Se você for imprimir esta página, escolha "Visualizar impressão" no seu navegador, ou clique em Versão para impressão, você irá ver esta página sem esse aviso, sem os elementos de navegação a esquerda ou acima, e sem as TOC's de cada página.
Atualize esta página para ter certeza de que está imprimindo a versão mais atual.
Para maiores informações sobre a versão para impressão, incluindo como fazer arquivos PDF realmente adequados para a impressão, veja Wikilivros:Versões para impressão.
Este material está sendo elaborado com base nas notas de aula da disciplina Otimização II, do curso de Matemática Industrial oferecido pela UFPR, ministrada pelo professor Wilfredo, no segundo semestre letivo do ano de 2008.
O conteúdo do livro não precisa (nem deve) se limitar àquele que consta atualmente no índice. Sendo assim, a qualquer momento o livro pode ser revisto e ampliado.
Sinta-se a vontade para ler este ou quaisquer outros livros do projeto, melhorando-os conforme lhe for possível. Com isso estará ajudando a aumentar a quantidade e a qualidade dos textos didáticos disponíveis em língua portuguesa, ao mesmo tempo em que colaborará com o crescimento projeto Wikilivros como um todo.
Se tiver dúvidas ou sugestões sobre páginas específicas, utilize as páginas de discussão correspondentes para deixar um comentário a respeito.
Ainda há muito por fazer, mas cada um daqueles que contribuem acredita estar fazendo o possível para oferecer o melhor a todos.
Este é um conjunto convexo, pois todo segmento com extremidades no conjunto está totalmente contido no conjunto.
Este é um conjunto côncavo, pois existe um segmento com extremidades no conjunto que não está totalmente contido no conjunto.
Definição
Uma função é dita convexa quando é convexo e e vale
Definição
Dado um conjunto convexo , uma função é dita fortemente convexa quando existe uma constante tal que é convexa.
Exercício
Verifique que uma função quadrática é fortemente convexa se existe uma matriz simétrica definida positiva , um vetor e um escalar de modo que .
Resolução
Sendo uma função quadrática, tem-se . A matriz pode ser suposta simétrica, pois caso não seja, toma-se (simétrica), e segue (verifique).
Além disso, se é uma função fortemente convexa, então é estritamente convexa. Como é duas vezes diferenciável (por ser uma função quadrática), a convexidade estrita implica que é definida positiva.
Nota: Uma matriz é definida positiva se, e somente se, todos os seus autovalores são positivos.
Tem-se:
Sendo , segue em particular que e , onde é uma matriz diagonal cujos elementos da diagonal são os autovalores de e é uma matriz onde as colunas são os autovetores correspondentes aos autovalores.
Note que é uma matriz simétrica, pois é a matriz Hessiana de uma função com segundas derivadas parciais contínuas, e consequentemente vale .
Para introduzir o método de direções conjugadas, serão consideradas somente funções quadráticas.
Uma condição necessária de primeira ordem para que seja um ponto de mínimo para a função é que . Para o presente caso, a função é convexa, então, a condição necessária também é suficiente.
Exercício
Prove que se é uma matriz simétrica definida positiva, então dada por possui um único ponto de mínimo.
Resolução
Uma vez que é simétrica definida positiva, a função é fortemente convexa. Mas toda função fortemente convexa, definida em um conjunto fechado não vazio possui um único minimizador, pois:
Os conjuntos de nível de uma função fortemente convexa são compactos;
Toda função contínua definida em um compacto tem algum minimizador (pelo teorema de Weierstrass);
Os minimizadores de uma função convexa são globais;
Funções fortemente convexas não podem ter mais de um minimizador.
Em particular, possui um único ponto de mínimo.
No caso de uma função quadrática, tem-se , ou seja, é solução do sistema linear .
A resolução de um sistema linear nem sempre pode ser feita numericamente de forma eficiente. Por exemplo, se a matriz do sistema é:
A solução do sistema linear corresponde à interseção entre duas retas quase paralelas, e os erros de truncamento podem causar imprecisão na solução obtida computacionalmente.
Analiticamente, o sistema tem como solução. Então alguém poderia se perguntar: qual o problema em resolver esse sistema linear, se basta calcular a inversa da matriz e multiplicar pelo vetor ? A resposta é que o calculo da inversa de uma matriz em geral é impraticável computacionalmente, por ter custo muito alto. Por isso, nas situações práticas, onde as matrizes tem ordem bem maior do que 2 (digamos 1000), o cálculo de matrizes inversas não é uma opção.
Assim, com o intuito de desenvolver um método computacional para o cálculo de minimizadores, é preciso utilizar outras técnicas. Considere o seguinte:
Em um método de descida tem-se sempre uma sequencia , com e é um minimizador de
e
Logo, e multiplicando por obtem-se . Consequentemente, o valor de é dado por
Deste modo, o método consistirá de escolher em cada etapa uma direção , e calcular o coeficiente pela fórmula anterior, para gerar o próximo ponto . Mas como escolher a direção ?
