Este é um conjunto convexo, pois todo segmento com extremidades no conjunto está totalmente contido no conjunto.
Este é um conjunto côncavo, pois existe um segmento com extremidades no conjunto que não está totalmente contido no conjunto.
Definição
Uma função é dita convexa quando é convexo e e vale
Definição
Dado um conjunto convexo , uma função é dita fortemente convexa quando existe uma constante tal que é convexa.
Exercício
Verifique que uma função quadrática é fortemente convexa se existe uma matriz simétrica definida positiva , um vetor e um escalar de modo que .
Resolução
Sendo uma função quadrática, tem-se . A matriz pode ser suposta simétrica, pois caso não seja, toma-se (simétrica), e segue (verifique).
Além disso, se é uma função fortemente convexa, então é estritamente convexa. Como é duas vezes diferenciável (por ser uma função quadrática), a convexidade estrita implica que é definida positiva.
Nota: Uma matriz é definida positiva se, e somente se, todos os seus autovalores são positivos.
Tem-se:
Sendo , segue em particular que e , onde é uma matriz diagonal cujos elementos da diagonal são os autovalores de e é uma matriz onde as colunas são os autovetores correspondentes aos autovalores.
Note que é uma matriz simétrica, pois é a matriz Hessiana de uma função com segundas derivadas parciais contínuas, e consequentemente vale .
Para introduzir o método de direções conjugadas, serão consideradas somente funções quadráticas.
Uma condição necessária de primeira ordem para que seja um ponto de mínimo para a função é que . Para o presente caso, a função é convexa, então, a condição necessária também é suficiente.
Exercício
Prove que se é uma matriz simétrica definida positiva, então dada por possui um único ponto de mínimo.
Resolução
Uma vez que é simétrica definida positiva, a função é fortemente convexa. Mas toda função fortemente convexa, definida em um conjunto fechado não vazio possui um único minimizador, pois:
Os conjuntos de nível de uma função fortemente convexa são compactos;
Toda função contínua definida em um compacto tem algum minimizador (pelo teorema de Weierstrass);
Os minimizadores de uma função convexa são globais;
Funções fortemente convexas não podem ter mais de um minimizador.
Em particular, possui um único ponto de mínimo.
No caso de uma função quadrática, tem-se , ou seja, é solução do sistema linear .
A resolução de um sistema linear nem sempre pode ser feita numericamente de forma eficiente. Por exemplo, se a matriz do sistema é:
A solução do sistema linear corresponde à interseção entre duas retas quase paralelas, e os erros de truncamento podem causar imprecisão na solução obtida computacionalmente.
Analiticamente, o sistema tem como solução. Então alguém poderia se perguntar: qual o problema em resolver esse sistema linear, se basta calcular a inversa da matriz e multiplicar pelo vetor ? A resposta é que o calculo da inversa de uma matriz em geral é impraticável computacionalmente, por ter custo muito alto. Por isso, nas situações práticas, onde as matrizes tem ordem bem maior do que 2 (digamos 1000), o cálculo de matrizes inversas não é uma opção.
Assim, com o intuito de desenvolver um método computacional para o cálculo de minimizadores, é preciso utilizar outras técnicas. Considere o seguinte:
Em um método de descida tem-se sempre uma sequencia , com e é um minimizador de
e
Logo, e multiplicando por obtem-se . Consequentemente, o valor de é dado por
Deste modo, o método consistirá de escolher em cada etapa uma direção , e calcular o coeficiente pela fórmula anterior, para gerar o próximo ponto . Mas como escolher a direção ?
Dado e escolhido , defina como , ou seja, é a restrição da função à reta que passa pelo ponto e que tem direção . Logo, derivando a expressão de em relação a , obtem-se
Então, no ponto de mínimo, , tem-se
Ou seja, a direção a ser seguida a partir do ponto é ortogonal ao gradiente da função , no ponto .
Uma comparação da convergência do método de descida do gradiente com tamanho de passo ótimo (em verde) e o método do gradiente conjugado (em vermelho) para a minimização da forma quadrática com um sistema linear dado. O gradiente conjugado, assumindo aritmética exata, converge em no máximo n passos onde n é o tamanho da matriz do sistema (no exemplo, n=2).
Primeiro passo: Escolha
Se , então pare:
Senão:
Calcular Passo iterativo : Dado
Se , então pare:
Senão:
Pode-se verificar facilmente que . De fato, como , tem-se . Logo, .
Exercício
Provar que se então .
Resolução
Tem-se
Multiplicando ambos os membros por , e trocando de lugar com resulta:
Considere definida por .
Em outros termos, tomando , tem-se , onde .
Pode-se aplicar o método de direções conjugadas ao seguinte problema
Note, desde já, que o conjunto solução é .
Inicio
Toma-se arbitrário, por exemplo, .
Avalia-se o gradiente da função neste ponto inicial:
Iteração 1
A seguir, verifica-se se o gradiente se anula no novo ponto :
