para fazer a gravação do CD de audio. O formato usado é o DAO (-dao), o que garante que não haverá intervalo entre as faixas de CD, útil em CDs ao vivo e que os arquivos *.inf contendo os dados das faixas serão usados para controlar a duração de cada uma (-useinfo *.wav).
Se você quer gravar uma seleção de arquivos .wav ou .cdr, será preciso faze-lo em modo TAO (track at once), mantendo a pausa de 2 segundos entre as músicas. Isto é feito pelo comando:
cdrecord -v -dev=/dev/hdc -pad -audio *.wav
Estamos dizendo para o cdrecord gravar diversos arquivos de audio (-audio *.wav) e preencher os intervalos dos arquivos de audio com zeros (-pad) pois nem sempre os arquivos tem o múltiplo de setores requeridos para a gravação de arquivos de audio.
A cópia de CD/DVD de dados para outro é feita em duas etapas: A extração do arquivo ISO e a gravação do CD. Esse recurso é útil pela economia de tempo que proporciona e porque mantém características especiais do CD como setor de boot.
Primeiro, extraia o conteúdo do CD/DVD em format raw com o comando:
dd if=/dev/cdrom of=/dados/arquivo.iso
Confira se no final o número de bytes conferem, isso diz que a extração foi feita com sucesso. O parâmetro if= indica o arquivo de entrada e of= o arquivo de saída. Depois disso grave o CD ou DVD com o comando:
(Para gravação de CD (750Mb)
cdrecord -v -dev=/dev/hdc -data /dados/dados.iso
(Para gravação de DVD)
groisofs -Z /dev/hdc=/dados/dados.iso
Veja a explicação dos parâmetros em [#s-tasks-cdwriting-data Gravando CDs / DVDs de dados, Seção 24.1.1]. Note que você também poderá gravar o CD usando o comando dd:
Isso é feito pelo programa cdcontrol que permite a gravação de CDs paralelamente, sendo bastante útil para gerar CDs para install fests, distribuições comerciais em massa. Ele mantém um relatório de CDs totais por unidade de disco e também de falhas, também permite a cópia de CDs de inicialização. Ele está disponível em http://cdcontrol.sourceforge.net/. Ele também está disponível como pacote .deb (apt-get install cdcontrol).
Gravação de CDs diretamente através de arquivos mp3 ou Ogg
Os seguintes aplicativos são interfaces gráficas e amigáveis que usam o cdrecord, cdda2wav e mkisofs para fazer a gravação de seus CDs. Normalmente eles acrescentam uma carga maior para a máquina, mas se você gosta de uma interface amigável para fazer as coisas, ter animações, etc. o preço que paga é a performance :-)
Entre os principais programas, destaco os seguintes: cdrtoaster, cdbakeoven, kreatecd, gcombust, TkDVD
O programa mais recomendado é o mplayer. Após instalar, execute o comando: mplayer -framedrop -vo xv arquivo.avi. A opção -framedrop diz ao mplayer pular frames que ele não conseguir exibir (útil em sistemas que tem CPU lenta).
O gmplayer é a interface gráfica do mplayer e aceita todos os seus parâmetros.
Para assistir filmes em DVD recomendo os seguintes programas: ogle, xine e mplayer. Lembre-se de fazer um link de /dev/dvd para seu dispositivo leitor de DVD antes de executar um destes programas.
A conversão é explicada aqui usando o programa bladeenc. Você pode baixa-lo de http://bladeenc.mp3.no/. O bladeenc foi o escolhido por apresentar a melhor performance e qualidade para conversão da músicas, que é importante para quem tem máquinas menos potentes e processamento leve é valioso para você :-)
A conversão é feita da seguinte forma:
bladeenc -progress=4 -del *.wav
A opção -del diz para apagar os arquivos .wav a medida que são convertidos e -progress=4 para mostrar uma barra de progresso total e outra do arquivo que está sendo processado.
Esta conversão necessária quando deseja gravar um CD de audio a partir de uma seleção de músicas MP3. As explicações aqui são baseadas no programa mpg123, que pode ser instalado com apt-get install mpg123. Execute o seguinte comando para fazer a conversão:
mpg123—cdr - arquivo.mp3 >arquivo.cdr
Para fazer a conversão de todos os arquivos mp3 dentro de um diretório, use o comando:
for MUSICA in *.mp3; do
mpg123—cdr - "$MUSICA" >"${VAR}.cdr"
done
Após feita a conversão de músicas necessárias para completar um CD (normalmente 600MB), vá até [#s-tasks-cdwriting-audio Gravando um CD de audio, Seção 24.1.2].
Este capítulo explica o que é compilação, os principais compiladores e como compilar programas e principalmente o Kernel do GNU/Linux com o objetivo de personaliza-lo de acordo com os dispositivos usados em seu computador e/ou os recursos que planeja utilizar.
É a transformação de um programa em código fonte (programa escrito pelo programador) em linguagem de máquina (programa executável).
Existem centenas de linguagens de programação diferentes umas das outras, cada uma oferece recursos específicos para atender melhor uma necessidade ou características particulares, algumas são voltadas para bancos de dados, outras somente para a criação de interfaces comunicação (front-ends), aprendizado, etc. Cada linguagem de programação possui comandos específicos que desempenham alguma função, mas todas trabalham com variáveis de memória para a manipulação de dados de entrada/processamento.
É o programa que converte o programa feito pelo programador em linguagem de máquina. Após o processo de compilação o programa estará pronto para ser executado como um arquivo binário.
Existem muitos compiladores no ambiente GNU/Linux, um dos mais usados é o gcc, o compilador para linguagem C.
Este capítulo descreve como fazer a manutenção de seu sistema de arquivos e os programas de manutenção automática que são executados periodicamente pelo sistema.
A checagem do sistema de arquivos permite verificar se toda a estrutura para armazenamento de arquivos, diretórios, permissões, conectividade e superfície do disco estão funcionando corretamente. Caso algum problema exista, ele poderá ser corrigido com o uso da ferramenta de checagem apropriada. As ferramentas de checagem de sistemas de arquivos costumam ter seu nome iniciado por fsck e terminados com o nome do sistema de arquivos que verifica, separados por um ponto:
fsck.ext2 - Verifica o sistema de arquivos EXT2 ou EXT3. Pode também ser encontrado com o nome e2fsck.
fsck.ext3 - Um alias para fsck.ext2.
fsck.minix - Verifica o sistema de arquivos Minix.
fsck.msdos - Verifica o sistema de arquivos Msdos. Pode também ser encontrado com o nome dosfsck.
Para verificar um sistema de arquivos é necessário que ele esteja desmontado caso contrário poderá ocorrer danos em sua estrutura. Para verificar o sistema de arquivos raíz (que não pode ser desmontado enquanto o sistema estiver sendo executado) você precisará inicializar através de um disquete e executar o fsck.ext2.
Este utilitário permite verificar erros em sistemas de arquivos EXT2 e EXT3 (Linux Native).
fsck.ext2 [opções] [dispositivo]
Onde:
dispositivo
É o local que contém o sistema de arquivos EXT2/EXT3 que será verificado (partições, disquetes, arquivos).
opções
-c
Faz o fsck.ext2 verificar se existem agrupamentos danificados na unidade de disco durante a checagem.
-d
Debug - Mostra detalhes de processamento do fsck.ext2.
-f
Força a checagem mesmo se o sistema de arquivos aparenta estar em bom estado. Por padrão, um sistema de arquivos que aparentar estar em bom estado não são verificados.
-F
Grava os dados do cache no disco antes de iniciar.
-l [arquivo]
Inclui os blocos listados no [arquivo] como blocos defeituosos no sistema de arquivos. O formato deste arquivo é o mesmo gerado pelo programa badblocks.
-L [arquivo]
Faz o mesmo que a opção -l, só que a lista de blocos defeituosos do dispositivo é completamente limpa e depois a lista do [arquivo] é adicionada.
-n
Faz uma verificação de somente leitura no sistema de arquivos. Com esta opção é possível verificar o sistema de arquivos montado. Será assumido não para todas as perguntas e nenhuma modificação será feita no sistema de arquivos.
Caso a opção -c seja usada junto com -n, -l ou -L, o sistema de arquivos será verificado e permitirá somente a atualização dos setores danificados não alterando qualquer outra área.
-p
Corrige automaticamente o sistema de arquivos sem perguntar. É recomendável fazer isto manualmente para entender o que aconteceu, em caso de problemas com o sistema de arquivos.
-v
Ativa o modo verbose (mais mensagens são mostradas durante a execução do programa).
-y
Assume sim para todas as questões.
Caso sejam encontrados arquivos problemáticos e estes não possam ser recuperados, o fsck.ext2 perguntará se deseja salva-los no diretório lost found. Este diretório é encontrado em todas as partições ext2. Não há risco de usar o fsck.ext3 em uma partição EXT2.
Após sua execução é mostrado detalhes sobre o sistema de arquivos verificado como quantidade de blocos livres/ocupados e taxa de fragmentação.
Procura blocos defeituosos em um dispositivo. Note que este apenas pesquisa por blocos defeituosos, sem alterar a configuração do disco. Para marcar os blocos defeituosos para não serem mais usados, utilize a opção -l do fsck (veja [#s-manut-checagem-ext2 fsck.ext2, Seção 26.1.1]).
badblocks [opções] [dispositivo]
Onde:
dispositivo
Partição, disquete ou arquivo que contém o sistema de arquivos que será verificado.
opções
-b [tamanho]
Especifica o [tamanho] do bloco do dispositivo em bytes
-o [arquivo]
Gera uma lista dos blocos defeituosos do disco no [arquivo]. Este lista pode ser usada com o programa fsck.ext2 junto com a opção -l.
-s
Mostra o número de blocos checados durante a execução do badblocks.
-v
Modo verbose - São mostrados mais detalhes.
-w
Usa o modo leitura/gravação. Usando esta opção o badblocks procura por blocos defeituosos gravando alguns padrões (0xaa, 0x55, 0xff, 0x00) em cada bloco do dispositivo e comparando seu conteúdo.
Nunca use a opção -w em um dispositivo que contém arquivos pois eles serão apagados!
Exemplo: badblocks -s /dev/hda6, badblocks -s -o bad /dev/hda6
Permite desfragmentar uma unidade de disco. A fragmentação é o armazenamento de arquivos em áreas não sequenciais (uma parte é armazenada no começo a outra no final, etc), isto diminui o desempenho da unidade de disco porque a leitura deverá ser interrompida e feita a movimentação da cabeça para outra região do disco onde o arquivo continua, por este motivo discos fragmentados tendem a fazer um grande barulho na leitura e o desempenho menor.
A desfragmentação normalmente é desnecessária no GNU/Linux porque o sistema de arquivos ext2 procura automaticamente o melhor local para armazenar o arquivo. Mesmo assim, é recomendável desfragmentar um sistema de arquivos assim que sua taxa de fragmentação subir acima de 10%. A taxa de fragmentação pode ser vista através do fsck.ext2. Após o fsck.ext2 ser executado é mostrada a taxa de fragmentação seguida de non-contiguos.
A ferramenta de desfragmentação usada no GNU/Linux é o defrag que vem com os seguintes programas:
e2defrag - Desfragmenta sistemas de arquivos Ext2.
defrag - Desfragmenta sistemas de arquivos Minix.
xdefrag - Desfragmenta sistemas de arquivos Xia.
O sistema de arquivos deve estar desmontado ao fazer a desfragmentação. Se quiser desfragmentar o sistema de arquivos raíz (/), você precisará inicializar através de um disquete e executar um dos programas de desfragmentação apropriado ao seu sistema de arquivos. A checagem individual de fragmentação em arquivos pode ser feita com o programa frag.
ATENÇÃO: Retire cópias de segurança de sua unidade antes de fazer a desfragmentação. Se por qualquer motivo o programa de desfragmentação não puder ser completado, você poderá perder dados!
e2defrag [opções] [dispositivo]
Onde:
dispositivo
Partição, arquivo, disquete que contém o sistema de arquivos que será desfragmentado.
-d
Debug - serão mostrados detalhes do funcionamento
-n
Não mostra o mapa do disco na desfragmentação. É útil quando você inicializa por disquetes e recebe a mensagem "Failed do open term Linux" ao tentar executar o e2defrag.
-r
Modo somente leitura. O defrag simulará sua execução no sistema de arquivos mas não fará nenhuma gravação. Esta opção permite que o defrag seja usado com sistema de arquivos montado.
-s
Cria um sumário da fragmentação do sistema de arquivos e performance do desfragmentador.
-v
Mostra detalhes durante a desfragmentação do sistema de arquivos. Caso mais de uma opção -v seja usada, o nível de detalhes será maior.
-i [arquivo]
Permite definir uma lista de prioridades em que um arquivo será gravado no disco, com isto é possível determinar se um arquivo será gravado no começo ou final da unidade de disco. Esta lista é lida do [arquivo] e deve conter uma lista de prioridades de -100 a 100 para cada inodo do sistema de arquivos. Arquivos com prioridade alta serão gravados no começo do disco.
Todos os inodos terão prioridade igual a zero caso a opção -i não seja usada ou o inodo não seja especificado no [arquivo]. O [arquivo] deverá conter uma série de linhas com um número (inodo) ou um número prefixado por um sinal de igual seguido da prioridade.
-p [numero]
Define o [numero] de buffers que serão usados pela ferramenta de desfragmentação na realocação de dados, quanto mais buffers mais eficiente será o processo de realocação. O número depende de quantidade memória RAM e Swap você possui. Por padrão 512 buffers são usados correspondendo a 512Kb de buffer (em um sistema de arquivos de blocos com 1Kb).
Um dos sintomas de um disco rígido que contém setores danificados (bad blocks) é a mudança repentina do sistema de arquivos para o modo somente leitura, o aparecimento de diversas mensagens no syslog indicando falha de leitura do hd, uma pausa se segundos no sistema junto com o led de atividade de disco ligado. Se isto acontece com você, uma forma de solucionar este inconveniente é executar o teste na superfície física do disco para procurar e marcar os blocos problemáticos como defeituosos.
Em alguns casos, os blocos defeituosos ocorrem isoladamente no disco rígido, não aumentando mais sua quantidade, entretanto, se o número de blocos danificados em seu disco está crescendo em um curto espaço de tempo, comece a pensar na troca do disco rígido por um outro. Existem empresas que recuperam HDs mas pelo valor cobrado por se tratar de um serviço delicado, só compensa caso você não tenha o backup e realmente precisa dos dados do disco.
Para fazer uma checagem de HD no sistema de arquivos ext2 ou ext3, proceda da seguinte forma:
Se possível, faça um backup de todos os dados ou dos dados essenciais da partição será checada.
Inicie o sistema por um disquete de boot ou CD de recuperação. Este passo é útil pois em alguns casos, pode ocorrer a perda de interrupção do disco rígido e seu sistema ficar paralisado. Só o método de checar o HD usando um disquete de boot lhe fará agendar uma parada no sistema e notificar os usuários, evitando sérios problemas do que fazendo isto com um sistema em produção.
Execute o badblocks usando a opção -o para gravar os possíveis blocos defeituosos encontrados para um arquivo: badblocks -v -o blocos-defeituosos.lista /dev/hd??.
Substitua o dispositivo /dev/hd?? pelo dispositivo que deseja verificar. A checagem do badblocks deverá ser feita para cada partição existente no disco rígido. O tempo de checagem dependerá da velocidade do disco rígido, velocidade do barramento, cabo de dados utilizado, velocidade de processamento e é claro, do estado do disco rígido (quantos setores defeituosos ele tem).
Após concluir o badblocks, veja se foram encontrados blocos defeituosos. Caso tenha encontrado, siga para o próximo passo.
Para marcar os blocos encontrados pelo badblocks como defeituosos, execute o comando: fsck.ext3 -l blocos-defeituosos.lista -f /dev/hd??.
Substitua o dispositivo, pelo dispositivo que verificou com o badblocks. O arquivo blocos-defeituosos.list contém a lista de blocos gerada pelo badblocks que serão marcados como defeituosos.
Para mais detalhes sobre as opções de checagem usada pelos programas, veja [#s-manut-badblocks badblocks, Seção 26.4] e [#s-manut-checagem-ext2 fsck.ext2, Seção 26.1.1].
Tudo que acontece em sistemas GNU/Linux pode ser registrado em arquivos de log em /var/log, como vimos anteriormente. Eles são muito úteis por diversos motivos, para o diagnóstico de problemas, falhas de dispositivos, checagem da segurança, alerta de eventuais tentativas de invasão, etc.
O problema é quando eles começam a ocupar muito espaço em seu disco. Verifique quantos Megabytes seus arquivos de LOG estão ocupando através do comando cd /var/log;du -hc. Antes de fazer uma limpeza nos arquivos de LOG, é necessário verificar se eles são desnecessários e só assim zerar os que forem dispensáveis.
Não é recomendável apagar um arquivo de log pois ele pode ser criado com permissões de acesso indevidas (algumas distribuições fazem isso). Você pode usar o comando: echo -n >arquivo ou o seguinte shell script para zerar todos os arquivos de LOG de uma só vez (as linhas iniciante com # são comentários):
#! /bin/sh
cd /var/log
for l in `ls -p|grep '/'`; do
echo -n >$l &>/dev/null
echo Zerando arquivo $l...
done
echo Limpeza dos arquivos de log concluída!
Copie o conteúdo acima em um arquivo com a extensão .sh, dê permissão de execução com o chmod e o execute como usuário root. É necessário executar este script para zerar arquivos de log em subdiretórios de /var/log, caso sejam usados em seu sistema.
Algumas distribuições, como a Debian GNU/Linux, fazem o arquivamento automático de arquivos de LOGs em arquivos .gz através de scripts disparados automaticamente pelo cron. ATENÇÃO: LEMBRE-SE QUE O SCRIPT ACIMA APAGARÁ TODOS OS ARQUIVOS DE LOGs DO SEU SISTEMA SEM POSSIBILIDADE DE RECUPERAÇÃO. TENHA ABSOLUTA CERTEZA DO QUE NÃO PRECISARÁ DELES QUANDO EXECUTAR O SCRIPT ACIMA!
Caso tenha apagado uma partição acidentalmente ou todas as partições do seu disco, uma forma simples de recuperar todos os seus dados é simplesmente recriar todas as partições com o tamanho EXATAMENTE igual ao existente anteriormente. Isto deve ser feito dando a partida com um disquete ou CD de inicialização. Após recriar todas as partições e seus tipos (83, 82 8e, etc), execute novamente o lilo para recriar o setor de boot do HD e garantir que a máquina dará o boot.
A recuperação desta forma é possível porque quando se cria ou apaga uma partição, você está simplesmente delimitando espaço onde cada sistema de arquivos gravará seus dados, sem fazer nenhuma alteração dentro dele. Assim, é também útil manter uma cópia dos tamanhos usados durante o processo de criação das partições para ser usado como recuperação em uma possível emergência.
Uma situação que você deve ter se deparado (ou algum dia ainda vai se deparar) é precisar alterar a senha de root e não sabe ou não lembra a senha atual. Esta situação também pode ser encontrada quando ocorre uma falha de disco, falha elétrica, reparos em uma máquina que não detém sua manutenção, etc. A melhor notícia é que a alteração da senha de root é possível e não apresenta problema qualquer para o sistema. Existem várias formas para se fazer isto, a forma que descreverei abaixo assume que você tem acesso a um outro dispositivo de partida que não seja o HD do Linux (CD-ROM, disquetes, outro disco rígido, etc). Assim, mesmo que encontre uma senha de BIOS em uma máquina, poderá colocar o disco rígido em outra máquina e executar estes procedimentos.