Dado e escolhido , defina como , ou seja, é a restrição da função à reta que passa pelo ponto e que tem direção . Logo, derivando a expressão de em relação a , obtem-se
Então, no ponto de mínimo, , tem-se
Ou seja, a direção a ser seguida a partir do ponto é ortogonal ao gradiente da função , no ponto .
Uma comparação da convergência do método de descida do gradiente com tamanho de passo ótimo (em verde) e o método do gradiente conjugado (em vermelho) para a minimização da forma quadrática com um sistema linear dado. O gradiente conjugado, assumindo aritmética exata, converge em no máximo n passos onde n é o tamanho da matriz do sistema (no exemplo, n=2).
Primeiro passo: Escolha
Se , então pare:
Senão:
Calcular Passo iterativo : Dado
Se , então pare:
Senão:
Pode-se verificar facilmente que . De fato, como , tem-se . Logo, .
Exercício
Provar que se então .
Resolução
Tem-se
Multiplicando ambos os membros por , e trocando de lugar com resulta:
Considere definida por .
Em outros termos, tomando , tem-se , onde .
Pode-se aplicar o método de direções conjugadas ao seguinte problema
Note, desde já, que o conjunto solução é .
Inicio
Toma-se arbitrário, por exemplo, .
Avalia-se o gradiente da função neste ponto inicial:
Iteração 1
A seguir, verifica-se se o gradiente se anula no novo ponto :
Como o gradiente já é nulo, não é preciso fazer a segunda iteração, e o ponto é o (único) minimizador global de .
Em um caso mais geral, considerando definida por , tem-se cálculos muito parecidos em cada passo.
O conjunto solução continua sendo .
Inicio
Considere como no primeiro exemplo, ou seja, .
Avalia-se o gradiente da função neste ponto inicial:
Iteração 1
A seguir, verifica-se se o gradiente se anula no novo ponto :
Novamente, o gradiente se anula já na primeira iteração, de modo que é o minimizador global de .
Exercício
Seja uma matriz simétrica definida positiva, cujos autovalores são todos iguais. Então começando de qualquer ponto , o método fornece como solução.
Um terceiro exemplo pode ser dado tomando e definida por . Observe que tal matriz é simétrica e definida positiva:
Logo, os autovalores de são e . Isso também implica que a função é fortemente convexa.
Aplicando o método:
Início
Toma-se um ponto arbitrário no plano, por exemplo ;
Verifica-se se tal ponto é o minimizador global, avaliando nele o gradiente da função:
.
Já que o gradiente não se anulou no chute inicial, é preciso escolher uma direção e um comprimento de passo para determinar a próxima aproximação:
Iteração 1
Feitos esses cálculos, o próximo ponto é dado por
Para saber se será necessária uma nova iteração, ou se o minimizador foi encontrado, calcula-se o gradiente da função no ponto:
.
Novamente, será preciso calcular uma nova direção e um novo comprimento de passo:
Iteração 2
onde , no algoritmo de Hestenes é dado por:
Portanto
Além disso, o tamanho do passo é dado por
Portanto
Obviamente, este é o minimizador procurado (pois o método tem a propriedade de convergência quadrática, ou seja utiliza no máximo iterações para chegar a solução quando aplicado a funções quadráticas definidas em )
Exercício
Implementar o algoritmo de Hestenes-Stiefel em alguma linguagem de programação, por exemplo em Scilab, ou Matlab.
Exercício
Seja um função quadrática fortemente convexa. Verifique as seguintes igualdades:
Para facilitar a compreensão do método, pode ser útil exibir as curvas de nível da função. Uma forma de implementar uma função com esse propósito é a seguinte:
Um dos autores deste material sugeriu a adição de uma imagem para ilustrar o método de Fletcher-Reeves.
Esta versão é na verdade uma extensão do algoritmo anterior, permitindo a aplicação no caso de funções que não são quadráticas.
Primeiro passo: Escolha
Se , então pare:
Senão: (como em todo método de descida)
Calcular , através de uma busca linear
Passo iterativo:
Se , então pare:
Senão:
Calcular , através de uma busca linear
Um dos autores deste material sugeriu a adição de uma implementação do algoritmo acima em SciLab.
Um dos autores deste material sugeriu a adição de uma imagem para ilustrar o método de Fletcher-Reeves.
Uma outra versão é a seguinte:
Primeiro passo: Tomar
Se , então pare:
Senão: (como em todo método de descida)
Calcular , através de uma busca linear
Passo iterativo:
Se , então pare:
Senão:
Calcular , através de uma busca linear
Um dos autores deste material sugeriu a adição de uma implementação do algoritmo acima em SciLab.
Exercício
Verificar que, no caso de uma função quadrática e fortemente convexa, os algoritmos de Hestenes-Stiefel, de Fletcher-Reeves e de Polak-Ribière são os mesmos.
Exercício
Seja . Implemente o método de gradientes conjugados, e utilize o algoritmo para determinar o ponto de mínimo da função . Note que o espaço é unidimensional, então o método de gradientes conjugados reduz-se ao método dos gradientes, com primeira direção . Observe ainda que é uma função coerciva fortemente convexa.
