
Processamento de Dados Massivos/Projeto e implementação de aplicações Big Data/API para processamento estatístico
Descrição da Aplicação
[editar | editar código-fonte]Denominação
[editar | editar código-fonte]API para processamento estatísticos em grandes volumes de dados
Contexto
[editar | editar código-fonte]Extrair informações estatísticas de bases de dados é uma tarefa bastante comum. Bancos relacionais já trazem em suas implementações suporte a diversas funções, tais como soma, média, contabilização, etc.
Em se tratando de grandes volumes de dados, tarefas dessa natureza também são de grande importância. Existem algumas implementações que facilitam essa tarefa, como é o caso do Hive[1] e Pig[2], dentre outros. Entretanto, o usuário é obrigado a conhecer detalhes de tecnologias muitas vezes diferentes daquelas que está habituado. Neste contexto, a API aqui proposta visa prover uma série de funções para processamentos estatísticos em grandes volumes de dados, oferecendo ao usuário uma interface bastante simples.
São providas funções corriqueiras como soma, máximo, mínimo, média, desvio padrão e contagem, bem como funções mais elaboradas como particionamento de base, divisão em quantis e criação de tabela de contingência N-dimensional.
Um caso particular de uso é a o processamento da base de dados do SUS para produção de indicadores com vários recortes diferentes, ou ainda sua divisão para validação de algoritmos em um contexto reduzido.
Algoritmo
[editar | editar código-fonte]Os algoritmos aqui descritos operam sobre uma ou mais das seguintes variáveis:
T - base de dados com as transações;
f - condição de filtragem, utilizada para limitar um escopo de trabalho na base T;
i - atributo (ou dimensão) da base T que será alvo do processamento;
i_t - valor do atributo i na transação t;
g - atributos (ou dimensões) que serão usados para geração de agrupamentos. Quando aplicável, cada tupla de valores distintos de g na base T será considerada como critério para agrupamento de registros.
g_i(i=1..N) - cada uma das N tuplas distintas de g na base T. Se g for indefinido, então todo t E T será considerado pertencente a um mesmo grupo g_1.
Máximo
[editar | editar código-fonte]Maior valor assumido pelo atributo i na base T em cada grupo g, limitando as transações t àquelas que atendem ao critério f.
função máximo(T, i, g, f)
máximo[g_k(k=1..N)] <= VAZIO
para cada t E T | t atende a f
se i_t > máximo[g_k | t E g_k] então
máximo[g_k] <= i_t
fim se
fim para
fim função
Mínimo
[editar | editar código-fonte]Menor valor assumido pelo atributo i na base T em cada grupo g, limitando as transações t àquelas que atendem ao critério f.
função mínimo(T, i, g, f)
mínimo[g_k(k=1..N)] <= VAZIO
para cada t E T | t atende a f
se i_t < mínimo[g_k | t E g_k] então
mínimo[g_k] <= i_t
fim se
fim para
fim função
Soma
[editar | editar código-fonte]Soma de todos os valores assumidos pelo atributo i na base T para cada grupo g, limitando as transações t àquelas que atendem ao critério f.
função soma(T, i, g, f)
soma[g_k(k=1..N)] <= 0
para cada t E T | t atende a f
soma[g_k | t E g_k] += i_t
fim para
fim função
Média
[editar | editar código-fonte]Média dos valores assumidos pelo atributo i na base T em cada grupo g, limitando as transações t àquelas que atendem ao critério f.
função média(T, i, g, f)
soma[g_k(k=1..N)] <= 0
elementos[g_k(k=1..N)] <= 0
para cada t E T | t atende a f
soma[g_k | t E g_k] += i_t
elementos[g_k | t E g_k] ++
fim para
para cada k (1..N)
média[g_k] <= soma[g_k] / elementos[g_k]
fim para
fim função
Contagem
[editar | editar código-fonte]Conta o número de transações t que estão agrupadas em cada grupo g_i, limitando estas transações à apenas aquelas que atendem ao critério f.