OBS: Estes procedimentos tens fins didáticos e administrativos, não sendo escritos com a intenção de fornecer mal uso desta técnica. Entender a exposição de riscos também ajuda a desenvolver novas técnicas de defesa para sistemas críticos, e estas são totalmente possíveis e as mais usadas documentadas neste guia.
Como primeiro passo consiga um CD de partida ou disquete de uma distribuição Linux. Normalmente os mesmos CDs que usou para instalar sua distribuição também são desenvolvidos para permitir a manutenção do sistema, contendo ferramentas diversas e um terminal virtual disponível para trabalhos manuais (tanto de instalação como manutenção).
Vá até a BIOS da máquina e altere a ordem de inicialização para que seu sistema inicialize a partir do disquete ou CD-ROM (dependendo do método escolhido no passo anterior).
Inicialize a partir do Disquete/CD-ROM.
Na maioria dos casos você provavelmente estará utilizando o CD-ROM que usou para instalar sua distribuição. Imediatamente quando o programa de instalação for iniciado, pressione ALTF2 para alternar para o segundo terminal virtual do sistema. O segundo terminal esta sempre disponível nas distribuições distribuições Debian, Red Hat, Conectiva, Fedora, etc.
O próximo passo será montar sua partição raíz para ser possível alterar sua senha de root. Para isto, crie um diretório onde a partição será montada (por exemplo, /target) e execute o comando mount: mount /dev/hda1 /target (assumindo que /dev/hda1 é a partição que contém seu sistema de arquivos raíz (/).
Entre no diretório /target (cd /target) e torne-o seu diretório raíz atual com o comando: chroot ..
digite passwd e entre com a nova senha de superusuário.
saia do chroot digitando exit
Digite sync para salvar todas as alterações pendentes para o disco e reinicie o sistema (pressionando-se as teclas CTRL ALT DEL, init 6, reboot).
Retire o CD da unidade de discos e altere sua BIOS para dar a partida a partir do disco rígido.
Teste e verifique se a senha de root foi alterada.
Normalmente as distribuições seguem o padrão FHS, mantendo binários de administração necessários para recuperação do sistema em caso de panes dentro da partição /, se este não for o caso de sua distribuição (hoje em dia é raro), você terá que montar sistemas de arquivos adicionais (como o /usr, /var) ou então o comando passwd não será encontrado ou terá problemas durante sua execução.
Os arquivos responsáveis pela manutenção automática do sistema se encontram em arquivos individuais localizados nos diretórios /etc/cron.daily, /etc/cron.weekly e /etc/cron.montly. A quantidade de arquivos depende da quantidade de pacotes instalado em seu sistema, porque alguns programam tarefas nestes diretórios e não é possível descrever todas, para detalhes sobre o que cada arquivo faz veja o cabeçalho e o código de cada arquivo.
Estes arquivos são executados pelo cron através do arquivo /etc/crontab. Você pode programar quantas tarefas desejar, para detalhes veja [#s-manut-cron cron, Seção 26.11] e [#s-manut-at at, Seção 26.12]. Alguns programas mantém arquivos do cron individuais em /var/spool/cron/crontabs que executam comandos periodicamente.
O cron é um daemon que permite o agendamento da execução de um comando/programa para um determinado dia/mês/ano/hora. É muito usado em tarefas de arquivamento de logs, checagem da integridade do sistema e execução de programas/comandos em horários determinados.
As tarefas são definidas no arquivo /etc/crontab e por arquivos individuais de usuários em /var/spool/cron/crontabs/[usuário] (criados através do programa crontab). Adicionalmente a distribuição Debian utiliza os arquivos no diretório /etc/cron.d como uma extensão para o /etc/crontab.
Para agendar uma nova tarefa, basta editar o arquivo /etc/crontab com qualquer editor de texto (como o ae e o vi) e definir o mês/dia/hora que a tarefa será executada. Não é necessário reiniciar o daemon do cron porque ele verifica seus arquivos a cada minuto. Veja a seção [#s-manut-cron-formato O formato de um arquivo crontab, Seção 26.11.1] para entender o formato de arquivo cron usado no agendamento de tarefas.
Valor entre 0 e 12 (identificando os meses de Janeiro a Dezembro)
Dia da Semana
Valor entre 0 e 7 (identificando os dias de Domingo a Sábado). Note que tanto 0 e 7 equivalem a Domingo.
usuário
O usuário especificado será usado para executar o comando (o usuário deverá existir).
comando
Comando que será executado. Podem ser usados parâmetros normais usados na linha de comando.
Os campos do arquivo são separados por um ou mais espaços ou tabulações. Um asterisco * pode ser usado nos campos de data e hora para especificar todo o intervalo disponível. O hífen - serve para especificar períodos de execução (incluindo a o número inicial/final). A vírgula serve para especificar lista de números. Passos podem ser especificados através de uma /. Veja os exemplos no final desta seção.
O arquivo gerado em /var/spool/cron/crontabs/[usuário] pelo crontab tem o mesmo formato do /etc/crontab exceto por não possuir o campo usuário (UID), pois o nome do arquivo já identifica o usuário no sistema.
Para editar um arquivo de usuário em /var/spool/cron/crontabs ao invés de editar o /etc/crontab use crontab -e, para listar as tarefas daquele usuário crontab -l e para apagar o arquivo de tarefas do usuário crontab -r (adicionalmente você pode remover somente uma tarefa através do crontab -e e apagando a linha correspondente).
OBS: Não esqueça de incluir uma linha em branco no final do arquivo, caso contrário o último comando não será executado.
O cron define o valor de algumas variáveis automaticamente durante sua execução; a variável SHELL é definida como /bin/sh, PATH como /usr/bin:/bin, LOGNAME, MAILTO e HOME são definidas através do arquivo /etc/passwd. Os valores padrões destas variáveis podem ser substituídos especificando um novo valor nos arquivos do cron.
Exemplos de um arquivo /etc/crontab:
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
00 10 * * * root sync
# Executa o comando sync todo o dia as 10:00
00 06 * * 1 root updatedb
# Executa o comando updatedb toda segunda-feira as 06:00.
10,20,40 * * * * root runq
# Executa o comando runq todos os dias e a toda a hora em 10, 20 e 40 minutos.
*/10 * * * * root fetchmail
# Executa o comando fetchmail de 10 em 10 minutos todos os dias
15 0 25 12 * root echo "Feliz Natal"|mail john
# Envia um e-mail as 0:15 todo o dia 25/12 para john desejando um feliz natal.
30 5 * * 1-6 root poff
# Executa o comando poff automaticamente as 5:30 de segunda-feira a sábado.
O at agenda tarefas de forma semelhante ao cron com uma interface que permite a utilização de linguagem natural nos agendamentos. Sua principal aplicação é no uso de tarefas que sejam disparadas somente uma vez. Uma característica deste programa é a execução de aplicativos que tenham passado de seu horário de execução, muito útil se o computador é desligado com frequência ou quando ocorre uma interrupção no fornecimento de energia.
Para utilizar o at, instale-o com o comando: apt-get install at. O próximo passo é criar os arquivos /etc/at.allow e at.deny. Estes arquivos são organizados no formato de um usuário por linha. Durante o agendamento, é verificado primeiro o arquivo at.allow (lista de quem pode executar comandos) e depois o at.deny (lista de quem NÃO pode executar comandos). Caso eles não existam, o agendamento de comandos é permitido a todos os usuários.
Abaixo seguem exemplos do agendamento através do comando at:
echo ls | at 10am today
Executa as 10 da manha de hoje
echo ls | at 10
05 today
Executa as 10:05 da manha de hoje
echo ls | at 10
05pm today
Executa as 10:05 da noite de hoje
echo ls | at 22
05 today
Executa as 22:05 da noite de hoje
echo ls | at 14
50 tomorrow
Executa o comando amanhã as 14:50 da tarde
echo ls | at midnight
Executa o comando a meia noite de hoje
echo ls | at midnight tomorrow
Executa o comando a meia noite de amanhã
echo ls | at noon
Executa o comando de tarde (meio dia).
at -f comandos.txt teatime
Executa os comandos especificados no arquivo "comandos.txt" no horário do café da tarde (as 16:00 horas).
at -f comandos.txt now +3 minutes
Executa os comandos especificados no arquivo "comandos.txt" daqui a 3 minutos. Também pode ser especificado "hours" ou "days".
at -f comandos.txt tomorrow 3 hours
Executa os comandos especificados no arquivo "comandos.txt" daqui a 3 horas no dia de amanhã. (se agora são 10:00, ela será executada amanhã as 13:00 da tarde).
Todas as tarefas agendadas são armazenadas em arquivos dentro do diretório /var/spool/cron/atjobs. A sintaxe de comandos para gerenciar as tarefas é semelhante aos utilitários do lpd: Para ver as tarefas, digite atq. Para remover uma tarefa, use o comando atrm seguido do número da tarefa obtida pelo atq.
Este capítulo descreve a função, parâmetros e exemplos de utilização de alguns arquivos/diretórios de configuração em /etc. Estes arquivos estão disponíveis por padrão na instalação básica do GNU/Linux, o que assegura um máximo de aproveitamento deste capítulo. Não serão descritos aqui arquivos de configuração específicos de servidores ou daemons (com exceção do inetd).
Este diretório contém links para diversos aplicativos padrões utilizados pelo sistema. Dentre eles são encontrados links para o editor do sistema e o xterm padrão usado pelo sistema.
Por exemplo, se você quiser usar o editor jed ao invés do ae ou vi, remova o link editor com o comando rm editor, localize o arquivo executável do jed com which jed e crie um link para ele ln -s /usr/bin/jed editor. De agora em diante o editor padrão usado pela maioria dos aplicativos será o jed.
Contém variáveis padrões que alteram o comportamento de inicialização dos scripts em /etc/rcS.d
Por exemplo, se quiser menos mensagens na inicialização do sistema, ajuste o valor da variável VERBOSE para no.
OBS: Somente modifique aquilo que tem certeza do que está fazendo, um valor modificado incorretamente poderá causar falhas na segurança de sua rede ou no sistemas de arquivos do disco.
Este arquivo contém configurações padrões do pacote console-tools para as fontes de tela e mapas de teclado usados pelo sistema. A fonte de tela é especificada neste arquivo (as fontes disponíveis no sistema estão localizadas em /usr/share/consolefonts).
Os arquivos de mapa de teclados estão localizados no diretório /usr/share/keymaps/.
Este é o arquivo de configuração usado pelos programas ifup e ifdown, respectivamente para ativar e desativar as interfaces de rede.
O que estes utilitários fazem na realidade é carregar os utilitários ifconfig e route através dos argumentos passados do arquivo /etc/network/interfaces, permitindo que o usuário iniciante configure uma interface de rede com mais facilidade.
Abaixo um exemplo do arquivo interfaces é o seguinte:
As interfaces e roteamentos são configurados na ordem que aparecem neste arquivo. Cada configuração de interface inicia com a palavra chave iface. A próxima palavra é o nome da interface que deseja configurar (da mesma forma que é utilizada pelos comandos ifconfig e route). Você pode também usar IP aliases especificando eth0:0 mas tenha certeza que a interface real (eth0) é inicializada antes.
A próxima palavra especifica a familia de endereços da interface; Escolha inet para a rede TCP/IP, ipx para interfaces IPX e IPv6 para interfaces configuradas com o protocolo IPV6.
A palavra static especifica o método que a interface será configurada, neste caso é uma interface com endereço estático (fixo).
Outros métodos e seus parâmetros são especificados abaixo (traduzido da página do arquivo interfaces):
O método loopback
É usado para configurar a interface loopback (lo) IPv4.
O método static
É usado para configurar um endereço IPv4 fixo para a interface. As opções que podem ser usadas com o métodos static são as seguintes (opções marcadas com * no final são requeridas na configuração):
address endereço *
Endereço IP da Interface de rede (por exemplo, 192.168.1.1).
netmask máscara *
Máscara de rede da Interface de rede (por exemplo, 255.255.255.0).
broadcast endereço
Endereço de Broadcast da interface (por exemplo, 192.168.1.255).
network endereço
Endereço da rede (por exemplo, 192.168.0.0).
gateway endereço
Endereço do gateway padrão (por exemplo, 192.168.1.10). O gateway é o endereço do computador responsável por conectar o seu computador a outra rede. Use somente se for necessário em sua rede.
O método dhcp
Este método é usado para obter os parâmetros de configuração através de um servidor DHCP da rede através das ferramentas: dhclient, pump (somente Kernels 2.2.x) ou dpcpcp (somente kernels 2.0.x e 2.2.x)
hostname nome
Nome da estação de trabalho que será requisitado. (pump, dhcpcd)
Este método pode ser usado para obter um endereço via bootp:
bootfile arquivo
Diz ao servidor para utilizar arquivo como arquivo de inicialização
server endereço
Especifica o endereço do servidor bootp.
hwaddr endereço
Usa endereço como endereço de hardware no lugar do endereço original.
Algumas opções se aplicam a todas as interfaces e são as seguintes:
noauto
Não configura automaticamente a interface quando o ifup ou ifdown são executados com a opção -a (normalmente usada durante a inicialização ou desligamento do sistema).
pre-up comando
Executa o comando antes da inicialização da interface.
up comando
Executa o comando após a interface ser iniciada.
down comando
Executa o comando antes de desativar a interface.
pre-down comando
Executa o comando após desativar a interface.
Os comandos que são executados através das opções up, pre-up e down podem aparecer várias vezes na mesma interface, eles são executados na sequência que aparecem. Note que se um dos comandos falharem, nenhum dos outros será executado. Você pode ter certeza que os próximos comandos serão executados adicionando || true ao final da linha de comando.
Este arquivo contém opções que serão aplicadas as interfaces de rede durante a inicialização do sistema. Este arquivo é lido pelo script de inicialização /etc/init.d/network que verifica os valores e aplica as modificações apropriadas no kernel.
Este diretório contém arquivos para controle de segurança e limites que serão aplicados aos usuários do sistema. O funcionamento de muitos dos arquivos deste diretório depende de modificações nos arquivos em /etc/pam.d para habilitar as funções de controle, acesso e restrições.
É lido no momento do login do usuário e permite definir quem terá acesso ao sistema e de onde tem permissão de acessar sua conta. O formato deste arquivo são 3 campos separados por :, cada linha contendo uma regra de acesso.
O primeiro campo deve conter o caracter ou - para definir se aquela regra permitirá ( ) ou bloqueará(-) o acesso do usuário.
O segundo campo deve conter uma lista de logins, grupos, usuário@computador ou a palavra ALL (confere com tudo) e EXCEPT (exceção).
O terceiro campo deve conter uma lista de terminais tty (para logins locais), nomes de computadores, nomes de domínios (iniciando com um .), endereço IP de computadores ou endereço IP de redes (finalizando com .). Também pode ser usada a palavra ALL, LOCAL e EXCEPT (atinge somente máquinas locais conhecidas pelo sistema).
Abaixo um exemplo do access.conf
# Somente permite o root entrar em tty1
#
-:ALL EXCEPT root:tty1
# bloqueia o logins do console a todos exceto whell, shutdown e sync.
#
-:ALL EXCEPT wheel shutdown sync:console
# Bloqueia logins remotos de contas privilegiadas (grupo wheel).
#
-:wheel:ALL EXCEPT LOCAL .win.tue.nl
# Algumas contas não tem permissão de acessar o sistema de nenhum lugar:
#
-:wsbscaro wsbsecr wsbspac wsbsym wscosor wstaiwde:ALL
# Todas as outras contas que não se encaixam nas regras acima, podem acessar de
# qualquer lugar
Contém detalhes para a montagem dos sistemas de arquivos do sistema. Veja [ch-disc.html#s-disc-fstab fstab, Seção 5.13.1] para detalhes sobre o formato deste arquivo.
Lista de grupos existentes no sistema. Veja [ch-cmdc.html#s-cmdc-incluirgrupo Adicionando o usuário a um grupo extra, Seção 12.10] para mais detalhes sobre o formato deste arquivo.
Senhas ocultas dos grupos existentes no sistema (somente o usuário root pode ter acesso a elas). Use o utilitário shadowconfig para ativar/desativar o suporte a senhas ocultas.
Banco de dados DNS estático que mapeia o nome ao endereço IP da estação de trabalho (ou vice versa). Veja [ch-rede.html#s-rede-dns-a-hosts /etc/hosts, Seção 15.6.2.3] para mais detalhes sobre o formato deste arquivo.
Controle de acesso do wrapper TCPD que permite o acesso de determinadas de determinados endereços/grupos aos serviços da rede. Veja [ch-rede.html#s-rede-seg-tcpd-a /etc/hosts.allow, Seção 15.8.3.1] para detalhes sobre o formato deste arquivo.
Controle de acesso do wrapper TCPD que bloqueia o acesso de determinados endereços/grupos aos serviços da rede. Este arquivo é somente lido caso o /etc/hosts.allow não tenha permitido acesso aos serviços que contém. Um valor padrão razoavelmente seguro que pode ser usado neste arquivo que serve para a maioria dos usuários domésticos é:
ALL: ALL
caso o acesso ao serviço não tenha sido bloqueado no hosts.deny, o acesso ao serviço é permitido.
Veja [ch-rede.html#s-rede-seg-tcpd-d /etc/hosts.deny, Seção 15.8.3.2] para detalhes sobre o formato deste arquivo.
Este é o arquivo de configuração utilizado pelo programa init para a inicialização do sistema. Para mais detalhes sobre o formato deste arquivo, consulte a página de manual do inittab.
Este arquivo contém parâmetros para a configuração do teclado. Veja o final da seção [ch-cfg.html#s-cfg-acentuacao-t Acentuação em modo Texto, Seção 23.1.1] e a página de manual do inputrc para mais detalhes.
Mesma utilidade do /etc/issue mas é mostrado antes do login de uma seção telnet. Outra diferença é que este arquivo aceita os seguintes tipos de variáveis:
%t - Mostra o terminal tty atual.
%h - Mostra o nome de domínio completamente qualificado (FQDN).
Arquivo de configuração do gerenciador de partida lilo. Veja [ch-boot.html#s-boot-lilo LILO, Seção 6.1] e [ch-boot.html#s-boot-lilo-exemplo Um exemplo do arquivo de configuração lilo.conf, Seção 6.1.3].
Mostra um texto ou mensagem após o usuário se logar com sucesso no sistema. Também é usado pelo telnet, ftp, e outros servidores que requerem autenticação do usuário (nome e senha).
É o arquivo mais cobiçado por Hackers porque contém os dados pessoais do usuário como o login, uid, telefone e senha (caso seu sistema esteja usando senhas ocultas, a senha terá um * no lugar e as senhas reais estarão armazenadas no arquivo /etc/shadow).
Configurações das portas seriais do sistema. Veja a página de manual do serial.conf e a página de manual do utilitário setserial para detalhes de como configurar adequadamente a taxa de transmissão serial conforme seu dispositivo.
Contém configurações para definir o que será registrado nos arquivos de log em /var/log do sistema. Veja a página de manual syslog.conf e dos programas klog e syslogd para entender o formato usado neste arquivo.