Como o gradiente já é nulo, não é preciso fazer a segunda iteração, e o ponto é o (único) minimizador global de .
Em um caso mais geral, considerando definida por , tem-se cálculos muito parecidos em cada passo.
O conjunto solução continua sendo .
Inicio
Considere como no primeiro exemplo, ou seja, .
Avalia-se o gradiente da função neste ponto inicial:
Iteração 1
A seguir, verifica-se se o gradiente se anula no novo ponto :
Novamente, o gradiente se anula já na primeira iteração, de modo que é o minimizador global de .
Exercício
Seja uma matriz simétrica definida positiva, cujos autovalores são todos iguais. Então começando de qualquer ponto , o método fornece como solução.
Um terceiro exemplo pode ser dado tomando e definida por . Observe que tal matriz é simétrica e definida positiva:
Logo, os autovalores de são e . Isso também implica que a função é fortemente convexa.
Aplicando o método:
Início
Toma-se um ponto arbitrário no plano, por exemplo ;
Verifica-se se tal ponto é o minimizador global, avaliando nele o gradiente da função:
.
Já que o gradiente não se anulou no chute inicial, é preciso escolher uma direção e um comprimento de passo para determinar a próxima aproximação:
Iteração 1
Feitos esses cálculos, o próximo ponto é dado por
Para saber se será necessária uma nova iteração, ou se o minimizador foi encontrado, calcula-se o gradiente da função no ponto:
.
Novamente, será preciso calcular uma nova direção e um novo comprimento de passo:
Iteração 2
onde , no algoritmo de Hestenes é dado por:
Portanto
Além disso, o tamanho do passo é dado por
Portanto
Obviamente, este é o minimizador procurado (pois o método tem a propriedade de convergência quadrática, ou seja utiliza no máximo iterações para chegar a solução quando aplicado a funções quadráticas definidas em )
Exercício
Implementar o algoritmo de Hestenes-Stiefel em alguma linguagem de programação, por exemplo em Scilab, ou Matlab.
Exercício
Seja um função quadrática fortemente convexa. Verifique as seguintes igualdades:
Para facilitar a compreensão do método, pode ser útil exibir as curvas de nível da função. Uma forma de implementar uma função com esse propósito é a seguinte:
Um dos autores deste material sugeriu a adição de uma imagem para ilustrar o método de Fletcher-Reeves.
Esta versão é na verdade uma extensão do algoritmo anterior, permitindo a aplicação no caso de funções que não são quadráticas.
Primeiro passo: Escolha
Se , então pare:
Senão: (como em todo método de descida)
Calcular , através de uma busca linear
Passo iterativo:
Se , então pare:
Senão:
Calcular , através de uma busca linear
Um dos autores deste material sugeriu a adição de uma implementação do algoritmo acima em SciLab.
Um dos autores deste material sugeriu a adição de uma imagem para ilustrar o método de Fletcher-Reeves.
Uma outra versão é a seguinte:
Primeiro passo: Tomar
Se , então pare:
Senão: (como em todo método de descida)
Calcular , através de uma busca linear
Passo iterativo:
Se , então pare:
Senão:
Calcular , através de uma busca linear
Um dos autores deste material sugeriu a adição de uma implementação do algoritmo acima em SciLab.
Exercício
Verificar que, no caso de uma função quadrática e fortemente convexa, os algoritmos de Hestenes-Stiefel, de Fletcher-Reeves e de Polak-Ribière são os mesmos.
Exercício
Seja . Implemente o método de gradientes conjugados, e utilize o algoritmo para determinar o ponto de mínimo da função . Note que o espaço é unidimensional, então o método de gradientes conjugados reduz-se ao método dos gradientes, com primeira direção . Observe ainda que é uma função coerciva fortemente convexa.
Para o caso de funções não quadráticas, é preciso usar algum método de busca linear para a implementação do método dos gradientes conjugados, seja a versão de Fletcher-Reeves ou a de Polak-Ribière. Uma possibilidade é a busca de linear de Armijo (ver Izmailov & Solodov (2007), vol 2, pag. 65), cujo algoritmo é esboçado a seguir:



![{\displaystyle t\in \left[0,1\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fd270c3bd356bcd89e081db8a147db4ac9552d8)

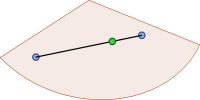 Este é um conjunto convexo, pois todo segmento com extremidades no conjunto está totalmente contido no conjunto.
Este é um conjunto convexo, pois todo segmento com extremidades no conjunto está totalmente contido no conjunto. Este é um conjunto côncavo, pois existe um segmento com extremidades no conjunto que não está totalmente contido no conjunto.
Este é um conjunto côncavo, pois existe um segmento com extremidades no conjunto que não está totalmente contido no conjunto.


![{\displaystyle \forall t\in \left[0,1\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/710780acdb88127978532c76ffa317c7b45c7d5f)


















































































































