função conta(T, g, f)
conta[g_k(k=1..N)] <= 0
para cada t E T | t atende a f
conta[g_k | t E g_k] ++
fim para
fim função
Desvio padrão
[editar | editar código-fonte]Desvio padrão dos valores assumidos pelo atributo i na base T em cada grupo g, limitando as transações t àquelas que atendem ao critério f.
função desvio(T, i, g, f)
diferençaQuadrado[g_k(k=1..N)] <= 0
média(T, i, g, f)
para cada t E T | t atende a f
diferençaQuadrado[g_k | t E g_k] += (i_t - média[g_k])^2
elementos[g_k | t E g_k] ++
fim para
para cada k (1..N)
desvio[g_k] <= raizQuadrada(diferençaQuadrado[g_k] / elementos[g_k])
fim para
fim função
Particionamento
[editar | editar código-fonte]Particionamento da base em subconjuntos determinados por cada cada grupo g_i, limitando as transações t àquelas que atendem ao critério f. Cada grupo g_i gera uma nova base, composta por todas as transações contida no grupo g_i.
função particiona(T, g, f)
particao[g_k(k=1..N)] <= VAZIO
para cada t E T | t atende a f
particao[g_k | t E g_k] += t
fim para
fim função
Quantis
[editar | editar código-fonte]Particionamento das transações da base T que atendem ao critério f em subconjuntos, de forma que o intervalo entre o valor mínimo e máximo para o atributo i é dividido em q faixas e cada transação t é alocada no subconjunto equivalente á faixa que se enquadra i_t.
função quantis(T, q, i, f)
minimo = min(T, q, i, f)
máximo = max(T, q, i, f)
f = divide(máximo - mínimo, q)
quantis[f_k(k=1..q)] <= VAZIO
para cada t E T | t atende ao critério f
quantis[f_k | f_(k-1) < i_t <= f_k] += t
fim para
fim função
Contingência
[editar | editar código-fonte]Gera a tabela de contingência[3] e as margens para as transações t E T que atendem ao critério f, considerando os atributos definidos em g.
função contingência(T, g, f)
contingência[g_k(k=1..N)] <= 0
para cada t E T | t atende a f
contingência[g_k | t E g_k] ++
fim para
para cada s | s é subconjunto próprio de g_k(k=1..N)
margem[s] = 0
para cada k (1..N)
se g_k contém s então
margem[s] += contingência[g_k]
fim se
fim para
fim para
fim função
Exemplo de Funcionamento
[editar | editar código-fonte]Considerando a base de dados T a seguir:
| UF | SEXO | ANO | PROCEDIMENTO AMBULATORIAL | VALOR |
|---|---|---|---|---|
| MG | M | 2010 | A | 10 |
| MG | M | 2011 | B | 2 |
| MG | F | 2010 | C | 4 |
| SP | F | 2010 | A | 10 |
| SP | F | 2010 | A | 10 |
| SP | F | 2011 | B | 2 |
| MT | M | 2011 | B | 2 |
| MT | F | 2011 | C | 4 |
| MS | F | 2010 | A | 10 |
| RS | F | 2010 | B | 2 |
As saídas para cada comando são:
máximo(T, VALOR, {UF, SEXO}, {PROCEDIMENTO = A})
[editar | editar código-fonte]| UF | SEXO | VALOR |
|---|---|---|
| MG | M | 10.0 |
| MS | F | 10.0 |
| SP | F | 10.0 |
mínimo(T, VALOR, {UF, ANO}, NULL)
[editar | editar código-fonte]| UF | ANO | VALOR |
|---|---|---|
| MG | 2010 | 4.0 |
| MG | 2011 | 2.0 |
| MS | 2010 | 10.0 |
| MT | 2011 | 2.0 |
| RS | 2010 | 2.0 |
| SP | 2010 | 10.0 |
| SP | 2011 | 2.0 |
soma(T, VALOR, {UF, ANO}, {PROCEDIMENTO EM (A, C)})
[editar | editar código-fonte]| UF | ANO | SOMA |
|---|---|---|
| MG | 2010 | 14.0 |
| MS | 2010 | 10.0 |
| MT | 2011 | 4.0 |
| SP | 2010 | 20.0 |
média(T, VALOR, {UF}, NULL)
[editar | editar código-fonte]| UF | MÉDIA |
|---|---|