Contém a sua localização para cálculo correto do seu fuso-horário local.
Obs: em outras distribuições, os arquivos podem ser diferentes. Por exemplo, no Fedora e Mandriva, o arquivo é /etc/localtime, e não é um arquivo editável (porém pode ser alterado usando-se cp: cp /usr/share/zoneinfo/Portugal /etc/localtime adota a hora padrão de Portugal como a hora do sistema; obviamente, o bom senso recomenda que a hora do sistema seja sempre GMT).
A conexão através de banda larga em sistemas Debian é realizada através do programa pppoeconf ou modificando manualmente os arquivos de configuração em /etc/ppp. Esta seção explicará como configurar a conexão em modo bridge e assume que você já tem o modem conectado e sua placa de rede configurada. Para criar uma conexão internet através do pppoeconf entre como usuário root no sistema, digite pppoeconf e siga os passos de configuração:
Na primeira tela, ele perguntará se deseja que o modem seja detectado automaticamente. Selecione sim. O sistema procurará e detectará o modem no sistema (assegure-se que ele esteja ligado durante essa etapa).
Ao detectar o modem siga adiante e informe o nome de usuário para conexão. O nome do usuário deve ser completo, na forma nome@provedor.xx.yy
Em seguida informe a senha usada para autenticação
Nas próximas telas, selecione o valor padrão para MTU e MSS (a não ser que seu provedor DSL solicite a alteração).
Na tela sobre se a conexão deve ser iniciada na inicialização do sistema, selecione "Sim".
No sistema Fedora, pode-se usar o programa system-config-network [1]
Para conectar usando internet discada é utilizada a placa de Fax-Modem. A conexão através de sistemas Debian é fácil, e todo o trabalho de configuração pode ser feito através do programa pppconfig ou modificando manualmente os arquivos em /etc/ppp. Para criar uma conexão internet através do pppconfig, entre como usuário root no sistema, digite pppconfig e siga os passos de configuração (esta configuração serve para usuários domésticos e assume que você possui o kernel com suporte a PPP):
No primeiro menu, escolha a opção Create para criar uma nova conexão. As outras opções disponíveis são Change para modificar uma conexão a Internet criada anteriormente, Delete para apagar uma conexão. A opção Quit sai do programa.
Agora o sistema perguntará qual será o nome da conexão que será criada. O nome provider é o padrão, e será usado caso digite pon para iniciar uma conexão internet sem nenhum argumento.
O próximo passo é especificar como os servidores de nomes serão acessados. Escolha Static se não tiver nenhum tipo de rede local ou None para usar os servidores especificados no arquivo /etc/resolv.conf.
Aperte a tecla TAB e tecle ENTER para seguir para o próximo passo.
Agora digite o endereço do servidor DNS especificado pelo seu provedor de acesso. Um servidor DNS converte os nomes como www.blablabla.com.br para o endereço IP correspondente para que seu computador possa fazer conexão.
Tecle ENTER para seguir para o próximo passo.
Você pode digitar um endereço de um segundo computador que será usado na resolução de nomes DNS. Siga as instruções anteriores caso tiver um segundo servidor de nomes ou ENTER para continuar.
Agora você precisará especificar qual é o método de autenticação usado pelo seu provedor de acesso. O Password Autentication Protocol é usado pela maioria dos provedores de acesso. Desta forma escolha a opção PAP
Agora entre com o seu login no provedor de acesso, ou seja, o nome para acesso ao sistema que escolheu no momento que fez sua assinatura.
Agora especifique a sua senha.
O próximo passo será especificar a taxa de transmissão da porta serial do micro. O valor de 115200 deve funcionar com todas as configurações mais recentes.
Uma configuração serial DTE detalhada pode ser feita com a ferramenta setserial.
Agora será necessário selecionar o modo de discagem usado pelo seu fax-modem. Escolha tone para linha digital e pulse se possuir uma linha telefônica analógica.
Pressione TAB e tecle ENTER para prosseguir.
Agora digite o número do telefone para fazer conexão com o seu provedor de acesso.
O próximo passo será a identificação do seu fax-modem, escolha YES para que seja utilizada a auto-detecção ou NO para especificar a localização do seu fax-modem manualmente.
Se você quiser especificar mais detalhes sobre sua configuração, como strings de discagem, tempo de desconexão, auto-discagem, etc., faça isto através do menu Advanced.
Escolha a opção Finished para salvar a sua configuração e retornar ao menu principal. Escolha a opção Quit para sair do programa.
Pronto! todos os passos para você se conectar a Internet estão concluídos, basta digitar pon para se conectar e poff para se desconectar da Internet. Caso tenha criado uma conexão com o nome diferente de provider você terá que especifica-la no comando pon (por exemplo, pon provedor2).
A conexão pode ser monitorada através do comando plog e os pacotes enviados/recebidos através do pppconfig.
Para uma navegação mais segura, é recomendável que leia e compreenda alguns ítens que podem aumentar consideravelmente a segurança do seu sistema em [ch-rede.html#s-rede-seg Segurança da Rede e controle de Acesso, Seção 15.8], [ch-rede.html#s-rede-seg-tcpd-a /etc/hosts.allow, Seção 15.8.3.1], [ch-rede.html#s-rede-seg-tcpd-d /etc/hosts.deny, Seção 15.8.3.2]. A seção [ch-rede.html#s-rede-dns-a-resolv /etc/resolv.conf, Seção 15.6.2.1] pode ser também útil.
Para conectar-se à uma rede wireless, primeiro é preciso verificar se existe (e funciona) o hardware para isso, e se existe uma rede wireless no local.
Um comando útil para verificar tudo isso é:
iwlist scanning
que lista os dispositivos wireless do computador e as redes. Caso não haja nenhum dispositivo wireless no computador, é necessário configurar este hardware; para isto ver [[../../Hardware/Configurações de Dispositivos]]. Usuários da distribuição Ubuntu podem consultar a documentação no site da distribuição[2].
Existem diversos tipos de navegadores web para GNU/Linux e a escolha depende dos recursos que pretende utilizar (e do poder de processamento de seu computador).
Para navegar na Internet com muitos recursos, você pode usar o navegador Firefox, ele suporta plug-ins, extensões adicionais, java, flash, etc. Você também tem a escolha do Mozilla que inspirou a criação do Netscape e outros navegadores derivados.
O dillo é uma boa alternativa para aqueles que desejam um navegador em modo gráfico, mas eles não tem suporte a Java e Frames.
Os usuários e administradores de servidores que operam em modo texto e precisam de navegadores para testes, podem optar pelo Lynx ou o links. Uma listagem mais detalhada e recursos requeridos por cada navegador podem ser encontrados em [ch-aplic.html#s-aplic-b-internet Internet, Seção 30.1.3].
É o programa mais tradicional no recebimento de mensagens através dos serviços pop3, imap, pop2, etc. no GNU/Linux. Ele pega as mensagens de seu servidor pop3 e as entrega ao MDA local ou nos arquivos de e-mails dos usuários do sistema em /var/mail
Todo o funcionamento do fetchmail é controlado pelo arquivo ~/.fetchmailrc. Segue abaixo um modelo padrão deste arquivo:
poll pop3.seuprovedor.com.br protocol pop3
user gleydson password sua_senha keep fetchall is gleydson here
Este arquivo é lido pelo fetchmail na ordem que foi escrito. Veja a explicação abaixo sobre o arquivo exemplo:
A palavra poll especifica o servidor de onde suas mensagens serão baixadas, o servidor especificado no exemplo é pop3.seuprovedor.com.bt. A palavra skip pode ser especificada, mas as mensagens no servidor especificado por skip somente serão baixadas caso o nome do servidor de mensagens for especificado através da linha de comando do fetchmail.
protocol é o protocolo que será usado para a transferência de mensagens do servidor. O fetchmail utilizará a auto-detecção de protocolo caso este não seja especificado.
user define o nome do usuário no servidor pop3.seuprovedor.com.br, que no exemplo acima é gleydson.
password define a senha do usuário gleydson (acima), especificada como sua_senha no exemplo.
keep é opcional e serve para não apagar as mensagens do servidor após baixa-las (útil para testes e acesso a uma única conta de e-mail através de vários locais, como na empresa e sua casa por exemplo).
fetchall baixa todas as mensagens do provedor marcadas como lidas e não lidas.
is gleydson here é um modo de especificar que as mensagens obtidas de pop3.seuprovedor.com.br do usuário gleydson com a senha sua_senha serão entregues para o usuário local gleydson no diretório /var/mail/gleydson.
As palavras is e here são completamente ignoradas pelo fetchmail, servem somente para dar um tom de linguagem natural na configuração do programa e da mesma forma facilitar a compreensão da configuração.
Se possuir várias contas no servidor pop3.seuprovedor.com.br, não é necessário repetir toda a configuração para cada conta, ao invés disso especifique somente os outros usuários do mesmo servidor:
poll pop3.seuprovedor.com.br protocol pop3
user gleydson password sua_senha keep fetchall is gleydson here
user conta2 password sua_senha2 fetchall is gleydson here
user conta3 password sua_senha3 fetchall is gleydson here
Note que todos os e-mails das contas gleydson, conta2 e conta3 do servidor de mensagens pop3.seuprovedor.com.br são entregues ao usuário local gleydson (arquivo /var/mail/gleydson).
Agora você pode usar um programa MUA como o mutt ou pine para ler localmente as mensagens. O armazenamento de mensagens no diretório /var/mail é preferido pois permite a utilização de programas de notificação de novos e-mais como o comsat, mailleds, biff, etc.
Também é possível utilizar um processador de mensagens ao invés do MTA para a entrega de mensagens. O programa procmail é um exemplo de processador de mensagens rápido e funcional que pode separar as mensagens em arquivos de acordo com sua origem, destino, assunto, enviar respostas automáticas, listas de discussão, envio de arquivos através de requisição, etc. Veja [#s-inter-procmail Processamento de mensagens através do procmail, Seção 28.3.1] para detalhes.
Para mais detalhes sobre outras opções específicas de outros protocolos, checagem de mensagens, criptografia, etc, veja a página de manual do fetchmail.
O processamento de mensagens pode ser usado para inúmeras finalidades, dentre elas a mais comum é separar uma mensagem em arquivos/diretórios de acordo com sua origem, prioridade, assuntos, destinatário, conteúdo, etc., programar auto-respostas, programa de férias, servidor de arquivos, listas de discussão, etc.
O procmail é um programa que reúne estas funções e permitem muito mais, dependendo da habilidades e conhecimento das ferramentas GNU/Linux para saber integra-las corretamente. Toda a operação do procmail é controlada pelo arquivo /etc/procmailrc e ~/.procmailrc. Abaixo um modelo do arquivo ~/.procmailrc usado para enviar todas as mensagens contendo a palavra GNU/Linux no assunto para o arquivo mensagens-linux:
A variável de ambiente MAILDIR especifica o diretório que serão armazenadas as mensagens e logs das operações do procmail. A variável DEFAULT especifica a caixa de correio padrão onde todas as mensagens que não se encaixam nas descrições do filtro do procmailrc serão enviadas. A variável LOGFILE especifica o arquivo que registrará todas as operações realizadas durante o processamento de mensagens do procmail.
O arquivo mensagens-linux é criado dentro do diretório especificado por MAILDIR.
Para que o procmail entre em ação toda vez que as mensagens forem baixadas via fetchmail, é preciso modificar o arquivo .fechmailrc e incluir a linha mda /usr/bin/procmail -d %T no final do arquivo e retirar as linhas is [usuáriolocal] here para que o processamento das mensagens seja feita pelo MDA local (neste caso, o procmail).
Se quiser que o procmail seja executado pelo MDA local, basta criar um arquivo ~/.forward no diretório do usuário e incluir a linha exec /usr/bin/procmail (note que em algumas implementações do exim, o procmail é executado automaticamente caso um arquivo ~/.procmailrc seja encontrado, caso contrário será necessário adicionar a linha "/usr/bin/procmail" ao arquivo ~/.forward (somente exim).
Para mais detalhes, veja a página de manual do procmail, procmailrc e HOWTOs relacionados com e-mails no GNU/Linux.
É um sistema gráfico de janelas que roda em uma grande faixa de computadores, máquinas gráficas e diferentes tipos de máquinas e plataformas Unix. Pode tanto ser executado em máquinas locais como remotas através de conexão em rede.
Em geral o ambiente gráfico X Window é dividido da seguinte forma:
O Servidor X - É o programa que controla a exibição dos gráficos na tela, mouse e teclado. Ele se comunica com os programas cliente através de diversos métodos de comunicação.
O servidor X pode ser executado na mesma máquina que o programa cliente esta sendo executado de forma transparente ou através de uma máquina remota na rede.
O gerenciador de Janelas - É o programa que controla a aparência da aplicação. Os gerenciadores de janelas (window managers) são programas que atuam entre o servidor X e a aplicação. Você pode alternar de um gerenciador para outro sem fechar seus aplicativos.
Existem vários tipos de gerenciadores de janelas disponíveis no mercado entre os mais conhecidos posso citar o Window Maker (feito por um Brasileiro), o After Step, Gnome, KDE, twm (este vem por padrão quando o servidor X é instalado), Enlightenment, IceWm, etc.
A escolha do seu gerenciador de janelas é pessoal, depende muito do gosto de cada pessoa e dos recursos que deseja utilizar.
A aplicação cliente - É o programa sendo executado.
Esta organização do ambiente gráfico X traz grandes vantagens de gerenciamento e recursos no ambiente gráfico UNIX, uma vez que tem estes recursos você pode executar seus programas em computadores remotos, mudar totalmente a aparência de um programa sem ter que fecha-lo (através da mudança do gerenciador de janelas), etc.
O sistema gráfico X pode ser iniciado de duas maneiras:
Automática - Usando um gerenciador de seção como xdm, gdm ou wdm que apresenta uma tela pedindo nome e senha para entrar no sistema (login). Após entrar no sistema, o X executará um dos gerenciadores de janelas configurados.
Manual - Através do comando startx, ou xinit (note que o startx e xstart são scripts que fazem uma configuração completa do ambiente e em algumas distribuições também o procedimento de configuração de autenticação do ambiente antes de executar o xinit) . Neste caso o usuário deve entrar com seu nome e senha para entrar no modo texto e então executar um dos comandos acima. Após executar um dos comandos acima, o servidor X será iniciado e executará um dos gerenciadores de janelas configurados no sistema.
Como dito acima, o servidor X controla o teclado, mouse e a exibição dos gráficos em sua tela. Para ser executado, precisa ser configurado através do arquivo /etc/X11/xorg.conf, usando dpkg-reconfigure xserver-xorg, ou usando o utilitário xf86cfg (modo texto).
A finalização do servidor X é feita através do pressionamento simultâneo das teclas CTRL, ALT, Back Space. O servidor X é imediatamente terminado e todos os gerenciadores de janelas e programas clientes são fechados.
CUIDADO: Sempre utilize a opção de saída de seu gerenciador de janelas para encerrar normalmente uma seção X11 e salve os trabalhos que estiver fazendo antes de finalizar uma seção X11. A finalização do servidor X deve ser feita em caso de emergência quando não se sabe o que fazer para sair de um gerenciador de janelas ou de um programa mal comportado.
Recomendo fazer a leitura de [ch-run.html#s-run-fechando Fechando um programa quando não se sabe como sair, Seção 7.15] caso estiver em dúvidas de como finalizar um programa mal comportado ou que não sabe como sair.
As páginas de manual acompanham quase todos os programas GNU/Linux. Elas trazem uma descrição básica do comando/programa e detalhes sobre o funcionamento de opção. Uma página de manual é visualizada na forma de texto único com rolagem vertical. Também documenta parâmetros usados em alguns arquivos de configuração.
A utilização da página de manual é simples, digite:
man [seção] [comando/arquivo]
onde:
seção
É a seção de manual que será aberta, se omitido, mostra a primeira seção sobre o comando encontrada (em ordem crescente).
comando/arquivo
Comando/arquivo que deseja pesquisar.
A navegação dentro das páginas de manual é feita usando-se as teclas:
q - Sai da página de manual
PageDown ou f - Rola 25 linhas abaixo
PageUP ou w - Rola 25 linhas acima
SetaAcima ou k - Rola 1 linha acima
SetaAbaixo ou e - Rola 1 linha abaixo
r - Redesenha a tela (refresh)
p ou g - Inicio da página
h - Ajuda sobre as opções da página de manual
s - Salva a página de manual em formato texto no arquivo especificado (por exemplo: /tmp/ls).
Cada seção da página de manual contém explicações sobre uma determinada parte do sistema. As seções são organizadas em diretórios separados e localizadas no diretório /usr/man. Os programas/arquivos são classificados nas seguintes seções:
Programas executáveis ou comandos internos
Chamadas do sistema (funções oferecidas pelo kernel)
Chamadas de Bibliotecas (funções dentro de bibliotecas do sistema)
Arquivos especiais (normalmente encontrados no diretório /dev)
Formatos de arquivos e convenções (/etc/inittab por exemplo).
Jogos
Pacotes de macros e convenções (por exemplo man)
Comandos de Administração do sistema (normalmente usados pelo root)
Rotinas do kernel (não padrões)
A documentação de um programa também pode ser encontrada em 2 ou mais categorias, como é o caso do arquivo host_access que é documentado na seção 3 (bibliotecas) e 5 (formatos de arquivo). Por este motivo é necessário digitar man 5 hosts_access para ler a página sobre o formato do arquivo, porque o comando man procura a página de manual nas seções em ordem crescente e a digitação do comando man hosts_access abriria a seção 3.
As páginas de manual contém algumas regras para facilitar a compreensão do comando:
Texto Negrito - Deve ser digitado exatamente como é mostrado
[bla bla bla] - Qualquer coisa dentro de [] são opcionais
Idêntico as páginas de manual, mas é usada navegação entre as páginas. Se pressionarmos <Enter> em cima de uma palavra destacada, a info pages nos levará a seção correspondente. A info pages é útil quando sabemos o nome do comando e queremos saber para o que ele serve. Também traz explicações detalhadas sobre uso, opções e comandos.
Para usar a info pages, digite:
info [comando/programa]
Se o nome do comando/programa não for digitado, a info pages mostra a lista de todos os manuais de comandos/programas disponíveis. A navegação da info pages é feita através de nomes marcados com um "*" (hipertextos) que se pressionarmos <Enter>, nos levará até a seção correspondente. A info pages possui algumas teclas de navegação úteis:
q - Sai da info pages
? - Mostra a tela de ajuda (que contém a lista completa de teclas de navegação e muitos outras opções).
n - Avança para a próxima página
p - Volta uma página
u - Sobre um nível do conteúdo (até checar ao índice de documentos)
m - Permite usar a localização para encontrar uma página do info. Pressione m, digite o comando e tecle <Enter> que será levado automaticamente a página correspondente.
d - Volta ao índice de documentos.
Existem muitos outras teclas de navegação úteis na info pages, mas estas são as mais usadas. Para mais detalhes, entre no programa info e pressione ?.
Ajuda rápida, é útil para sabermos quais opções podem ser usadas com o comando/programa. Quase todos os comandos/programas GNU/Linux oferecem este recurso que é útil para consultas rápidas (e quando não precisamos dos detalhes das páginas de manual). É útil quando se sabe o nome do programa mas deseja saber quais são as opções disponíveis e para o que cada uma serve. Para acionar o help on line, digite:
[comando] --help
comando - é o comando/programa que desejamos ter uma explicação rápida.
O Help on Line não funciona com comandos internos (embutidos no Bash), para ter uma ajuda rápida sobre os comandos internos, veja [#s-ajuda-help help, Seção 31.4].
Ajuda rápida, útil para saber que opções podem ser usadas com os comandos internos do interpretador de comandos. O comando help somente mostra a ajuda para comandos internos, para ter uma ajuda similar para comandos externos, veja [#s-ajuda-helponline Help on line, Seção 31.3]. Para usar o help digite:
Apropos procura por programas/comandos através da descrição. É útil quando precisamos fazer alguma coisa mas não sabemos qual comando usar. Ele faz sua pesquisa nas páginas de manual existentes no sistema e lista os comandos/programas que atendem a consulta. Para usar o comando apropos digite:
apropos [descrição]
Digitando apropos copy, será mostrado todos os comandos que tem a palavra copy em sua descrição (provavelmente os programas que copiam arquivos, mas podem ser mostrados outros também).
Localiza uma palavra na estrutura de arquivos/diretórios do sistema. É útil quando queremos localizar onde um comando ou programa se encontra (para copia-lo, curiosidade, etc). A pesquisa é feita em um banco de dados construído com o comando updatedb sendo feita a partir do diretório raíz / e sub-diretórios. Para fazer uma consulta com o locate usamos:
locate [expressão]
A expressão deve ser o nome de um arquivo diretório ou ambos que serão procurados na estrutura de diretórios do sistema. Como a consulta por um programa costuma localizar também sua página de manual, é recomendável usar "pipes" para filtrar a saída do comando (para detalhes veja [ch-redir.html#s-redir-pipe | (pipe), Seção 14.5] .
Por exemplo, para listar os diretórios que contém o nome "cp": locate cp. Agora mostrar somente arquivos binários, usamos: locate cp|grep bin/
Localiza um programa na estrutura de diretórios do path. É muito semelhante ao locate, mas a busca é feita no path do sistema e somente são mostrados arquivos executáveis .
which [programa/comando].
Integridade de Dados.
Os mecanismos de controlo de integridade de dados actuam em dois níveis:Controlo da integridade de pacotes isolados e controlo da integridade de uma conexão, isto é dos pacotes e das sequência de tramissão.
São documentos em formato texto, html, etc, que explicam como fazer determinada tarefa ou como um programa funciona. Normalmente são feitos na linguagem SGML e convertidos para outros formatos (como o texto, HTML, Pos Script) depois de prontos.
Estes trazem explicações detalhadas desde como usar o bash até sobre como funciona o modem ou como montar um servidor internet completo. Os HOWTO´s podem ser encontrados no diretório do projeto de documentação do GNU/Linux (LDP) em ftp://metalab.unc.edu/pub/Linux/docs/HOWTO/ ou traduzidos para o Português pelo LDP-BR em http://www.tldp.org/projetos/howto/traduzidos.php. Caso tenha optado por instalar o pacote de HOWTO's de sua distribuição GNU/Linux, eles podem ser encontrados em: /usr/doc/how-to
Esta seção tem a intenção de facilitar a localização de um documento que trata do assunto desejado ou te despertar a curiosidade sobre alguns assuntos do SO-GNU/Linux através da descrição contida nos documentos. Segue abaixo uma listagem de HOWTO's do projeto LDP organizadas por sub-seções com a descrição do assunto que cada um deles aborda.
Introdução ao Sistema / Instalação / Configurações / Kernel
O HOWTO de Acesso ao GNU/Linux cobre o uso de tecnologia adaptada para tornar o GNU/Linux acessível í queles que não o utilizam. Ele cobre áreas onde ele pode usar soluções tecnológicas adaptadas.
Bash-Prompt-HOWTO
Explica como criar e controlar um terminal e aviso de comando xterm, incluindo sequências de escape incorporadas para passar o nome do usuário, diretório atual, hora, uso de cores ANSI, etc.
Bootdisk-HOWTO
Explica como criar seu próprio disco de inicialização/raíz para o GNU/Linux.
BootPrompt-HOWTO
Este documento reúne a maioria dos parâmetros de inicialização que podem ser passados ao kernel do GNU/Linux durante a inicialização do sistema. Também explica como o kernel classifica os argumentos de inicialização e também os softwares usados para inicialização do kernel do GNU/Linux.
Compaq-Remote-Insight-Board-HOWTO
Descreve como instalar o Linux no servidor Compaq ProLiant.
Config-HOWTO
Este documento ensina como fazer um ajuste fino em sua máquina GNU/Linux recém instalada rápido e fácil. Neste documento você encontrará um conjunto de configurações para as aplicações e serviços mais populares.
Distribution-HOWTO
Este documento tem a intenção de ajudar novos usuários escolherem uma distribuição GNU/Linux e ajudar usuários experientes a avaliar o estado do marketing no GNU/Linux Ele não planeja ser uma lista completa de distribuições GNU/Linux para todas as plataformas, mas ao invés disso se focaliza nas distribuições em Inglês baseadas no processador Intel, disponíveis em CD-ROM e acessíveis a usuários novatos no sistema.
From-PowerUp-To-Bash-Prompt-HOWTO
Contém uma breve descrição sobre o que acontece no sistema GNU/Linux, do momento que liga o seu computador até o login no aviso do bash. Ele é organizado por pacotes para torna-lo fácil para pessoas que desejam construir um sistema através do código fonte. Entendendo isto será útil quando precisar resolver problemas ou configurar o seu sistema.
Installation-HOWTO
Este documento descreve como obter e instalar o software GNU/Linux. Ele é o primeiro documento que um novo usuário GNU/Linux dev ler para iniciar no sistema.
INFO-SHEET
Este documento oferece informações básicas sobre o sistema operacional GNU/Linux, incluindo uma explicação sobre o sistema, uma lista de características, alguns requerimentos e alguns recursos.
Kernel-HOWTO
Este é um guia detalhado de configuração do kernel, compilação, upgrades e problemas para sistemas baseados.
PLIP-Install-HOWTO
Descreve como instalar uma distribuição GNU/Linux em um computador sem placa Ethernet, ou CD-ROM, mas apenas com uma unidade de disquetes local e um servidor NFS remoto conectado via um cabo paralelo.
Reading-List-HOWTO
Lista os livros mais valiosos para uma pessoa que deseja aprender o sistema operacional Unix (especialmente o GNU/Linux).
Software-Building-HOWTO
Guia compreensivo de como construir e instalar distribuições de softwares "genéricas" UNIX sob o GNU/Linux. Adicionalmente existe alguma cobertura dos binários pré-empacotados "rpm" e "deb".
Tips-HOWTO
Este documento descreve algumas dicas difíceis de encontrar e truques que fazem o GNU/Linux um pouco melhor.
Unix-and-Internet-Fundamentals-HOWTO
Este documento descreve a base de funcionamento dos computadores da classe PC, sistemas operacionais Unix e a Internet em linguagem não técnica.
User-Authentication-HOWTO
Explica como as informações de usuário e grupo são armazenadas e como os usuários são autenticados no sistema GNU/Linux (PAM) e como melhorar a autenticação de seu sistema.
Descreve sistemas de arquivos e o acesso aos sistemas de arquivos.
Large-Disk-HOWTO
Tudo sobre a geometria e o limite de 1024 cilindros para os discos.
LVM-HOWTO
Um HOWTO descritivo sobre o GNU/Linux LVM.
Loopback-Encrypted-Filesystem-HOWTO
Este documento explica como criar e utilizar um sistema de arquivos que, quando montado por um usuários, encripta transparentemente e dinamicamente seu conteúdo. O sistema de arquivos é armazenado em um arquivo regular, que pode ser oculto ou nomeado para algo que não chama a atenção, como algo que nunca seria procurado. Isto permite um alto nível de segurança dos dados armazenados.
Multi-Disk-HOWTO
Este documento descreve como utilizar da melhor maneira múltiplos discos e partições em um sistema GNU/Linux. Muitos dos detalhes descritos aqui podem também ser aplicados a outros sistemas operacionais multi-tarefas.
MultiOS-HOWTO
Este documento cobre os procedimentos para utilizar discos rígidos removíveis para instalar e gerenciar múltiplos sistemas operacionais alternativos enquanto deixa um disco rígido simples fixo para proteger o sistema operacional primário. É muito escalável e oferece uma boa grade de proteção e um ambiente de disco estável para o sistema operacional primário.
Optical-Disk-HOWTO
Este documento descreve a instalação e configuração de unidades de disco óticos para GNU/Linux.
Root-RAID-HOWTO
Este documento somente se aplica a ferramentas RAID ANTIGAS, versão 0.50 e inferiores. Os detalhes contidos neste documento se tornaram obsoletos com a vasta melhoria das ferramentas RAID 0.90 e acompanhadas do patch nos kernels das séries 2.0.37, 2.2x e 2.3x.
SCSI-Programming-HOWTO
Este documento fala sobre a programação da interface SCSI genérica no GNU/Linux.
UMSDOS-HOWTO
O UMSDOS é um sistema de arquivos GNU/Linux. Ele oferece uma alternativa do sistema de arquivos EXT2. Sua maior característica é a coexistência com os dados DOS existentes, compartilhando a mesma partição.
Oferece dicas para editar arquivos desta linguagem e com sintaxe similar como C e Java.
Emacs-Beginner-HOWTO
Este documento introduz os usuários GNU/Linux no editor Emacs. Ele assume o mínimo de conhecimento com o editor de texto vi ou similar.
Emacspeak-HOWTO
Este documento descreve como um usuário pode usar o sistema com um sintetizador de voz no lugar do monitor de vídeo. Ele descreve como ter o GNU/Linux rodando em seu PC e como configura-lo para falar. Ele também sugere como aprender sobre o Unix.
HOWTO-HOWTO
Lista de ferramentas, processos e dicas para ajudar os autores de HOWTO's aumentarem sua produtividade.
LinuxDoc Emacs Ispell-HOWTO
Este documento é de interesse de escritores e tradutores dos HOWTO's do GNU/Linux ou qualquer outro papel para o Projeto de Documentação do GNU/Linux. Ele oferece dicas sobre o uso de ferramentas incluindo o Emacs e Ispell.
TeTeX-HOWTO
Este documento cobre a instalação básico e uso das implementações TeTeX, TeX e LaTeX sob as maiores distribuições de GNU/Linux Inglesas e pacotes auxiliares como o GhostScript.
Vim-HOWTO
Este documento é uma guia para configurar rapidamente o editor colorido Vim nos sistemas Unix e GNU/Linux. Os detalhes aqui aumentarão a produtividade dos programadores porque o editor Vim suporta a colorização de código e fontes negrito, aumentando a "legibilidade" do código do programa. A produtividade do programador aumenta de 2 a 3 vezes com um editor colorido como Vim.
Este documento descreve o suporte do GNU/Linux aos chips aceleradores 3Dfx. Também lista alguns hardwares suportados, descreve como configurar os drivers e responde perguntas frequêntes.
4mb-Laptops
Como instalar o Linux em um notebook com 4MB de RAM e com HDs menores que 200 MB.
Acer Laptop-HOWTO
Descreve como instalar o Linux em notebooks Acer.
Busmouse-HOWTO
Descreve como instalar, configurar e usar um barramento de mouse sob o GNU/Linux. Ele contém uma lista de barramentos suportados e tenta responder as questões mais frequêntes relacionadas ao assunto.
CDServer-HOWTO
Oferece as dicas e passos para criar um servidor de CD no Linux para serem compartilhados via rede com Windows e outros sistemas operacionais.
CPU-Design-HOWTO
Oferece referências para mostrar como uma CPU é projetada e fabricada. Bastante interessante para estudantes de computação e outros profissionais da área.
Ftape-HOWTO
Este HOWTO discute o controlador de unidades tape para GNU/Linux.
HP-HOWTO
Este documento descreve o uso dos produtos disponíveis no catálogo Hewlett-Packard (HP) com o GNU/Linux e alguns programas free software. Ele explica o estado do suporte para hardwares, softwares utilizados e respostas para alguns questões frequêntes.
Hardware-HOWTO
Este documento lista a maioria dos hardware suportados pelo GNU/Linux e lhe ajuda a localizar os controladores necessários.
Jaz-Drive-HOWTO
Este HOWTO cobre a configuração e uso dos drivers Iomega 1Gb e 2Gb sob o GNU/Linux.
Kodak-Digitalcam-HOWTO
Fazendo uma câmera Kodak digital funcionar sob GNU/GNU/Linux.
Laptop-HOWTO
Os Notebooks são diferentes de computadores desktops/torres. Eles usam certos hardwares como cartões PCMCIA, portas infravermelho, baterias, estações de encaixe. Frequentemente seus hardwares são mais limitados (i.e. espaço em disco, velocidade da CPU) então sua performance se torna menor. Em algumas instâncias, os notebooks podem se tornar uma substituição ao sistema desktop. O suporte de hardware para o GNU/Linux (e outros sistemas operacionais) é algumas vezes mais limitado (i.e. chips gráficos, modens internos). Os Notebooks frequentemente utilizam hardware especializado, no qual a localização de um controlador adequado pode se tornar uma dificuldade. Os Notebooks são utilizados em ambientes móveis, assim existe a necessidade de múltiplas configurações e estratégias adicionais de segurança.
Modem-HOWTO
Ajuda com a seleção, conexão, configuração, resolução de problemas e compreensão de modens de um PC. Veja o Serial-HOWTO para detalhes sobre múltiplas placas seriais.
PCI-HOWTO
Informações sobre o que funciona com o GNU/Linux e placas PCI e que o não funciona.
Plug-and-Play-HOWTO
Este documento ajuda a compreensão e operação do Plug-and-Play e como incluir o suporte do seu sistema GNU/Linux ao Plug-and-Play.
Serial-HOWTO
Este documento descreve características da porta serial ao invés de outros detalhes que devem ser cobertos pelos documentos Modem-HOWTO, PPP-HOWTO, Serial-Programming-HOWTO, ou Text-Terminal-HOWTO. Ele lista detalhes sobre múltiplas placas seriais contendo informações técnicas detalhadas sobre a própria porta serial em mais detalhes do que os encontrados nos HOWTO's acima e deve ser o suficiente para correção de problemas quando o problema é a própria porta serial. Se estiver trabalhando com um Modem, PPP (usado para acesso a Internet através de uma Linha telefônica), ou um Terminal baseado em modo texto, seus respectivos HOWTO's devem ser primeiramente consultados.
Serial-Programming-HOWTO
Explica como programar comunicações com dispositivos através de uma porta serial em um computador com o GNU/Linux.
UPS-HOWTO
Este documento te ajudará a conectar um uninterruptable power supply (No Break) em seu computador GNU/Linux... se tiver a sorte de possuir um...
Wacom-Tablet-HOWTO
Instalação do (não somente) Wacom graphic tablets sob o GNU/Linux e / ou xfree86.
Wearable-HOWTO
Computação móvel com GNU/Linux.
Winmodems-and-Linux-HOWTO
Este documento contém detalhes sobre a configuração de Winmodems no GNU/Linux.
Este howto contém informações primárias sobre, e links para, várias bibliotecas relacionadas com o AI, aplicativos, etc. que funcionam na plataforma GNU/Linux. Todos eles (pelo menos) livres para uso pessoal.
Apache-Overview-HOWTO
Oferece uma visão do servidor Web Apache e projetos relacionados.
Commercial-HOWTO
Este documento contém uma listagem de programas comerciais e aplicações que são oferecidas para o GNU/Linux
Glibc2-HOWTO
Este documento cobre a instalação e uso da Biblioteca GNU C versão 2 nos sistemas GNU/Linux.
RPM-HOWTO
Explica como utilizar o sistema de gerenciamento de pacotes RPM.
Program-Library-HOWTO
Este documento para programadores discute como criar e usar bibliotecas no GNU/Linux. Estas incluem bibliotecas estáticas, bibliotecas compartilhadas e bibliotecas carregadas dinamicamente.
Secure-Programs-HOWTO
Este documento oferece um conjunto de designs e regras de implementação para escrever programas seguros para os sistemas Unix e Linux. Tais programas incluem programas aplicativos usados para visualizadores de dados remotos, scripts CGI, servidores de rede, programas setuid/setgid. Guias específicos sobre C, C , Java, Perl, Python, e Ada95 estão incluídos.
Software-RAID-0.4x-HOWTO
RAID significa "Redundant Array of Inexpensive Disks", e significa ser um método de criar um rápido e confiável subsistema de unidades de disco ao invés de discos individuais. O RAID pode se prevenir de falhas de disco e pode também aumentar a performance obtida através de uma simples unidade de disco. Este documento é um tutorial/HOWTO/FAQ para usuários do kernel do Linux com extensões MD, as ferramentas associadas, e seu uso. A extensão MD implementa o RAID-0 (striping), RAID-1 (mirroring), RAID-4 e RAID-5 no software. O que significa que, com MD, nenhum hardware especial ou controladoras de disco são requeridas para obter muitos dos benefícios do RAID.
Software-RAID-HOWTO
Este documento descreve como usar o software RAID sob o GNU/Linux. Ele endereça uma versão específica da camada de software do RAID, nomeada camada RAID 0.90, feita por Ingo Molnar e outros. Esta é a camada RAID que será padronizada no Linux-2.4, e também é a versão usada por kernels 2.2 do GNU/Linux vendidos por alguns vendedores. O suporte RAID 0.90 está disponível com patches para os kernels do 2.0 e 2.2 do GNU/Linux e também é considerado ser mais estável que o antigo suporte RAID já incluído nestes kernels.
Software-Release-Practice-HOWTO
Este documento descreve boas práticas de lançamento para o projeto de código-aberto GNU/Linux. Seguindo estas práticas, será fácil e possível para os usuários construir seu código e usa-lo, e para outros desenvolvedores entender seu código e cooperar com você para melhora-lo. Este documento deve ser lido por desenvolvedores iniciantes. Desenvolvedores experientes devem revisa-lo quando desejarem lançar um novo projeto. Este documento é revisado periodicamente para refletir a evolução das boas práticas de lançamento.
Este documento é uma visão rápida das CPUs Alpha, chipsets e sistemas existentes.
MILO-HOWTO
Este documento descreve o MIniLOader, um programa para sistemas baseados na arquitetura Alpha que pode ser usado para inicializar a máquina e carregar o GNU/Linux. O Linux Miniloader do Alpha (seu nome completo) é também conhecido como MILO.
MIPS-HOWTO
Esta FAQ descreve o porte do MIPS para o sistema operacional Linux, problemas comuns e suas soluções, disponibilidade e mais. Ele também tenta ser um pouco útil a outras pessoas que desejam ler esta FAQ em uma tentativa de encontrar informações que atualmente seriam cobertas em outro lugar.
SRM-HOWTO
Este documento descreve como inicializar no Linux/Alpha usando o console SRM, que é a firmware de console também usada para inicializar o Unix Compaq Tru64 (também conhecido com Digital Unix e OSF/1) e OpenVMS.
Este documento descreve como programar em linguagem Assembler usando ferramentas de programação livres, focalizando-se no desenvolvimento para ou do Sistema Operacional GNU/Linux, mais na plataforma IA-32 (i386).
Bash-Prog-Intro-HOWTO
Este documento tem a intenção de te ajudar a iniciar na programação de shell scripts. Ele não tem a intenção de ser uma documento avançado.