| MG | 5.33 |
| MS | 10.0 |
| MT | 3.0 |
| RS | 2.0 |
| SP | 7.33 |
desvio(T, VALOR, {UF}, NULL)
[editar | editar código-fonte]| UF | DESVIO |
|---|---|
| MG | 5.89 |
| MS | 0.0 |
| MT | 1.41 |
| RS | 0.0 |
| SP | 6.53 |
conta(T, {PROCEDIMENTO}, {ANO = 2010})
[editar | editar código-fonte]| PROCEDIMENTO | OCORRÊNCIAS |
|---|---|
| A | 4 |
| B | 1 |
| C | 1 |
particiona(T, {UF, PROCEDIMENTO}, NULL)
[editar | editar código-fonte]| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MT | F | 2011 | C | 4 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MT | M | 2011 | B | 2 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MS | F | 2010 | A | 10 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MG | F | 2010 | C | 4 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MG | M | 2010 | A | 10 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MG | M | 2011 | B | 2 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| SP | F | 2010 | A | 10 |
| SP | F | 2010 | A | 10 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| SP | F | 2011 | B | 2 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| RS | F | 2010 | B | 2 |
quantis(T, 3, VALOR, NULL)
[editar | editar código-fonte]Nesse exemplo, uma faixa ficou sem representantes
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MG | M | 2010 | A | 10 |
| SP | F | 2010 | A | 10 |
| SP | F | 2010 | A | 10 |
| MS | F | 2010 | A | 10 |
| UF | SEXO | ANO | PROCEDIMENTO | VALOR |
|---|---|---|---|---|
| MG | M | 2011 | B | 2 |
| MG | F | 2010 | C | 4 |
| SP | F | 2011 | B | 2 |
| MT | M | 2011 | B | 2 |
| MT | F | 2011 | C | 4 |
| RS | F | 2010 | B | 2 |
contingência(T, {UF, PROCEDIMENTO, ANO}, NULL)
[editar | editar código-fonte]Tabela de contingência
| UF | PROCEDIMENTO | ANO | OCORRÊNCIAS |
|---|---|---|---|
| MG | A | 2010 | 1 |
| MG | B | 2011 | 1 |
| MG | C | 2010 | 1 |
| MS | A | 2010 | 1 |
| MT | B | 2011 | 1 |
| MT | C | 2011 | 1 |
| RS | B | 2010 | 1 |
| SP | A | 2010 | 2 |
| SP | B | 2011 | 1 |
Margens da dimensão PROCEDIMENTO
| PROCEDIMENTO | OCORRÊNCIAS |
|---|---|
| A | 4 |
| B | 4 |
| C | 2 |
Margens da dimensão UF
| UF | OCORRÊNCIAS |
|---|---|
| MG | 3 |
| MS | 1 |
| MT | 2 |
| RS | 1 |
| SP | 3 |
Margens da dimensão ANO
| ANO | OCORRÊNCIAS |
|---|---|
| 2010 | 6 |
| 2011 | 4 |
Margens das dimensões UF e ANO
| UF | ANO | OCORRÊNCIAS |
|---|---|---|
| MG | 2010 | 2 |
| MG | 2011 | 1 |
| MS | 2010 | 1 |
| MT | 2011 | 2 |
| RS | 2010 | 1 |
| SP | 2010 | 2 |
| SP | 2011 | 1 |
Margens das dimensões PROCEDIMENTO e ANO
| PROCEDIMENTO | ANO | OCORRÊNCIAS |
|---|---|---|
| A | 2010 | 4 |
| B | 2010 | 1 |
| B | 2011 | 3 |
| C | 2010 | 1 |
| C | 2011 | 1 |
Margens das dimensões UF e PROCEDIMENTO
| UF | PROCEDIMENTO | OCORRÊNCIAS |
|---|---|---|
| MG | A | 1 |
| MG | B | 1 |
| MG | C | 1 |
| MS | A | 1 |
| MT | B | 1 |
| MT | C | 1 |
| RS | B | 1 |
| SP | A | 2 |
| SP | B | 1 |
Requisitos
[editar | editar código-fonte]Escalabilidade
[editar | editar código-fonte]As implementações não impõem limite ao volume de dados que são capazes de processar e nem ao número de nós de processamento. Por funcionar sobre a plataforma Hadoop, a escalabilidade da biblioteca depende diretamente da escalabilidade deste último.