C Programming-HOWTO
Discute os métodos para evitar problemas de memória no C e também te ajudará a programar corretamente na linguagem C . As informações contidas neste documento se aplicam a todos os sistemas operacionais que são GNU/Linux, DOS, BeOS, Apple Macintosh OS, Windows 95/98/NT/2000, OS/2, Sistemas IBM (MVS, AS/400, etc...), VAX VMS, Novell Netware, todos os tipos de Unix como o Solaris, HPUX, AIX, SCO, Sinix, BSD, etc., e todos os outros sistemas operacionais que suportam o compilador "C " (quase todos os sistemas operacionais deste planeta!).
C-C Beautifier-HOWTO
Este documento ajudará a formatar (de forma organizada) os programas C/C assim será mais legível e seguirá os padrões de codificação C/C . As informações deste documento se aplica a quase todos os sistemas operacionais do planeta!
DB2-HOWTO
Este documento explica como instalar o DB2 Universal Database versão 7.1 para GNU/Linux nas seguintes distribuições baseadas no Intel x86: Caldera Caldera OpenLinux 2.4, Debian, Red Hat Linux 6.2, SuSE Linux 6.2 e 6.3, e TurboLinux 6.0. Após instalar o DB2, você pode usar um banco de dados de exemplo, conectar-se ao servidor DB2 de uma máquina remota e administrar o DB2 usando o DB2 Control Center.
Enterprise-Java-for-Linux-HOWTO
Como configurar um ambiente Java Enterprise no GNU/Linux incluindo o Java Development Kit, um servidor Web, suportando Java servlets, acessando um banco de dados via JDBC e suportado Enterprise Java Beans (EJBs).
GCC-HOWTO
Este documento explica como configurar o compilador GNU C e bibliotecas de desenvolvimento sob o GNU/Linux e te dá uma visão de compilação, linkagem, execução e programas de depuração.
IngresII-HOWTO
Este documento cobre a instalação do Ingres II Relational Database management System no GNU/Linux. Ele cobre a configuração de ambos o Kit de desenvolvimento e versão completa do Ingres. Algumas seções explicam como iniciar o uso do Ingres.
Oracle-7-HOWTO
Um guia para instalar e configurar o Servidor do Banco de Dados Oracle em um sistema GNU/Linux.
Oracle-8-HOWTO
Com este HOWTO, é um pouco de sorte, você será capaz de ter o Oracle 8i Enterprise Edition para GNU/Linux instalado, criar um banco de dados e conectar a ele através de um computador remoto. O foco principal deste guia é o RedHat 6.0, no entanto ele pode funcionar em outros distribuições recentes após algumas modificações.
PHP-HOWTO
Ensina como desenvolver programas em PHP e também migrar todas as aplicações GUI do Windows 95 para o poderoso conjunto PHP HTML DHTML XML Applets Java Javascript. As explicações descritas neste documento se aplicam a todo os sistemas operacionais para onde o PHP está portado que são: Linux, Windows 95/98/NT/2000, OS/2, todos os tipos de Unix como o Solaris, HPUX, AIX, SCO, Sinix, BSD, etc...
PostgreSQL-HOWTO
Este documento é um "guia prático" para rapidamente colocar para funcionar um banco de dados SQL e suas ferramentas de comunicação em um sistema Unix. Ele também discute a linguagem padrão Internacional ANSI/ISO SQL e revisa os méritos/vantagens do SQL Database engine desenvolvido pela Internet ao redor do mundo em um ambiente de desenvolvimento aberto. Também como configurar a próxima geração do banco de dados relacional a objetos SQL "PostgreSQL" em um sistema Unix que pode ser usado como um Servidor de Aplicativos de banco de dados ou como um Servidor de banco de dados Web.
TclTk-HOWTO
Este documento descreve o uso do Tcl no GNU/Linux, uma linguagem de scripting. Ela é uma linguagem interpretada fácil de aprender que usa pouca digitação para obter um alto nível de programação e desenvolvimento rápido de aplicativos (RAD). O Tk toolkit é um ambiente de programação para criar interfaces gráficas do usuário (GUI) sob o Sistema X Window. Suas capacidades incluem a possibilidade de estender e incluir em outros aplicativos, desenvolvimento rápido e fácil de usar. Juntos o Tcl e Tk oferecem muitos benefícios para o desenvolvedor e usuário. As interfaces baseadas no Tk tendem a ser mais personalizáveis e dinâmicas que aquelas feitas de toolkits C ou C . O Tk implementa o Visual e Uso do Motif. Um grande número de aplicações X interessantes são implementadas completamente em Tk, com nenhum comandos específicos de aplicativo.
Este documento é uma introdução a arquitetura de Supercomputador Beowulf e oferece informações sobre programação paralela, incluindo links para documentos mais específicos e páginas internet.
Cluster-HOWTO
Como configurar clusters de computador GNU/Linux de alta performance.
Parallel-Processing-HOWTO
O Processamento Paralelo é uma forma de acelerar a execução de um programa dividindo o programa em múltiplos fragmentos que podem ser executados simultaneamente, cada um em seu próprio processador. Um programa sendo executado em N processadores pode ser executado N vezes mais rápido que seria usando somente um processador. Este documento discute os quatro métodos para realizar processamento paralelo que estão disponíveis aos usuários do sistema operacional GNU/Linux: Sistemas Linux SMP, Sistemas Linux em Clusters de rede, execução paralela usando as instruções multimídia do processador (i.e. MMX) e processadores (paralelos) conectados no sistema GNU/Linux.
SMP-HOWTO
Este HOWTO revisa principais assuntos (e eu espero que soluções) relacionadas com as configurações SMP sob o GNU/Linux.
Como usar e configurar corretamente tipos de fontes no ambiente GNU/Linux.
Framebuffer-HOWTO
Descreve como utilizar dispositivos framebuffer no GNU/Linux com uma variedade de plataformas. Isto também inclui como ajustar telas multi-headed.
Keyboard-and-Console-HOWTO
Este documento contém algumas informações sobre o teclado e console no GNU/Linux, e o uso de caracteres não-ASCII. Ele descreve o GNU/Linux 2.0.
Text-Terminal-HOWTO
Explica o que são os terminais texto, como funcionam, como instalar e configura-los e oferece muitos detalhes de como conserta-los. Se não tiver um manual do terminal, poderá ser de grande ajuda. Enquanto é escrito para terminais reais no sistema GNU/Linux alguns deles também são aplicáveis a emulação de terminal e pode ser útil para sistemas não Linux.
Unicode-HOWTO
Explica como alterar seu sistema GNU/Linux para utilizar a codificação de texto baseada no UTF-8. -
O MGR (ManaGeR) é um sistema de janelas gráfico. O servidor MGR oferece um gerenciador de janelas embutido e emulação de terminal gráfico em janela em monitor colorido ou monocromático. O MGR é controlado por menus pop-up, por interação do teclado e por sequencias de escapa escrita em pseudo-terminais pelo software cliente.
XFree86-HOWTO
Este documento descreve como obter, instalar e configurar a versão 4.0 do XFree86 do X Window System (X11R6) para sistemas GNU/Linux. Ele é um guia passo a passo para configurar o XFree86 em seu sistema.
XFree86-Touch-Screen-HOWTO
Descreve como configurar um dispositivo de entrada touch screen sob o XFree86.
XFree86-Video-Timings-HOWTO
Como configurar os modos de vídeo de sua placa/monitor sob o XFree86.
XWindow-User-HOWTO
Este documento contém detalhes sobre a configuração do ambiente X Windows para o usuário GNU/Linux, também como o administrador de sistemas iniciantes tentando aprender os mais diversos tipos de opções de configuração e detalhes do X Window. É assumido um conhecimento básico de configurações de software e instalação.
Xinerama-HOWTO
Este documento descreve como configurar o XFree86 versão 4.0 com monitores multimídia com as extensões Xinerama.
Suporte ao Sistema / Grupos de Usuários / Listas de Discussão
Contém uma lista de empresas e consultores oferecendo suporte comercial relacionado ao sistema GNU/Linux.
Online-Troubleshooting-HOWTO
Este documento direciona usuários GNU/Linux a lugares disponíveis na Internet que oferecem acesso a uma vasta quantidade de documentos úteis relacionados ao sistema em situações de problema.
User-Group-HOWTO
Este documento descreve como fundar, manter e organizar um grupo de usuários GNU/Linux.
Este documento tem a intenção de ajudar o leitor traduzir seu conhecimento do DOS e Windows para o ambiente GNU/Linux, também como oferecer dicas de manipulação de arquivos e utilização de recursos entre os dois sistemas.
VMS-to-Linux-HOWTO
Este documento é escrito para todos aqueles que tem usado o VMS e agora precisam migrar para o GNU/Linux um clone gratuito do UNIX. A transição é feita (felizmente) através de uma comparação passo a passo de comandos e ferramentas existentes.
Este documento compartilha dicas e recursos para utilizar soluções do GNU/Linux no mundo da Astronomia.
CD-Writing-HOWTO
Este documento explica como gravar CD-ROMs sob o GNU/Linux.
CDROM-HOWTO
Este documento descreve como instalar, configurar e usar uma unidade de CD-ROM sob o GNU/Linux. Ele lista hardwares suportados e responde a um número de questões frequêntes.
CVS-RCS-HOWTO
Este documento é um guia prático para rapidamente configurar o sistema de controle do código fonte CVS/RCS. Este documento também possui shell scripts personalizados que são trocados no topo do CVS. Estes scripts oferecem uma interface fácil entre o usuário e o CVS.
DVD-Playing-HOWTO
Uma explicação fácil de seguir de como obter seu DVD funcionando no GNU/Linux.
Diskless-HOWTO
Este documento descreve como configurar uma máquina sem disco rígido no GNU/Linux.
Java-Decompiler-HOWTO
Este documento te ajudará a descompilar programas class feitos em Java. Este documento contém uma lista de descompiladores que podem reverter o engineer os arquivos Java class e gerar arquivos de código fonte Java. Isto é muito útil se você não tem o arquivo com o código fonte Java.
JavaStation-HOWTO
Este HOWTO descreve como ativar o SO GNU/Linux no NC Sun Java Station.
KickStart-HOWTO
Este documento descreve como usar o sistema Linux RedHat para instalar rapidamente o sistema em um grande número de máquinas GNU/Linux.
Kiosk-HOWTO
Este documento oferece um guia para ajustar um kiosk baseado em WWW usando o GNU/Linux, X11R6, FVWM2, Netscape Navigator 4.X e um trackball customizado.
Linux-From-Scratch-HOWTO
Este documento descreve o processo de criar seu próprio sistema GNU/Linux do nada através de uma distribuição já instalada, usando nada mais que o código fonte dos softwares que precisamos.
MP3-HOWTO
Este documento descreve o hardware, software e processos necessários, para encodificar, tocar, mixar e decodificar arquivos de som MP3 sob o GNU/Linux.
Majordomo-MajorCool-HOWTO
Este documento tem a intenção de guiar o usuário através do software de gerenciamento de listas de discussão Majordomo e MajorCool. O MajorCool é um utilitário para gerenciar listas Majordomo via script CGI; muitas pessoas que não estão familiar com o Majordomo baseado em modo texto podem preferir uma interface mais amigável via web do MajorCool.
Mutt-GnuPG-PGP-HOWTO
Este documento explica como configurar rapidamente o Mutt-i, PGP e GnuPG em suas diferentes versões (2.6.x, 5.x e GnuPG), nada dos problemas que podem ocorrer enquanto envia e-mails criptografados e assinados para ser lidos por clientes de e-mail que não são compatíveis com PGP/MIME como definido na RFC 2015 e em outros sistemas operacionais.
NC-HOWTO
Este documento tenta descrever como colocar uma Netstation da IBM em sua rede local usando um computador GNU/Linux como servidor.
NCD-HOWTO
Este documento tenta descreve como colocar uma ThinSTAR NCD em sua rede local usando um computador GNU/Linux como servidor.
PalmOS-HOWTO
Este documento explica como usar seu dispositivo Palm OS com um sistema GNU/Linux. Este HOWTO não aborda somente o sistema operacional GNU/Linux.
Printing-HOWTO
Este é o Printing HOWTO do GNU/Linux, uma coleção de informações sobre como gerar, ver, imprimir e enviar fax de tudo sob o GNU/Linux (e outros UNIXes em geral).
Printing-Usage-HOWTO
Descreve como usar o sistema de spooling oferecido pelo sistema operacional GNU/Linux. Este HOWTO é um documento suplementar ao Linux Printing Setup, que discute a instalação e configuração do sistema de impressão do GNU/Linux.
Psion-HOWTO
Este documento descreve como usar Palmtops Psion com o GNU/Linux, mas não cobre a execução do Linux no Palmtop Psion. Veja o projeto Linux 7k em http://www.calcaria.net.
Quake-HOWTO
Este documento explica como instalar, executar e corrigir problemas no Quake, QuakeWorld e Quake II em um sistema GNU/Linux Intel.
RedHat-CD-HOWTO
Descreve como fazer seus próprios CDs da distribuição Red Hat, a estrutura da distribuição e também como incluir RPMs atualizados na distribuição.
Sound-HOWTO
Este documento descreve o suporte ao som no GNU/Linux, arquiteturas de som suportadas e como incluir o suporte ao som no kernel. Este documento também responde algumas questões frequêntes sobre o suporte ao som no GNU/Linux.
Sound-Playing-HOWTO
Este documento lista aplicativos que podem tocar vários formatos de sons no GNU/Linux.
VME-HOWTO
Este documento mostra como executar o GNU/Linux em seu Pentium VMEbus e outros barramentos PCI baseados no design de processador VMEbus.
Talvez o GNU/Linux seja o único sistema operacional no mundo que possui suporte nativo e padrão ao protocolo de pacotes de rádio AX.25 usado por Operadores de Rádio Amador ao redor do mundo. Este documento explica como instalar e configurar este suporte.
Adv-Routing-HOWTO
Roteamento avançado. Explicações sobre o iproute2, traffic shaper e netfilter.
Bandwidth-Limiting-HOWTO
Descreve como configurar o servidor Linux para limitar banda.
BRIDGE-STP-HOWTO
Este documento explica o que é uma ponte entre redes e como criar uma utilizando o Spanning Tree Protocol (STP). Este é um método de manter os dispositivos Ethernet conectados e funcionando em múltiplos caminhos. Os participantes negociam a troca através do caminho mais curto através do STP.
Cable-Modem
Fornece instruções de como usar o Linux para se conectar a um provedor de Cable modem.
Chroot-BIND8-HOWTO
Este documento descreve a instalação do servidor de nomes BIND 8 para ser executado em uma jaula chroot e como um usuário não-root, para oferecer segurança adicional e minimizar efeitos potenciais que podem comprometer a segurança.
Cyrus-IMAP
Um guia compreensivo para a instalação, configuração e execução do Cyrus Imap e Cyrus SASL.
DNS-HOWTO
Como configurar seu servidor DNS em pouco tempo.
Diald-HOWTO
Este documento mostra alguns cenários típicos para iniciar o uso do Diald facilmente. Este cenários incluem uma conexão de um computador local a um provedor usando o PPP através de um modem sem usar o pon/poff ou ppp-pon/ppp-off para um servidor proxy/firewall com diferentes conexões Internet através de vários provedores.
Diskless-root-NFS-HOWTO
Explica como configurar um servidor e clientes para operação sem disco através de uma rede.
DSL-HOWTO
Este documento examina a família DSL de serviços Internet de alta velocidade. Descreve como instalar, configurar depurar.
Ethernet-HOWTO
Este documento é uma coleção de dados sobre dispositivos Ethernet que podem ser usados no GNU/Linux e como configura-los. Note que este HOWTO está focalizado no hardware e aspectos de baixo nível de controladores das placas ethernet e não cobre assuntos de software como os programas ifconfig e route (veja o Network-HOWTO se procura por estes materiais).
Firewall-HOWTO
Descreve os sistemas básicos de firewall e alguns detalhes de como ajustar firewalls proxy e de filtragem de pacotes em sistemas baseados no GNU/Linux.
IP-Masquerade-HOWTO
Este documento descreve como ativar a característica IP Masquerade no GNU/Linux. O IP Masquerade é uma forma do Network Address Translation ou NAT que permite que computadores conectados internamente que não tem um ou mais endereços Internet registrados ter a habilidade de se comunicar com a Internet via uma única máquina GNU/Linux com um único endereço IP.
IPCHAINS-HOWTO
Descreve como obter, instalar e configurar o programa avançado de firewall para o GNU/Linux e algumas idéia de como usa-lo.
IPX-HOWTO
Descreve como obter, instalar e configurar as várias ferramentas disponíveis para o sistema operacional GNU/Linux para utilizar o suporte do protocolo IPX no kernel do GNU/Linux.
Infrared-HOWTO
Uma introdução ao GNU/Linux e dispositivos infra-vermelho e como usar programas oferecidos pelo projeto Linux/IrDA.
ISP-Hookup-HOWTO
Descreve como usar o GNU/Linux para conectar a um Provedor Internet via modem dial-up via conexão TCP/IP. Também como o procedimento de discagem inicial e estabelecimento de IP, recebimento de email e news.
ISP-Setup-RedHat-HOWTO
Descreve como configurar serviços de ISP no Red Hat. Domínios, virtual hosts, pop3 e emails.
Intranet-Server-HOWTO
Este documento descreve como configurar uma Intranet usando o GNU/Linux como um servidor que se comunica com Unix, Netware, NT e Windows.
Java-CGI-HOWTO
Este documento explica como configurar seu servidor para permitir programas CGI escritos em Java e como usar Java para escrever programas CGI.
LDAP-HOWTO
Informações sobre a instalação, configuração, execução e manutenção de um Servidor LDAP (Lightweight Directory Access Protocol) em uma máquina GNU/Linux é descrita neste documento. Existe também detalhes sobre como criar bancos de dados LDAP, como atualizar e apagar informações no banco de dados, como implementar roaming access e como usar o Livro de Endereços do Netscape.
LDAP-Implementation-HOWTO
Descreve aspectos técnicos de armazenamento de dados de aplicações em um servidor LDAP.
Mail-Administrator-HOWTO
Este documento descreve a configuração e uso do Correio Eletrônico (E-mail) sob o GNU/Linux. É primariamente mais indicado para administradores do que usuários.
Mail-User-HOWTO
Este documento é uma introdução ao mundo do Correio Eletrônico sob o GNU/Linux
Masquerading-Simple-HOWTO
Descreve de forma prática como conectar diversas máquinas de sua rede Interna a Internet.
MindTerm-SSH-HOWTO
Este documento descreve como usar o SSH o programa MindTerm baseado em Java para criar de forma rápida, segura e confiável uma VPN sobre redes inseguras.
Multicast-HOWTO
Este HOWTO tenta cobrir muitos aspectos relacionados com o multicast sobre redes TCP/IP. Assim, muitas informações que não são específicas do sistema Linux (apenas no caso de não usar o GNU/Linux... ainda).
NFS-HOWTO
Como configurar servidores e clientes NFS>
NetMeeting-HOWTO
Descreve como fazer o Microsoft NetMeeting se integrar com o Linux.
NIS-HOWTO
Este documento descreve como configurar o GNU/Linux como um cliente NIS (YS) ou NIS e como instala-lo como um servidor NIS.
Network-boot-HOWTO
Descreve como configurar um servidor Linux para permitir que estações sem disco rígido façam boot via rede e iniciem o sistema Linux (é uma regravação parcial do Diskless-howto).
Net-HOWTO
Este documento cobre as área de software e tecnologias de rede no GNU/Linux.
Networking-Overview-HOWTO
O propósito deste documento é lhe oferecer uma visão das capacidades de rede do sistema operacional GNU/Linux e oferecer ponteiros para outros documentos e detalhes de implementação.
PPP-HOWTO
Este documento mostra como conectar seu PC GNU/Linux a um servidor PPP (Protocolo Ponto a Ponto), como usar o PPP para ligar duas redes e oferece um método de configurar seu computador GNU/Linux como um servidor PPP. Este documento também oferece ajuda na solução de problemas relacionados com o PPP.
Qmail-VMailMgr-Courier-imap-HOWTO
Este documento é sobre a construção de um servidor de e-mail que suportará hospedagem de domínios dinâmicos e oferecerá os serviços smtp, pop3 e imap, usando uma poderosa alternativa ao sendmail.
Remote-Serial-Console-HOWTO
A porta RS232 permite que o Linux ser controlado de um terminal ou modem conectado a uma porta serial assíncrona. Este documento descreve como configurar o Linux para se conectar ao console serial.
Sat-HOWTO
Descreve base e referências sober a tecnologia SAP, as características de larga banda para download, etc.
Serial-Laplink-HOWTO
Descreve como criar uma conexão serial entre dois computadores para compartilhamento de dados. Este permite também efetuar conexões seriais entre outros tipos de sistemas operacionais como Windows 9X, NT.
SMB-HOWTO
Este é o HOWTO SMB. Ele descreve como usar o protocolo Server Message Block (SMB), também chamado de Session Message Block, NetBIOS ou protocolo LanManager, com o GNU/Linux e usando o Samba.
Securing-Domain-HOWTO
Este documento descreve as coisas que provavelmente deve fazer quando desejar configurar uma rede de computadores sob seu próprio domínio. Ele cobre a configuração de parâmetros de rede, serviços de rede e configurações de segurança.
Security-HOWTO
Este documento é uma visão geral dos assuntos de segurança que enfrente o administrador de sistemas GNU/Linux Ele cobre a filosofia geral de segurança e um número de exemplos específicos de como melhorar a segurança de seu sistema GNU/Linux Também estão incluídos ponteiros para materiais relacionados com programas e segurança.
Shadow-Password-HOWTO
Este documento tenta descrever como obter, instalar e configurar o Linux password Shadow Suite. Também discute como obter e reinstalar outros softwares e daemons de rede que requerem acesso as senhas do usuário.
SSL-RedHat-HOWTO
Fornece referências sobre como o PKI e SSL funcionam juntos
Tango-HOWTO
Descreve a instalação, configuração e correção de problemas básicos do Pervasive Software's Tango Application Server no Sun Solaris e vários sabores de GNU/Linux.
Thinclient-HOWTO
Como converter computadores comuns em rápidos terminais usando o poder de seu computador principal, você precisará de: Um computador rápido para atuar como servidor, um computador cliente (antigo e não desejado). Placas de rede compatíveis com o GNU/Linux. Uma conexão entre os computadores. Como centralizar a administração do sistema usando o NFS (i.e. colocando todo o sistema de arquivos de um cliente rápido no servidor).
UUCP-HOWTO
Este documento descreve a configuração do UUCP sob o GNU/Linux. Você deve ler este documento se planejar conectar a sites remotos via UUCP via modem, conexão direta ou via Internet. Provavelmente não precisará ler este documento se não souber o que é UUCP ou se seu computador não possuir este suporte.
VMailMgr-HOWTO
Explica como configurar o suporte ao VMailMgr serviços de domínio virtual pop3 em conjunto com o Qmail.
VoIP-HOWTO
Ensina como configurar o sistema Linux para comunicação via voz usando a Internet. Descreve protocolos e métodos para transmissão de voz aproveitando recursos de redes de baixa velocidade.
VPN-HOWTO
Descreve como configurar uma Virtual Private Network com o GNU/Linux.
VPN-Masquerade-HOWTO
Descreve como configurar um Firewall GNU/Linux para o masquerade em tráfego baseado no IPsec- e PPTP Virtual Private Network Traffic, permitindo estabelecer uma conexão VPN sem perder a segurança e flexibilidade de sua conexão Internet com o firewall GNU/Linux e permitindo fazer um servidor VPN disponível que não possui um endereço IP registrado na Internet. Também estão incluídos detalhes de como configurar um cliente e servidor VPN.
Virtual-Services-HOWTO
Este documento fala sobre tudo que precisa saber para virtualizar um serviço.
Windows-LAN-Server-HOWTO
Ajuda na configuração do Linux em ambientes onde existiam primariamente máquinas executando o Windows 9x.
Wireless-HOWTO
Explica como como configurar uma rede sem fio em ambiente Linux, limitações, requerimentos, etc.
WWW-HOWTO
Explica como configurar serviços WWW sob o GNU/Linux (ambos cliente e servidor). Ele não tenta ser um manual detalhada mas uma visão e um bom ponto de referência.
WWW-mSQL-HOWTO
Descreve como construir um banco de dados cliente/servidor usando a WWW e HTML para a interface com o usuário.
phhttpd-HOWTO
O phttpd é um acelerador HTTP. Ele serve uma rápida requisição estática HTTP através de um sistema de arquivos locai e passa as requisições menos dinâmicas para um servidor de espera. Suas características são uma compreensão do I/O e um cache de conteúdo agressivo que o ajuda a fazer um trabalho eficiente.
Este documento discute assuntos relacionados ao desempenho dos sistemas Linux e recomenda algumas ferramentas para medida do desempenho do sistema.
DOSEMU-HOWTO
Ensina como utilizar, configurar o emulador do ambiente DOS para Linux.
Ecology-HOWTO
Este documento discute métodos de como os computadores com o GNU/Linux podem ser usados para proteger nosso ambiente, usando características como economia de energia ou papel. Como ele não requer grandes requerimentos de hardware, o GNU/Linux pode ser usado com computadores antigos e tornar seu ciclo de vida longo. Os jogos podem ser usados em ambientes educativos e estão disponíveis programas para simular os processos ecológicos.
Process-Monitor-HOWTO
Este documento descreve como monitorar os processos (programas) no Linux/Unix e como reinicia-los automaticamente se eles são destruídos sem intervenção manual. Este documento também tem URLs para FAQs sobre "Processos no Unix".
VAR-HOWTO
Contém uma lista de empresas de serviço que não fabricam hardwares ou criam pacotes de softwares, mas incluem valores ao produtos existentes.
Descreve a instalação dos controladores de som ALSA para Linux. Estes controladores de som podem ser usados em substituição aos controladores de com regular, como são totalmente compatíveis.
Install-From-ZIP
Descreve como instalar o GNU/Linux através de um zip drive conectado a porta paralela usando a distribuição Slackware do GNU/Linux.
Install-Strategies
Descreve algumas formas de instalação para aqueles que tem a intenção de fazer dual boot entre o Linux e Windows.
Lego
Mostra soluções em software livre para utilização com os kits de robótica da The Lego Group's Mindstorm Robotics Invention System (RIS).
Kerneld
Explica como configurar e utilizar o daemon kerneld.
Loadlin Win95
Este documento descreve como usar o Loadlin com o Windows 95 para inicializar o GNU/Linux.
Modules
Explica como incluir seu suporte no kernel, configurar e utilizar módulos no GNU/Linux.
Path
Descreve truques comuns e problemas com as variáveis de ambiente no GNU/Linux/Unix, especialmente a variável PATH. PATH é uma lista de diretórios onde os comandos são pesquisados. Os detalhes se aplicam a distribuição Debian 1.3.
Pre-Installation-Checklist
Você é um novato no Linux? Você é um guru no Linux? Em ambos os casos esta checklist será de grande ajuda para você. Quantas vezes você se encontrou com problemas no meio de um processo de instalação do GNU/Linux porque algum detalhe vital sobre o hardware alvo não é conhecido?
Post-Installation-Checklist
Lembra alguns passos que devem ser verificados logo após a instalação de um novo sistema Linux.
RPM Slackware
Este documento descreve como ter o RPM instalado e funcionando corretamente sob o Slackware.
Update
Descreve como se manter atualizado sobre o desenvolvimento no mundo GNU/Linux.
Upgrade
Dicas e truques de como atualizar de uma distribuição GNU/Linux para outra.
VAIO Linux
Explica a instalação do GNU/Linux em computadores Sony VAIO.
Descreve a montagem automática de sistemas de arquivos autofs, como configura-lo e alguns problemas que devem ser evitados.
Ext2fs-Undeletion
Imagina isto: Você passou os últimos três dias sem dormir, sem comer. Sua compulsão hacker foi paga: você finalizou aquele programa que lhe dará fama e reconhecimento. Todo o que você precisa fazer é coloca-lo no Metalab. Oh, e apagar aqueles arquivos de backup do Emacs. Assim você fadigado digita rm * ~.. E bem mais tarde você notou o espaço extra naquele comando. Você simplesmente apagou todo o seu trabalho! Mas a ajuda está na mão. Este documento oferece uma discussão de como recuperar arquivos apagados através do Second Extend File System (EXT2). Talvez, você será capaz de lançar aquele programa depois disso...
Ext2fs-Undeletion-Dir-Struct
Fornece um complemento ao ext2-undeletion-howto e descreve formas de recuperar estrutura de diretórios de forma segura.
Hard-Disk-Upgrade
Como copiar um sistema GNU/Linux de um disco para outro.
Loopback-Root-FS
Este documento explica como usar o dispositivo de loopback do Linux para criar um formato nativo de sistema de arquivos através de uma partição DOS sem reparticionamento.
Partition-Rescue-mini-HOWTO
Como recuperar uma partição pelo GNU/Linux.
Quota
Descreve como ativar a quota nos sistemas de arquivos para usuários e grupos de uma máquina GNU/Linux.
Swap-Space
Descreve como compartilhar sua partição swap do GNU/Linux com o Windows.
Ultra-DMA
Explica como usar Ultra-DMA como discos rígidos e interfaces Ultra ATA, Ultra 33 e Ultra66 com o GNU/Linux.
ZIP-Drive
Este documente oferece uma referência rápida para a configuração e uso da unidade de ZIP drive Iomega com o GNU/Linux.
Como ter um mouse serial de 3 botões funcionando no GNU/Linux.
ACP-Modem
Descreve como configurar e utilizar a característica ACP (Mwave) de máquinas IBM, como o IBM Thinkpad.
BTTV-Mini-HOWTO-0.3
Este documento descreve o hardware, software e procedimentos necessários para se usar um chipset baseado no bt8x8 frame grabber ou placa sintonizadora de TV sob o GNU/Linux.
Boca
Instalando uma placa serial Boca 16-portas (Boca 2016) no GNU/Linux.
GTEK-BBS-550
Ensina como configurar a placa serial de 8 portas GTEK's BBS-550 com 16C550 UARTS. Somente uma IRQ pode ser usada para todas 8 portas. Ele não requer qualquer controlador no GNU/Linux no entanto o kernel precisa ter o suporte a portas seriais.
Handspring-Visor
Usando o Visor com o GNU/Linux e sua porta USB.
IO-Port-Programming
Este documento descreve a programação de portas I/O de hardware.
Descreve como instalar e usar um cliente para o sistema de backup comercial ADSM para Linux Intel.
Bzip2
Explica como usar o programa de compactação bzip2.
GIS-GRASS
Este documento descreve como adquirir, instalar e configurar o poderoso sistema de informações científicas e geográficas de domínio público (GIS): o Geographic Resources Analysis Support System (GRASS).
LILO
O LILO é o gerenciador de inicialização mais usado na plataforma Intel do Linux. Este documento descreve alguns tipos de instalações do LILO.
Uma breve comparação das maiores linguagens de programação para o GNU/Linux e maiores bibliotecas para para criação de interfaces gráficas com o usuário (GUIs) sob o GNU/Linux.
Oferece detalhes sobre instruções de instalação de um ambiente desktop de renderização e modelamento usando o RedHat Linux.
FDU
Como corrigir fontes feias e ilegíveis no X.
LBX
O LBX (Low Bandwidth X) é uma extensão do servidor X que realiza compressão no protocolo X. Isto significa que pode ser usado em conjunto com aplicativos X e um servidor X que estão separados através de uma conexão de rede de baixa velocidade, para aumentar o tempo de resposta.
Nvidia-OpenGL-Configuration
Ensina como instalar os drivers OpenGL para a placa de vídeo Nvidia.
Remote-X-Apps
Descreve como executar aplicativos X remotos.
TT-XFree86
Ensina como usar fontes true type com o XFree 4.0.x
XDM-Xterm
Ensina como utilizar o XDM para gerenciar terminais X. Uma referência completa do assunto pode ser encontrada no Thin-client HOWTO.
XFree86-Second-Mouse
Instruções de como usar um segundo mouse no X.
X-Big-Cursor
Descreve como usar cursores grandes no X.
XFree86-XInside
Como converte um modeline XFree86 em um XInside/XiGraphics.
Xterm-Title
Explica como usar sequências de escape para alterar dinamicamente os títulos e ícones de janelas de um xterm.
Descreve como usar uma unidade de tape compatível com o GNU/Linux instalado em uma máquina DOS para fazer o backup do sistema de arquivos de uma máquina GNU/Linux.
Battery-Powered
Descreve como reduzir o consumo de energia do sistema GNU/Linux através de alguns ajustes de configuração. Isto será útil para qualquer um quer executar o GNU/Linux em um sistema de computador portátil. Também contém dicas de uso da bateria. Se estiver usando o GNU/Linux em um sistema desktop, você provavelmente não precisará ler todo este documento.
Clock
Como manter o relógio de seu computador na hora.
Coffee
Uma dos mais extremos dos documentos. Eu já pensei se era possível usar o GNU/Linux para fazer café... e descobri que o GNU/Linux faz café!
Por um longo tempo a humanidade estava se perguntando se um computador podia fazer café... As pessoas precisam de café para não dormirem na frente do computador. Todo mundo sabe que é melhor programar de noite...
Divert-Sockets-mini-HOWTO
Descreve como obter, compilar e usar os soquetes divert FreeBSD sob o GNU/Linux 2.2.12.
Home-Electrical-Control
Contém referências para fazer o Linux controlar praticamente qualquer dispositivo elétrico.
Leased-Line
Configurando seu modem e pppd para usar 2 pares de cabos leased line.
Linux-Modem-Sharing
Descreve como configurar o sistema GNU/Linux para compartilhar um modem conectado a este sistema com outros através de uma rede TCP/IP.
Mail2News
Descreve como enviar mensagens de uma lista de discussão para um servidor news.
MP3-CD-Burning
Uma referência completa para a criação de CDs de audio e dados de arquivos MP3.
MSSQL6-Openlink-PHP-ODBC
Ensina como conectar o servidor de banco de dados MS SQL 6.x ou superior via ODBC do PHP3 (e superior) compilado com os drivers Openlink sob o Linux.
NCD-X-Terminal
Descreve como conectar um terminal NCD X a um computador UNIX.
NFS-Root
Este documento tenta explicar como configurar uma estação de trabalho "sem disco" no GNU/Linux, que monta seu sistema de arquivos raíz via NFS.
NFS-Root-Client-mini-HOWTO
O propósito deste documento é explicar como criar um cliente dos diretórios raíz em um servidor que está usando clientes com NFS root montados.
Netscape Proxy
Este documento descreve o processo de configurar uma REDE (INTRANET) em casa. Então configura o NETSCAPE das máquinas dos clientes para acessarem a internet.
News-Leafsite
Este documento ajudará a configuração de um pequeno leafsite para a Usenet News usando o Leadnode do pacote free software.
Offline-Mailing
Explica como usar o sistema de mensagens do GNU/Linux off-line, receber emails para múltiplos usuários somente com uma conta de e-mail, e sem estar 24-24 horas on-line na Internet. Se você não pode pagar uma linha para estar conectado por 24-24 horas e ainda deseja que seus usuários recebem emails em sua máquina Linux; também não pague por uma conta multi-drop em seu provedor, você pode usar este sistema usando somente um endereço de e-mail para dividir seus endereços de e-mails dos usuários.
Outlook-to-Unix-Mailbox
Mostra formas de converter mensagens de email do Microsoft Outlook (exceto do Outlook Express) para formatos de arquivos típicos do Unix.
Pager
Ensina como compilar, instalar e configurar um Gateway de emails para Pager.
Partition
Descreve como criar partições em discos rígidos IDE e SCSI. Também é coberta a recuperação de tabelas de partição perdidas.
Partition-Rescue
Descreve formas para recuperar uma partição de disco apagada.
Process-Accounting
Descreve como ativar a conta de processos em uma máquina GNU/Linux, o uso de vários comandos de contabilização de processos.
RCS
Este documento cobre a instalação e uso básicos do RCS, o GNU Revision Control System sob o GNU/Linux.
Saving-Space
Este documento mostra maneiras de diminuir sua instalação GNU/Linux consumindo o mínimo possível de espaço.
Secure-POP SSH
Este documento explica como usar conexões POP seguras via ssh.
Small-Memory
O propósito deste documento é descrever como executar o GNU/Linux em um sistema com pequena quantidade de memória. Assumindo que a compra de memória esta fora de questão aqui.
Soundblaster-AWE
Descreve como instalar e configurar a placa de som Sound Blaster 32 (SB AWE 32, SB AWE 64) da Creative Labs em um Sistema Linux usando a extensão do driver de som AWE escrito por Takashi Iwai.
StarOffice
Instalando o StarOffice 3.1 da StarDivision no GNU/Linux.
TT-Debian
Descreve como configurar o suporte das fontes True Type na Debian.
TkRat
Este documento foi escrito para qualquer um que tem interesse em usar seu computador GNU/Linux para enviar e receber E-mails pela Internet.
Visual-Bell
Explica como usar o termcap para configurar um aviso visual no sistema ao invés do beep e como desativar o sinal de audio.
Wacom-USB-mini-HOWTO
Descreve como configurar um Wacom Graphire USB tablet para uso no GNU/Linux (console e X), iniciando com a configuração do kernel para o nível da aplicação.
WordPerfect
Discute a execução do WordPerfect no GNU/Linux incluindo uma breve discussão sobre o WordPerfect 7.0.
ZIP-Install
Este documento somente é útil para aqueles que possuem a versão em porta paralela de um ZIP drive e que deseja fazer o backup do sistema GNU/Linux em um disco ZIP.
call-back-mini-HOWTO
Descreve como configurar um call-back usando um sistema GNU/Linux e um modem.
Configurando o GNU/Linux para funcionar com Asymmetric Digital Subscriber Loop (ADSL), uma nova tecnologia de acesso digital de alta velocidade através de linhas disponível através da Telcos. O ADSL é uma das tecnologias disponíveis da família da digital subscriber line (DSL) disponíveis para usuários residenciais e comerciais usando copper loops, oferecendo velocidades que variam de 384kbps a 1.5Mbps. Este documento contém uma introdução ao ADSL e informações de como instalar, configurar e colocar o ADSL para funcionar.
Apache SSL PHP fp
Este documento explica como construir um servidor web que suportará conteúdo web dinâmico via a linguagem de scripting PHP/FI, transmissão de dados segura baseado no SSL do Netscape, execução segura de CGI's e extensões do M$ Frontpage Server.