Tolerância a falhas
[editar | editar código-fonte]As implementações fornecem o mesmo nível de tolerância a falhas que o sistema de arquivos distribuído HDFS do Hadoop.
Armazenamento
[editar | editar código-fonte]As bases de dados a serem processadas ficam armazenadas no HDFS, que é, por natureza, um sistema de arquivos distribuído construído principalmente para facilitar o acesso aos dados pelos nós de processamento do cluster Hadoop.
Latência
[editar | editar código-fonte]Os algoritmos implementados são pensados para trabalhar em batch, não sendo recomendados para processamento em tempo real, como é comum em operações estatísticas de sistema de banco de dados.
Paralelizações existentes
[editar | editar código-fonte]Tabela de contingência.[4]
Divisão em quantis.[5]
Projeto
[editar | editar código-fonte]Oportunidades de paralelização
[editar | editar código-fonte]As funções de agregação simples, tais como máximo, mínimo, soma, contagem e média (soma/contagem) são trivialmente paralelizáveis, uma vez que é possível dividir o conjunto de dados, executar o algoritmo de forma independente sobre cada conjunto, e promover a junção dos resultados parciais. Isto torna o processamento escalável, bastando aumentar o número de nós para comportar um maior volume de dados ou melhorar a performance.
O cálculo do desvio padrão envolve o cálculo da média e posterior cálculo da diferença quadrática de cada elemento para a média. Os dois passos devem ser sequenciais, pois não se pode calcular a diferença antes que a média seja conhecida. No entanto, a média pode ser obtida de forma paralela, bem como a diferença. Neste último caso, a base pode ser distribuída e cada nó é informado do valor da média. Cada nó pode trabalhar de forma independente sobre seu conjunto de dados, produzindo as diferenças quadráticas que, numa fase de redução, servião na composição do cálculo do desvio.
O particionamento também é passível de paralelização, dado que a base de dados pode ser dividida e cada parte pode ser processada de forma independente, separando os registros em cada partição. Um ponto importante a ser levantado aqui é que a quantidade de dados escritos é igual á quantidade de dados lidos, ao contrário das funções de agregação que exigem muito mais leitura que escrita. Haverá aqui uma concorrência na escrita dos registros, já que vários processos podem alimentar uma mesma partição.
Similarmente, a tabela de contingência pode ser construída a partir do processamento independente de blocos da base de dados e posterior junção. As margens podem ser computadas à medida que a tabela é materializada para minimizar comunicação entre os nós, uma vez que os atributos já estarão previamente agrupados.
Para a divisão da base em quantis são necessários dois passos: o primeiro para calcular as faixas de cada quantil e o segundo para separação efetiva dos dados nos respectivos slots. Por serem passos dependentes, devem ser executados de forma sequencial. Entretanto, cada um dos passos pode ser paralelizado. O cálculo das faixas para os quantis passa pela soma e posterior divisão pelo número de faixas. A maior parte da computação, que é a soma, conforme observado anteriormente, pode ser paralelizada. A separação dos registros em quantis pode ser distribuída quebrando-se a base em partes menores e distribuindo aos nós, juntamente com as faixas dos quantis. Cada nó pode processar o que lhe cabe e dar a saída no quantil correto. A escrita deve ser controlada, já que vários processos podem concorrer nesse momento. Também aqui é importante observar que o número de registros lidos e escritos são idênticos, salvo pela utilização de filtros.