Apache-mods
Detalhes sobre a instalação do servidor web baseado no Apache configurado para manipular DSO e vários módulos úteis incluindo perl, ssl, e php.
Bridge
Este documento descreve como ajustar uma ponte ethernet (bridge). O que é uma ponte ethernet? É um dispositivo que controla os pacotes de dados dentro de uma subrede na tentativa de cortar o excesso de tráfego. Uma ponte é colocada normalmente entre dois grupos separados de computadores que falam entre eles, mas não muito com computadores no outro grupo. Um bom exemplo disto é considerar um grupo de Macintoshes e um grupo de máquinas Unix. Ambos destes grupos de máquinas tendem falar uma com as outras, e o tráfego que produzem na rede causam colisões para as outras máquinas que estão tentando falar uma com a outra. Uma ponte pode ser colocada entre estes dois grupos de computadores. A tarefa da ponte é então examinar o destino dos pacotes de dados um por vez e decidir o que passar ou não para o outro lado do segmento ethernet. O resultado é uma rede rápida com menos colisões.
Bridge Firewall
Como configurar uma ponte com um firewall.
Bridge Firewall DSL
Configurando um sistema GNU/Linux para funcionar como um firewall e ponte com uma conexão de rede DSL.
Cipe Masq
Como configurar uma VPN usando o Cipe em um firewall GNU/Linux masquerading.
Compressed-TCP
Seções TCP/IP compactadas usando ferramentas como SSH.
DHCP
Este documento tenta responder questões básicas de como configurar seu computador GNU/Linux para servir de cliente ou servidor DHCP.
DPT-Hardware-RAID
Como ajustar o hardware RAID sob o GNU/Linux.
Domain
Este documento explica as coisas que você provavelmente deve fazer quando desejar construir uma rede de computadores sob seu próprio domínio. Ele cobre a configuração dos parâmetros de rede, serviços de rede e segurança.
FTP
Como usar clientes e servidores FTP.
Fax-Server
Descreve os métodos mais simples de configurar um servidor de fax em seu sistema GNU/Linux. O fax está disponível aos usuários do seu sistema local e rede de usuários.
Firewall-Piercing
Métodos de usar PPP através de telnet para tornar os materiais da rede transparentes através de um firewall Internet.
Home-Network-mini-HOWTO
Um tutorial simples de configuração do sistema Red Hat 6 e variantes para operar como um gateway na internet para uma pequena rede doméstica ou de escritório. Entre os tópicos cobertos estão incluídos masquerading, DNS, DHCP e segurança básica.
IP-Alias
Descreve como utilizar vários IPs em uma única interface de rede. Em adição, estão incluídas instruções de como ajustar a máquina para receber e-mais em IPs alises.
IP-Subnetworking
Descreve porque e como subdividir uma rede IP - que está usando uma simples classe de rede A, B ou C para funcionar corretamente em diversas redes interconectadas.
IPMasquerading Napster
Descreve como permitir usuários através de um sistema IPMasquerade usar o Napster.
ISP-Connectivity
Descreve como configurar o PPP, conectar-se ao seu Provedor, configurar o E-mail e news, obter um IP permanente (se disponível), obter um nome de domínio.
Mail-Queue
Queue E-mails remotos Entregar e-mails locais as configurações necessárias para fazer o Sendmail enviar mensagens locais ***Agora*** e entregar mensagens remotas "quando quiser".
Netrom-Node
Este documento descreve como configurar o pacote de utilitários ax25 para Rádio Amadores.
PLIP
Este documento lhe ajudará a usar sua porta Paralela para conexão entre computadores.
ppp-ssh
Descreve como configurar uma rede VPN usando ssh sobre ppp.
PortSlave
Configurando e usando um roteador Linux para conexão remota, radius, console serial.
Proxy-ARP-Subnet
Este documento discute o uso do Proxy Address Resolution Protocol (ARP) com subrede em ordem para fazer uma pequena rede de computadores visível a outra sub rede IP (eu chamo isto de sub-subrede). isto faz todas as máquinas na rede local (rede 0 onde estamos agora) aparecer como se estivessem conectadas a rede principal (rede 1).
Public-Web-Browser
A idéia básica é dar acesso web a pessoas que desejam, limitando suas habilidades de causar problemas.
Qmail MH
Ensina como usar o Qmail em conjunto com o MH.
Remote-Boot
Este documento descreve como configurar um servidor de inicialização robusto e seguro para um grupo de PCS, permitindo cada cliente escolher em tempo de inicialização qual sistema operacional executar.
SLIP-PPP-Emulator
Descreve como obter seu computador Linux conectado a um site genérico via emulador SLIP/PPP, tal como SLiRP ou TIA.
Sendmail UUCP
Como utilizar o Sendmail em conjunto com o UUCP.
Sendmail-Address-Rewrite
Breve descrição de como ajustar o arquivo de configuração do sendmail para o usuário doméstico que utiliza o acesso dial-up a
Sybase-PHP-Apache
Explica como usar o PHP Apache para acesso a uma base de dados Sybase-ASE.
Term-Firewall
Métodos de usar o "term" para tornar os materiais de rede transparentes através de um firewall TCP que parece não ser capaz.
Token-Ring
Fazendo o Token Ring funcionar no GNU/Linux.
TransparentProxy
Como configurar um servidor proxy transparente de cache HTTP usando somente o GNU/Linux e o Squid.
VPN
Ensina como configurar uma Virtual Protected Network no GNU/Linux.
Este documento oferece sugestões de como a comunidade Linux pode defender efetivamente o uso do Linux.
BogoMips
Detalhes sobre BogoMips. Este texto foi criado a partir de vários arquivos GNU/Linux no arquivo HOWTO/mini/BogoMips.
Commercial-Port-Advocacy
Este documento discute métodos que podem ser usados como aproximação de empresas comerciais para convence-las a portar seus programas para o GNU/Linux.
São documentos instalados junto com os programas. Alguns programas também trazem o aviso de copyright, changelogs, modelos, scripts, exemplos e FAQs (perguntas frequêntes) junto com a documentação normal.
Seu princípio é o mesmo do How-to; documentar o programa. Estes arquivos estão localizados em:
/usr/doc/[programa].
Programa é o nome do programa ou comando procurado.
FAQ é um arquivo de perguntas e respostas mais frequêntes sobre o programa. Normalmente os arquivos de FAQ estão localizados junto com a documentação principal do programa em /usr/share/doc/[programa].
São textos que contém normas para a padronização dos serviços e protocolos da Internet (como a porta padrão de operação, comandos que devem ser utilizados, respostas) e outros detalhes usados para padronizar o uso de serviços Internet entre as mais diversas plataformas de computadores, com o objetivo de garantir a perfeita comunicação entre ambos. As RFCs podem ser obtidas de http://rfc.net.
O arquivo de uma RFC segue o formato RFC Número, onde RFC descreve que o documento é uma RFC e Número é o seu número de identificação, como o documento RFC1939 que documenta o funcionamento e comandos do protocolo POP3. Os arquivos de RFCs podem ser encontrados no pacote doc-rfc da distribuição Debian e baseadas .
Segue abaixo o índice principal do diretório de RFCs que poderá ser usado para localizar RFCs específicas de um determinado serviço/assunto:
Números designados. J. Reynolds, J. Postel. Outubro 1994. (Formato: TXT=458860 bytes) (Também RFC1700)
0003
Requerimentos do sistema. R. Braden. Outubro 1989. (Formato: TXT=528939 bytes) (Também RFC1122, RFC1123)
0004
Requerimentos do Gateway. R. Braden, J. Postel. Junho 1987. (Formato: TXT=125039 bytes) (Também RFC1009)
0005
Protocolo Internet. J. Postel. Setembro 1981. (Formato: TXT=241903 bytes) (Também RFC0791, RFC0950, RFC0919, RFC0922, RFC792, RFC1112)
0006
User Datagram Protocol. J. Postel. Agosto 1980. (Formato: TXT=5896 bytes) (Também RFC0768)
0007
Transmission Control Protocol. J. Postel. September 1981. (Formato: TXT=172710 bytes) (Também RFC0793)
0008
Protocolo Telnet. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=44639 bytes) (Também RFC0854, RFC0855)
0009
File Transfer Protocol. J. Postel, J. Reynolds. Outubro 1985. (Formato: TXT=148316 bytes) (Também RFC0959)
0010
SMTP Service Extensions. J. Klensin, N. Freed, M. Rose, E. Stefferud & D. Crocker. Novembro 1995. (Formato: TXT=23299 bytes) (Deixa obsoleto RFC1651) (Também RFC821, RFC1869)
0011
Standard for the format of ARPA Internet text messages. D. Crocker. 13-Ago-1982. (Formato: TXT=109200 bytes) (Deixa obsoleto RFC1653) (Também RFC0822)
0012
Network Time Protocol. D. Mills. Setembro 1989. (Formato: TXT=193 bytes) (Também RFC1119)
0013
Domain Name System. P. Mockapetris. Novembro 1987. (Formato: TXT=248726 bytes) (Também RFC1034, RFC1035)
0014
Mail Routing and the Domain System. C. Partridge. Janeiro 1986. (Formato: TXT=18182 bytes) (Também RFC0974)
0015
Simple Network Management Protocol. J. Case, M. Fedor, M. Schoffstall, J. Davin. Maio 1990. (Formato: TXT=72876 bytes) (Também RFC1157)
0016
Structure of Management Information. M. Rose, K. McCloghrie. Maio 1990. (Formato: TXT=82279 bytes) (Deixa obsoleto RFC1065) (Também RFC1155)
0017
Management Information Base. K. McCloghrie, M. Rose. March 1991. (Formato: TXT=142158 bytes) (Deixa obsoleto RFC1158) (Também RFC1213)
0018
Exterior Gateway Protocol. D. Mills. Abril 1984. (Formato: TXT=63836 bytes) (Também RFC0904)
0019
NetBIOS Service Protocols. NetBIOS Working Group. Março 1987. (Formato: TXT=319750 bytes) (Também RFC1001, RFC1002)
0020
Echo Protocol. J. Postel. Maio 1983. (Formato: TXT=1237 bytes) (Também RFC0862)
0021
Discard Protocol. J. Postel. Maio 1983. (Formato: TXT=1239 bytes) (Também RFC0863)
0022
Character Generator Protocol. J. Postel. Maio 1983. (Formato: TXT=6842 bytes) (Também RFC0864)
0023
Quote of the Day Protocol. J. Postel. Maio 1983. (Formato: TXT=1676 bytes) (Também RFC0865)
0024
Active Users Protocol. J. Postel. Maio 1983. (Formato: TXT=2029 bytes) (Também RFC0866)
0025
Daytime Protocol. J. Postel. Maio 1983. (Formato: TXT=2289 bytes) (Também RFC0867)
0026
Time Server Protocol. J. Postel. Maio 1983. (Formato: TXT=3024 bytes) (Também RFC0868)
0027
Binary Transmission Telnet Option. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=8965 bytes) (Também RFC0856)
0028
Echo Telnet Option. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=10859 bytes) (Também RFC0857)
0029
Suppress Go Ahead Telnet Option. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=3712 bytes) (Também RFC0858)
0030
Status Telnet Option. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=4273 bytes) (Também RFC0859)
0031
Timing Mark Telnet Option. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=7881 bytes) (Também RFC0860)
0032
Extended Options List Telnet Option. J. Postel, J. Reynolds. Maio 1983. (Formato: TXT=3068 bytes) (Também RFC0861)
0033
Trivial File Transfer Protocol. K. Sollins. Julho 1992. (Formato: TXT=24599 bytes) (Também RFC1350)
0034
Routing Information Protocol. C. Hedrick. Junho 1988. (Formato: TXT=91435 bytes) (Também RFC1058)
0035
ISO Transport Service on top of the TCP (Version: 3). M. Rose, D. Cass. Maio 1978. (Formato: TXT=30662 bytes) (Também RFC1006)
0036
Transmission of IP and ARP over FDDI Networks. D. Katz. Janeiro 1993. (Formato: TXT=22077 bytes) (Também RFC1390)
0037
An Ethernet Address Resolution Protocol. David C. Plummer. Novembro 1982. (Formato: TXT=21556 bytes) (Também RFC0826)
0038
A Reverse Address Resolution Protocol. Ross Finlayson, Timothy Mann, Jeffrey Mogul, Marvin Theimer. Junho 1984. (Formato: TXT=9345 bytes) (Também RFC0903)
0039
Interface Message Processor: Especificações para a Interconexão de um computador e um IMP (Revisado). BBN. Dezembro 1981. (fora de linha)
0040
Host Access Protocol specification. Bolt Beranek and Newman. Agosto 1993. (Formato: TXT=152740 bytes) (Deixa obsoleto RFC0907) (Também RFC1221)
0041
Standard for the transmission of IP datagrams over Ethernet networks. C. Hornig. Abril 1984. (Formato: TXT=5697 bytes) (Também RFC0894)
0042
Standard for the transmission of IP datagrams over experimental Ethernetnetworks. J. Postel. Abril 1984. (Formato: TXT=4985 bytes) (Também RFC0895)
0043
Standard for the transmission of IP datagrams over IEEE 802 networks. J. Postel, J.K. Reynolds. Agosto 1993. (Formato: TXT=34359 bytes) (Deixa obsoleto RFC0948) (Também RFC1042)
Internet Protocol on Network System's HYPERchannel: Protocol Specification. K. Hardwick, J. Lekashman. Augosto 1993. (Formato: TXT=100836 bytes) (Também RFC1044)
0046
Transmitting IP traffic over ARCNET networks. D. Provan. Agosto 1993. (Formato: TXT=16565 bytes) (Deixa obsoleto RFC1051) (Também RFC1201)
0047
Nonstandard for transmission of IP datagrams over serial lines: SLIP. J.L. Romkey. Agosto 1993. (Formato: TXT=12578 bytes) (Também RFC1055)
0048
Standard for the transmission of IP datagrams over NetBIOS networks. L.J. McLaughlin. Agosto 1993. (Formato: TXT=5579 bytes) (Também RFC1088)
0049
Standard for the transmission of 802.2 packets over IPX networks. L.J. McLaughlin. Agosto 1993. (Formato: TXT=7902 bytes) (Também RFC1132)
0050
Definitions of Managed Objects for the Ethernet-like Interface Types. F. Kastenholz. Julho 1994. (Formato: TXT=39008, bytes) (Deixa obsoleto RFC1623, RFC1398) (Também RFC1643)
0051
The Point-to-Point Protocol (PPP). W. Simpson, Editor. Julho 1994. (Formato: TXT=151158 bytes) (Deixa obsoleto: RFC1549) (Também RFC1661, RFC1662)
0052
The Transmission of IP Datagrams over the SMDS Service. D. Piscitello, J. Lawrence. Março 1991. (Formato: TXT=24662 bytes) (Também RFC1209)
0053
Post Office Protocol - Version 3. J. Myers & M. Rose. Maio 1996. (Formato: TXT=47018 bytes) (Deixa Obsoleto: RFC1725) (Também RFC1939)
0054
OSPF Version 2. J. Moy. Abril 1998. (Formato: TXT=447367 bytes) (Também RFC2328)
0055
Multiprotocol Interconnect over Frame Relay. C. Brown, A. Malis. Setembro 1998. (Formato: TXT=74671 bytes) (Deixa Obsoleto: RFC1490, RFC1294) (Também RFC2427)
0056
RIP Version 2. G. Malkin. Novembro 1998. (Formato: TXT=98462 bytes) (Atualiza RFC1723, RFC1388) (Também RFC2453)
0057
RIP Version 2 Protocol Applicability Statement. G. Malkin. Novembro 1994. (Formato: TXT=10236 bytes) (Também RFC1722)
0058
Structure of Management Information Version 2 (SMIv2. K. McCloghrie, D. Perkins, J. Schoenwaelder. Abril 1999. (Formato: TXT=89712 bytes) (Deixa Obsoleto RFC1902) (Também RFC2578, RFC2579)
0059
Remote Network Monitoring Management Information Base. S. Waldbusser. Maio 2000. (Formato: TXT=198676 bytes) (Deixa Obsoleto RFC1757) (Também RFC2819)
Existem boas páginas Internet Nacionais e Internacionais sobre oGNU/Linux e assuntos relacionados com este sistema. A maioria trazem documentos e explicações sobre configuração, instalação, manutenção, documentação, suporte, etc.
Estas páginas podem ser encontradas através de ferramentas de busca. Entre outras páginas, posso citar as seguintes:
http://debian-br.cipsga.org.br/ Projeto Debian-Br. A Debian é uma distribuição de Linux conhecida por sua qualidade, grande número de pacotes, estabilidade, facilidade de atualização, desenvolvimento aberto, segurança, ferramentas de gerenciamento de servidores e comprometimento com o software livre.
A Debian é feita originalmente em inglês e traduzida por grupos em vários lugares do mundo. O projeto Debian-br destina-se a colaborar na tradução da Debian para o Português (nossa língua-mãe). Através desse projeto, todos poderão, da forma colaborativa como na Debian, trazer essa excelente distribuição em nosso idioma!
Participe:
http://debian-br.cipsga.org.br/contador-debian/contador.html - O contador Debian é uma página idealizada para que fossem geradas estatísticas fáceis de se aplicar quanto ao número e características próprias de cada grupo de usuários Debian no Brasil.
Sua base é construída em PHP com uso do banco de dados MySQL, hospedado no Source Forge é mantido pelo pessoal do projeto Debian-BR o contador tem também a facilidade de integrar-se com o bot apt-br facilitando a vida dos usuários do canal IRC do projeto.
Responsável pela página: Gustavo Noronha dockov@zaz.com.br endereço: http://debian-br.cipsga.org.br/contador-debian/contador.html
http://www.br-linux.org/ - Boletim diário com as noticias mais recentes sobre GNU/Linux, testes, redes, descrição/configuração/ avaliação de programas, entrevistas, downloads, dica do dia, mecanismo de busca no site, links, etc. Em Português.
http://www.olinux.com.br/ - Trata o GNU/Linux com o foco jornalístico e tem a intenção de prover informações eficazes e esclarecedoras capazes de instruir, reciclar e tornar acessível aos usuários o conhecimento e aprofundamento de temas relacionados a plataforma GNU/Linux.
Publicação diária de Artigos que são feitos para que o usuário possa resolver problemas e tirar dúvidas deste sistema. Assuntos diversos sobre programas, serviços e utilitários. Também conta com seções de programação, jogos, segurança e entrevistas com personalidades do cenário software livre/código aberto. Atualização diária.
Responsável pela página: Linux Solutions baptista@linuxsolutions.com.br endereço: http://www.olinux.com.br/.
http://come.to/linuxworld/ - Informações sobre distribuições Linux, downloads, gerenciadores de janelas (Enlightenment, Window Maker, etc) temas com fotos ilustrativas, seção programa do mês (onde é falado sobre um programa interessante), seção sobre jogos (para as pessoas enviarem suas dúvidas de jogos). Em Português.
Esta home page também traz uma seção onde as pessoas escrevem suas dúvidas, que são recebidas pelo responsável pela página, solucionadas e respondidas.
Responsável pela página: Luiz Estevão Baptista de Oliveira luizestevao@yahoo.com endereço: http://come.to/linuxworld/.
http://www.linuxsecurity.com.br/ - Boletins de segurança, publicações de textos nacionais, traduções de sites especializados em segurança, programas relacionados com criptografia e segurança no ambiente Linux. A página requer um navegador com suporte a Java.
http://www.tldp.org/ - Projeto de documentação do GNU/Linux no Brasil. Toda a documentação traduzida para o Português do Brasil pode ser encontrada lá.
http://www.guiadohardware.net/ - Site de Hardware, conta com notícias diárias, cursos on-line, artigos, tutoriais, análises de equipamentos, fórum, dicionário de termos, dicas sobre overclock, palm pilot e sessão FAQ com mais de 300 dúvidas respondidas.
O LinuxChix Brasil, assim como o Projeto LinuxChix internacional, é uma comunidade para mulheres que gostam de Linux, e para apoiar as mulheres na computação em geral. As participantes vão desde novatas í usuárias experientes, e incluem programadoras profissionais e amadoras, administradoras de sistemas e documentadoras técnicas.
Responsável pela página: Lista LinuxChix linuxchix@listas.cipsga.org.br endereço: http://www.guiadohardware.net/.
http://www.linux.org/ - Página oficial do GNU/Linux mantida pela Transmeta (a empresa que Linus Torvalds vem trabalhando atualmente). Muita referência sobre GNU/Linux, distribuições, hardwares, softwares, downloads, etc.
http://counter.li.org/ - Este é um serviço que tem o objetivo de contar os usuários, máquinas, grupos de usuários Linux existentes ao redor do mundo. Te encorajo a se registrar neste site e indica-lo aos seus amigos, é de graça, você estará contribuindo para o aumento das estatísticas do número de usuários no mundo, país, sua cidade, etc.
O site também conta com um sistema de estatísticas de usuários, máquinas e grupos de usuários espalhados ao redor do mundo. Você pode saber em poucos segundos a quantidade de usuários Linux em seu país, cidade, etc.
Responsável pela página: Harald T. Alvestrand harald@alvestrand.no endereço: http://counter.li.org/.
http://metalab.unc.edu/ - O ponto de referência mais tradicional de softwares GNU/Linux do mundo. Você pode encontrar desde dicas, documentação (todos os How-Tos) até diversas distribuições GNU/Linux.
http://www.themes.org/ - Neste site você encontra milhares de temas divididos em categorias para os mais diversos gerenciadores de janelas no GNU/Linux. O site é muito pesado, por causa das fotos, é recomendável um bom fax-modem ou muita paciência.
http://www.oreill.com/safari/ - Neste site você encontra os livros publicados sobre a licença OpenBook da Orreil. Na maioria livros que não atende mais propósitos atualmente e livros em que os autores concordaram em licenciar sob os termos OpenBook.
Caso conhecer uma página de Internet que contenha materiais úteis a comunidade GNU/Linux ou desejar incluir a sua, entre em contato para sua inclusão na próxima versão do guia junto com uma descrição da página.
São grupos de usuários que trocam mensagens entre si, resolvem dúvidas, ajudam na configuração de programas, instalação, etc. É considerado o melhor suporte ao GNU/Linux pois qualquer participante pode ser beneficiar das soluções discutidas. Existem milhares de listas de discussões sobre o GNU/Linux espalhadas pelo mundo, em Português existem algumas dezenas.
Algumas listas são específicas a um determinado assunto do sistema, algumas são feitas para usuários iniciantes ou avançados, outras falam praticamente de tudo. Existem desde usuários iniciantes, hackers, consultores, administradores de redes experientes e gurus participando de listas e oferecendo suporte de graça a quem se aventurar em instalar e usar o sistema GNU/Linux.
A lista de discussão funciona da seguinte forma: você se inscreve na lista enviando uma mensagem ao endereço de inscrição, será enviada um pedido de confirmação por e-mail, simplesmente dê um reply na mensagem para ser cadastrado. Pronto! agora você estará participando do grupo de usuários e receberá todas as mensagens dos participantes do grupo. Assim você poderá enviar sua mensagem e ela será vista por todos os participantes da lista.
Da mesma forma, você pode responder uma dúvida de outro usuário da lista ou discutir algum assunto, tirar alguma dúvida sobre a dúvida de outra pessoa, etc.
Não tenha vergonha de enviar sua pergunta, participar de listas de discussão é uma experiência quase obrigatório de um Linuxer. Abaixo segue uma relação de listas de discussão em Português com a descrição, endereço de inscrição, e o que você deve fazer para ser cadastrado:
Lista de discussão para usuários Portugueses da Debian. Também são discutidos assuntos relacionados ao Linux em geral. A inscrição é aberta a todos os interessados.
Para se inscrever, envie uma mensagem para debian-user-portuguese-request@lists.debian.org contendo a palavra subscribe no assunto da mensagem. Será enviada uma mensagem a você pedindo a confirmação da inscrição na lista de discussão, simplesmente dê um reply na mensagem (responder) e você estará cadastrado e poderá enviar e receber mensagens dos participantes.
A Debian é extremamente bem estruturada quanto a divulgações e notícias, várias listas de email e várias páginas compõe essa base. A Debian Weekly News é especialmente importante pois dá uma visão geral do que se passou na Debian durante a semana. E não traz apenas traduções mas também adições dos acontecimentos atuais da Debian no Brasil, ou projetos concluídos ou lançados pela equipe Debian-br (http://debian-br.cipsga.org.br/).
Essa lista NÃO é usada para resolução de dúvidas e problemas, apenas para o RECEBIMENTO de notícias relacionadas a Debian. Não poste mensagens nela!
Para se inscrever, envie uma mensagem para debian-news-portuguese-request@lists.debian.org contendo a palavra subscribe no assunto da mensagem. Será enviada uma mensagem a você pedindo a confirmação da inscrição na lista de discussão, simplesmente dê um reply na mensagem (responder) e você passará a receber as notícias sobre a Debian em Português.
Lista de discussão que cobre assuntos diversos. Esta lista é voltada para usuários com bons conhecimentos no GNU/Linux, são abordados assuntos como redes, configurações, etc. Esta é uma lista moderada, o que significa que a mensagem que envia passam por uma pessoa que verifica (modera) e a libera caso estejam dentro das normas adotada na lista. É uma lista de alto nível e recomendada para quem deseja fugir de mensagens como não consigo instalar o Linux, não sei compilar o kernel, o que eu faço quando vejo uma tela com o nome login:?, etc.
Para se inscrever nesta lista, envie uma mensagem para: linux-br-request@unicamp.br contendo a palavra subscribe no assunto da mensagem e aguarde o recebimento da confirmação da inscrição. Apenas responda a mensagem de confirmação para se inscrever. Para se descadastrar envie uma mensagem para o mesmo endereço mas use a palavra unsubscribe.
Esta lista envia diariamente uma dica de Unix, sistemas da Microsoft ou novidades da Internet.
Para se inscreve nesta lista de discussão, envie uma mensagem para: dicas-l-request@unicamp.br contendo a palavra subscribe no corpo da mensagem e aguarde o recebimento da confirmação da inscrição. Apenas responda a mensagem de confirmação para confirmar sua inscrição na lista. Para se descadastrar envie uma mensagem para o mesmo endereço mas use a palavra unsubscribe.
Esta listagem deveria estar mais completa, mas eu não lembro de todas as listas!. Também recomendo dar uma olhada em [#s-ajuda-netiqueta-listas Listas de Discussão via Email, Seção 31.13.5] que descreve recomendações de comportamento em listas de discussão.
São recomendações que tem como objetivo facilitar a para comunicação através dos recursos de uma rede. O nome Netiqueta vem de "Etiqueta de Rede" (Net Etiquete). O material desta seção foi escrito com base nos anos de observação que tive via internet e também com referência a rfc 1855.
Recomendações Gerais sobre a Comunicação Eletrônica
Como recomendação geral, lembre-se que a conversa via internet é feita sempre de uma para outra pessoa ou de uma para várias pessoas, e que a forma de comunicação é a mesma que utilizaria se estivesse de frente a frente com a pessoa. Nunca diga algo que não diria se estivesse diante da outra pessoa. Existem pessoas que por estar atrás de um monitor, se sentem "maiores" se esquecendo disso e causando prejuízos de comunicação (e sem imaginar que a pessoa do outro lado da linha existe).
Apesar do modo que as frases são escritas expressarem o jeito que a outra pessoa está do outro lado da linha e seu tom de comunicação no decorrer da conversar, existem algumas coisas que não podem ser totalmente expressadas através da Internet, como por exemplo a expressão da "face" das pessoas. Para isto foram criados símbolos chamados smileys que expressam a face da outra pessoa em determinado momento, e dependendo do sentido da conversa, um smiley pode expressar corretamente a intenção de sua frase. Os mais usados são os seguintes:
:-) --> Sorriso
:-( --> Triste
;-) --> Piscadinha
:-O --> De boca aberta
:-| --> Sem graça
8-) --> De óculos
|-) --> Com sono e feliz
<:-) --> Bobo
Para entender o sentido do smiley, veja ele de lado (45 graus). Use os smileys em suas conversações, mas com cautela. Não espere que a inclusão de um smiley sorridente ":-)" deixe o destinatário da mensagem contente com um comentário rude ou insulto.
ESCREVER EM MAIÚSCULAS significa gritar quando escrever mensagens eletrônicas.
Use *asteriscos* para destacar uma palavra ou frase. _Isso_ indica uma palavra/frase sublinhada.
Se você troca mensagens com pessoas do mundo todo, não espere que um japonês responda logo seu e-mail que enviou as 15:00 da tarde. A essa hora no país dele, ele está roncando forte na cama e sonhando com a placa 3D que vai ganhar para melhorar o desempenho de seus jogos de Linux.
Durante a comunicação com pessoas de diferentes regiões (ou países), evite a utilização de gírias, ou expressões regionais. Uma interpretação em uma determinada região não garante que ela tenha o mesmo significado para seu destinatário, as vezes pode ser até ofensiva.
Assuma que sua mensagem está trafegando sobre uma via não segura, desta forma não envie informações pessoais que não enviaria em uma carta comum. O uso de criptografia pode garantir melhor segurança na transmissão de dados.
Tenha o hábito de colocar sempre um assunto na mensagem que envia para identificar seu conteúdo.
Respeite os direitos autorais das mensagens de e-mail. Se precisar encaminhar mensagens, preserve seu conteúdo original.
Procure limitar o tamanho da linha a 70 caracteres. Muitos usuários utilizam cliente de e-mail em modo texto, e nem todo mundo usa a mesma resolução que você.
Caso o e-mail que responda tenha mais que 100 linhas, é recomendável colocar a palavra "LONGA" no assunto da mensagem. Se possível corte as partes não necessárias da mensagens de respostas tendo o cuidado de não "cortar" de forma mal educada a mensagem de outra pessoa.
Não espere que o espaçamento ou desenhos ASCII usados em uma mensagem sejam mostrados corretamente em todos os sistemas.
Utilize sempre uma assinatura no final da mensagem para identificar você e principalmente seu endereço de e-mail. Em alguns cliente de e-mail, o campo Reply-to é bagunçado, e em e-mails redirecionados o endereço de resposta é excluído. A assinatura facilita encontrar o remetente da mensagem. Tente manter a assinatura em um tamanho de no máximo 4 linhas.
Não repasse mensagens de corrente por e-mail. Elas tem somente o objetivo de espalhar boatos na Internet e se espalhar. Normalmente elas vem com uma história bonita e no final diz se não repassar acontecerá tudo ao contrário com você ou algo do tipo. Não vai acontecer nada! ignore isso e não entre na corrente!
Pelas políticas da Internet, você pode ter sua conta de e-mail perdida se fizer mal uso dele.
Use sempre quebra de linhas ao escrever suas mensagens, use pelo menos 70 caracteres para escrever suas mensagens de talk. Evita escrever continuamente até a borda para fazer quebra de linha automática, alguns clientes de talk não aceitam isso corretamente.
Sempre que termina uma frase, deixe uma linha em branco (tecle enter 2 vezes) para indicar que a outra pessoa pode iniciar a digitação.
Sempre se despeça da outra pessoa e espere ela responder antes de fechar uma seção de conversação. O respeito mútuo durante um diálogo é essencial :-)
Lembre-se que o talk normalmente interrompe as pessoas que trabalham nativamente no console. Evite dar talk para estranhos, pois podem fazer uma má impressão de você. Tente antes estabelecer outros meios de comunicação.
Se a outra pessoa não responder, não assuma de cara que ela está ignorando você ou não levando sua conversa muito bem. Ela pode simplesmente estar ocupada, trabalhando, ou com problemas no cliente de talk. Alguns cliente de talk dão problemas durante a comunicação remota, lembre-se também que sua comunicação é via UDP :-)
Se a pessoa não responder seus talks durante certo tempo, não deixe ele infinitamente beepando a pessoa. Tente mais tarde :-)
Seja atencioso caso utilize mais de uma seção de talk ao mesmo tempo.
O talk também leva em consideração sua habilidade de digitação. Muitos erros e correções contínuas fazem a outra pessoa ter uma noção de você, suas experiências, etc ;-)
O ICQ é uma excelente ferramenta de comunicação em tempo real, usada principalmente para localizar quando uma pessoa está on-line. Este documento inclui algumas recomendações de ICtiQueta (Etiqueta no ICQ) para melhor os usuários aproveitarem melhor esta ferramenta.
De atenção ao status do ICQ da outra pessoa. Se ela estiver "on-line" ou "free for chat" significa que ela está desocupada e que pode conversar naquele instante. Se estiver como não perturbe, envie somente mensagens se for mesmo preciso.
Seja também sensato ao usar o ICQ. Não entre nele caso não possa conversar, ou avise isso mudando seu status para o mais adequado para a situação, assim os outros poderão entender que está longe do computador, não disponível ou ocupado.
É recomendável ser prudente quanto ao envio de mensagens no ICQ, não envie mais do que 4 mensagens seguidas, pois a outra pessoa terá dificuldades para responder a todas elas mais outra que talvez possa estar recebendo de outras.
Guarde seu login e senha de ICQ em um lugar seguro. Caso ela seja perdida, você terá trabalho para avisar a todos de sua lista de contato.
Caso alguém de sua lista de contatos esteja sempre on-line e não lhe envia mensagens há muito tempo, não fique com a impressão de que ela não quer trocar mais mensagens com você. Pode ser apenas que ela tenha reinstalado seu programa de ICQ e não tenha anotados todos seus UIN's.
Normalmente quando se envia uma mensagem para a pessoa, o UIN é automaticamente cadastrado em sua lista.
Não pense que a opção "Requer Autorização" te de o controle total de quem terá ou não seu número de ICQ em sua lista. Utilize as opções de privacidade para configurar.
Sempre que enviar uma URL, procure descrever algo para seu interlocutor na mensagem.
No modo de chat, use as recomendações descritas sobre o talk (em [#s-ajuda-netiqueta-talk Talk, Seção 31.13.3]).
Como em toda comunicação on-line, seja cauteloso quando a pessoa que conversa. Nem sempre quem conversamos do outro lado é a pessoa que esperamos encontrar. Lembre-se que um registro falso e uma identidade pode ser criada sem dificuldades por qualquer pessoa.
Tente se manter dentro do assunto quando responder mensagens de listas. Seja claro e explicativo ao mesmo tempo :-)
Sempre coloque um assunto (subject) na mensagem. O assunto serve como um resumo do problema ou dúvida que tem. Alguns usuários, principalmente os que participam de várias listas de discussão, verificam o assunto da mensagem e podem simplesmente descartar a mensagem sem lê-la porque as vezes ele não conhece sobre aquele assunto.
Nunca use "Socorro!", "Help!" ou coisa do gênero como assunto, seja objetivo sobre o problema/dúvida que tem: "Falha ao carregar módulo no do kernel", "SMAIL retorna a mensagem Access denied", "Novidades: Nova versão do guia Foca Linux" ;-).
Procure enviar mensagens em formato texto ao invés de HTML para as listas de discussão pois isto faz com que a mensagem seja vista por todos os participantes (muitos dos usuários GNU/Linux usam leitores de e-mail que não suportam formato html) e diminui drásticamente o tamanho da mensagem porque o formato texto não usa tags e outros elementos que a linguagem HTML contém (muitos dos usuários costumam participar de várias listas de discussão, e mensagens em HTML levam a um excesso de tráfego e tempo de conexão).
Tenha cautela e bom censo em suas mensagens para listas e grupos de discussão, considere que cada mensagem que posta é são arquivadas para futura referência.
Quando o conteúdo das mensagem tomar outro rumo, é ético modificar o assunto do e-mail para se adequar ao novo conteúdo da mensagem. Por exemplo, Correção nas regras de Netiqueta para Conversa de pessoa para pessoa (Era: Correção das regras de Netiqueta).
Quando a conversa em grupo sair do assunto e envolver apenas duas pessoas, é conveniente retirar os endereços das pessoas/listas do CC.
Não mande arquivos grandes para as listas, principalmente se eles tiverem mais que 40Kb de tamanho. Se precisar enviar arquivos maiores que isso, envie diretamente para os e-mails dos interessados depois de perguntar.
Quando enviar mensagens para listas de discussão, seja educado e cordial quanto ao conteúdo de sua mensagem. Envie CC's para as pessoas que dizem respeito ao assunto, assim com a lista.
Tente ignorar ou não responda mensagens de "Guerras" em listas (Flame Wars), caso queira reponde-la por algum tipo de agressão de quem mandou a mensagem, esperar para responde-la a noite (nunca é garantida uma boa resposta no momento que está de cabeça quente). Lembre-se de quando responde uma mensagem de "Flame War" a "altura" de quem mandou seus ataques, está sendo igualmente tão baixo quando o "nível" dessa pessoa.
Caso se desentenda com alguma pessoa em uma lista de discussão, não envie mensagens agressivas para a listas, se precisar, faça isso diretamente para a pessoa! Você pode se arrepender disso mais tarde.
Não culpe o administrador da lista pelos usuários que participam dela. Notifique somente usuários que não estejam colaborando com a lista e outras coisas que prejudiquem seu funcionamento. Administradores preservam o funcionamento das listas, e não o policiamento dos usuários.
Não use auto respostas para listas de discussão. Pelos inconvenientes causados, você pode ser descadastrado ou banido de se inscrever na lista/newsgroup.
Salve as mensagens de inscrição que recebe da lista. Ela contém detalhes sobre seus recursos, e a senha usada muitas vezes para se descadastrar dela ou modificar suas permissões de usuário. O administrador pode te ajudar nessa tarefa, mas não espere que ele esteja sempre disponível para realizar tarefas que podem ser feitas pelo próprio usuário.
Muitas pessoas reclamam do excesso de mensagens recebidas das listas de discussão. Se você recebe muitas mensagens, procure usar os filtros de mensagens para organiza-las. O que eles fazem é procurar por campos na mensagem, como o remetente, e enviar para um local separado. No final da filtragem, todas as mensagens de listas de discussão estarão em locais separados e as mensagens enviadas diretamente a você entrarão na caixa de correio principal, por exemplo.
Um filtro de mensagens muito usado no GNU/Linux é o procmail, para maiores detalhes consulte a documentação deste programa.
O Netscape também tem recursos de filtros de mensagem que podem ser criadas facilmente através da opção "Arquivo/Nova SubPasta" ("File/New Subfolder") do programa de E-mail. Então defina as regras através do menu "Editar/Filtros de Mensagens" ("Edit/Message filters") clicando no botão "Novo"("New").





.jpg)