Padrões de acesso aos dados
[editar | editar código-fonte]Em todos os casos não há dependência no acesso aos dado visto que são totalmente distribuídos e processados exclusivamente pelos respectivos nós. Há concorrência, em alguns casos, na escrita dos dados. Isso pode ser um gargalo, já que este fenômeno ocorre justamente nas funções que dão saídas a um maior número de registros.
Padrões de comunicação
[editar | editar código-fonte]Nas funções de agregação simples, particionamento e contingência não há necessidade de comunicação entre os nós durante a leitura e processamento, tampouco na fase de agregação.
O particionamento é capaz de escrever no arquivo de saída à medida que os registros são lidos, sendo desnecessárias as comunicações entre os nós (exceto entre os produtores e consumidores).
Para o cálculo do desvio padrão é necessário comunicar o valor da média a todos os nós para que possam, assim, iniciar o processamento.
No caso da divisão em quantis, as faixas claculadas na primeira passada devem ser repassadas a todos os nós, ponto a partir do qual a alocação dos registros poderá ser iniciada.
Linha do tempo integrada
[editar | editar código-fonte]



Desenvolvimento
[editar | editar código-fonte]Estratégias de paralelização
[editar | editar código-fonte]Em todas as funções há uma forte caraterística de paralelismo de dados, já que estes são distribuídos. Em nenhuma situação foi observado paralelisme de tarefas sobre os mesmo dados.
Estratégias de armazenamento
[editar | editar código-fonte]O produto das funções é armazenado em disco. Nos casos dos quartis e do desvio padrão, os valores calculados no primeiro passo são deixados em memória primária.
Estratégias de comunicação
[editar | editar código-fonte]Nos casos onde a comunicação é necessária, o agregador dispara todos os leitores do segundo passo já com os valores necessários para os próximos cálculos (média, no desvio padrão e faixas, na divisão em quantis).
Implementação
[editar | editar código-fonte]Plataformas e ferramentas
[editar | editar código-fonte]A solução é implementada sobre as plataformas Hadoop[6] e Pig[2], além de fazer uso da biblioteca DataFu[7].
A linguagem Pig Latin facilita a construção de programas na arquitetura MapReduce de uma forma limpa e intuitiva, sem a necessidade de escrever diretamente as funções map e reduce. Funções como foreach encapsulam mapeamentos, enquanto construções group by mascaram as reduções. No caso de utilização de vários mapeamentos e reduções, a plataforma Pig colabora também na otimização da troca de mensagens. Outro ponto a se considerar aqui é a facilidade de construção e depuração das funções, visto que é possível fazer execução local sem a necessidade de iniciar toda a estrutura Hadoop/HDFS, isto de uma forma bastante transparente.
Soluções com utilização da arquitetura MapReduce diretamente e também da plataforma Hive foram avaliadas. No entanto, a facilidade de desenvolvimento e de manipulação de arquivos oferecidas pelo Pig pesaram a seu favor.
A API é construída na linguagem Java, utilizando a ferramenta Maven[8] para gerenciar o ciclo de vida do desenvolvimento. Isso possibilita que o módulo seja facilmente incluído como dependência em outros projetos dessa natureza. É possível, ainda, sua utilização em projetos Java que não seguem a estrutura definida pelo Maven e também como programa stand alone.
Integração de plataformas e ferramentas
[editar | editar código-fonte]A API não necessita ser executada diretamente sobre a plataforma Hadoop; a própria plataforma Pig se encarrega de reconhecer e disparar os jobs.
As bases de dados são arquivos CSV carregados no HDFS, utilizando como separador o caracter ponto e vírgula. O próprio sistema de arquivos já faz a distribuição dos blocos entre os diversos nós. Os mapeadores leem dos nós mais próximos e consomem os blocos, comunicando o resultado aos redutores via arquivo no mesmo sistema de arquivos. Nos casos onde são necessárias duas fases de leitura, o final da primeira fase de agregação já dispara os novos mapeamentos, repassando as informações solicitadas ao passo seguinte. O controle da escrita concorrente em arquivos é feita pelo próprio HDFS.
Detalhes de implementação
[editar | editar código-fonte]A função para divisão em quantis utiliza a função de quantis do DataFu para o cálculo das faixas.\
Apesar de várias dessas funções estarem disponíveis ou serem facilmente alcançáveis com a utilização de plataformas como Hive e Pig, a API oculta os detalhes de baixo nível da distribuição, podendo ser utilizada por qualquer desenvolvedor que tenha os conhecimentos básicos de orientação por objeto.
Avaliação
[editar | editar código-fonte]Carga de trabalho
[editar | editar código-fonte]O desempenho da API desenvolvida foi avaliado através da aplicação de suas funcionalidades para analisar uma base de dados de grandes dimensões. Esta base contém centenas de milhões de registros, e a análise estatística destes não é viável utilizando uma abordagem não distribuída.
A fim de avaliar também a escalabilidade da API para bases de dados de tamanhos variados, a base de dados original foi subdividida em várias bases menores. Essa subdivisão permite avaliar o padrão de complexidade das funcionalidades disponibilizadas pela API.
Avaliação experimental
[editar | editar código-fonte]A análise da API foi realizada através de múltiplas execuções de cada uma de suas funcionalidades sobre as bases de dados de diversos tamanhos. Para cada uma das execuções foi analisado o tempo de execução, quantidade de dados lidos e a quantidade de maps e reducers executados.
As funcionalidades testadas estão listadas a seguir, contudo é importante destacar que somente algumas das funcionalidades de agregação foram testadas, pois a maioria possui complexidade semelhante.
- Média
- Soma
- Desvio
- Quantis
- Contingência
- Particionamento
Cada uma das funcionalidades foi testada através de sua execução sobre bases de dados de diversos tamanhos.
Cálculo da média
[editar | editar código-fonte]-
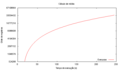 Tempo de execução
Tempo de execução -
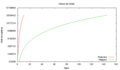 Número de tarefas
Número de tarefas


Divisão em cinco quantis
[editar | editar código-fonte]-
 Tempo de execução
Tempo de execução -
 Número de tarefas
Número de tarefas


Cálculo do desvio padrão
[editar | editar código-fonte]-
 Tempo de execução
Tempo de execução -
 Número de tarefas
Número de tarefas


Geração da tabela de contingência para três atributos
[editar | editar código-fonte]-
 Tempo de execução
Tempo de execução -
 Número de tarefas
Número de tarefas


Particionamento por três atributos
[editar | editar código-fonte]-
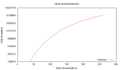 Tempo de execução
Tempo de execução -
 Número de tarefas
Número de tarefas


Análise de resultados
[editar | editar código-fonte]Os resultados foram obtidos com variação apenas do tamanho da entrada. Outra condição interessante de ser observada é a variação do número de nós de processamento, o que deveria ser feito em trabalhos futuros.
Em todos os casos, é interessante observar o comportamento linear com tendência assintótica dos algoritmos a partir de um determinado volume de registros (4000000, no caso da média). Ademais, o número de mapeadores é sempre significativamente maior que o número de redutores.
Análise Crítica
[editar | editar código-fonte]O comportamento linear assintótico nas funções de agregação sugere que o cluster tende a trabalhar próximo ao seu limite de processamento ao se aumentar o tamanho da entrada. A adição de mais nós, no caso de aumento de dados, deverá subir o limite assintótico, melhorando o desempenho.
O Hadoop assume que as reduções deverão agregar dados, consumindo muito e produzindo pouco. Por esta razão, o número de redutores é significativamente menor que o de mapeadores. Isso é válido para grande parte das funções, mas não é uma assumpção válida para as funções de geração de quantis e particionamento. É possível que o desempenho seja melhorada nesses casos com um melhor balanceamento das tarefas.
Codigo Fonte
[editar | editar código-fonte]O código fonte pode ser encontrado aqui, podendo ser usado e distribuído livremente.