Para o caso de funções não quadráticas, é preciso usar algum método de busca linear para a implementação do método dos gradientes conjugados, seja a versão de Fletcher-Reeves ou a de Polak-Ribière. Uma possibilidade é a busca de linear de Armijo (ver Izmailov & Solodov (2007), vol 2, pag. 65), cujo algoritmo é esboçado a seguir:
Para contornar a desvantagem da descontinuidade da função apresentada anteriormente, surgem outras funções, como por exemplo:
Gráfico de uma função de penalidade
Definição
Dada uma função , definida em um conjunto arbitrário , define-se a parte positiva de , como:
Um dos autores deste material sugeriu a adição de uma imagem para comparar uma função e sua correspondente .
Exercício
Verifique que para cada tem-se, para cada , a igualdade , onde é a parte positiva de e é a função definida no exemplo anterior.
Resolução
De fato, dada qualquer função , segue da própria definição de que
Mas
implica que
Portanto, . Como pode ser tomada arbitrariamente, tem-se em particular que .
Exercício
Verifique que para cada tem-se, para cada , a igualdade .
Um dos autores deste material sugeriu conferir o enunciado do exercício anterior. A afirmação parece ser falsa nos casos em que .
A idéia de aplicar penalizações aos pontos que não pertencem ao conjunto viável é formalizada na seguinte definição:
Definição
Seja . A função é chamada de função de penalidade exterior se possui as seguintes propriedades:
é contínua
Nota: Lembre-se que é o conjunto viável do problema (P).
Em particular, as funções são funções de penalidade exterior.
Definição
Seja . A função é dita coerciva se
Um dos autores deste material sugeriu a adição de exemplos de funções de penalidade, juntamente com algumas imagens ilustrando os seus gráficos.
Nota: Conforme o Wikcionário, o termo coercivo significa: que coage; que reprime; que impõe pena; coercitivo. Nesse sentido, esse é um termo adequado ao tratar do conceito anterior, no contexto dos métodos de penalidade.
Exercício
Verifique que é uma função coerciva se, e somente se, é limitado para todo .
Resolução
Pela definição de limite, a afirmação
é equivalente a dizer que
tal que tem-se .
Esta última implicação, é equivalente à
(sua contrapositiva).
Pela definição de conjunto de nível, isso equivale à . A existência de um número com tal propriedade significa que é um conjunto limitado, donde conclui-se a equivalência entre coercividade e limitação dos conjuntos de níveis
Um dos autores deste material sugeriu a adição de uma imagem que ilustre geometricamente a relação entre coercividade e conjuntos de nível.
Exercício
Verifique que definida por é uma função de penalidade exterior, onde conforme anteriormente, é a parte positiva de .
Resolução
Primeiramente, é uma função não negativa, pois o quadrado de qualquer número real é não negativo, assim como a soma de números reais não negativos.
Em segundo lugar, tem-se se, e somente se, para cada índice e cada índice vale e . Como , tem-se
Finalmente, como a soma e o produto de funções contínuas resulta em uma função contínua, segue que é contínua, pois são contínuas.
Exercício
Verifique que se é uma função contínua coerciva, então existe tal que .
Resolução
Considere um ponto arbitrário . Tome . Nestas condições, é limitado (conforme um dos exercícios anteriores) e fechado (pois é pré-imagem de um conjunto fechado por uma função contínua), portanto compacto. Neste caso, conforme o teorema de Weierstrass, a função possui algum ponto de mínimo no conjunto , ou seja, existe tal que .
Ne verdade, tal ponto é também um minimizador global da função , pois se então (pela definição do conjunto ).
Um dos autores deste material sugeriu a adição de uma imagem ilustrando a existência de minimizadores globais para funções coercivas.
Em algumas situações, é interessante ter em mente que certos conceitos definidos no contexto da Otimização são, na verdade, instanciações de conceitos mais gerais, muitos deles provenientes da topologia. Alguns exemplos são apresentados a seguir.
Definição
Dado um conjunto , uma coleção de subconjuntos de é chamada de topologia se:
Exemplos
Topologia euclidiana:
Em outras palavras, a topologia euclideana é a coleção de todos os conjuntos abertos contidos em . Pode-se verificar com facilidade que de fato são satizfeitas as três propriedades que definem uma topologia.
Outro exemplo muito comum é o seguinte:
Topologia euclideana estendida:
Em geral, a noção de limite seria caracterizada topologicamente da seguinte forma:
Uma vez apresentados os conceitos iniciais, pode-se provar o seguinte teorema:
Teorema
Considere:
uma função de penalidade exterior;
uma função contínua;
um conjunto fechado;
uma sequência de termos positivos tal que .
Suponha que é válida uma das seguintes propriedades:
é coerciva.
é limitado e é coerciva.
Se, para cada , for escolhido ,então:
possui algum ponto de acumulação;
Todo ponto de acumulação de é solução do problema (P);
.
Um dos autores deste material sugeriu a adição de uma imagem que ilustre geometricamente o significado do teorema acima.
Demonstração
Se (1) acontece, então é coerciva, pois
A desigualdade é válida pois é uma função de penalidade, portanto não negativa, e a igualdade se deve à hipotese sobre . Além de coerciva, tal função é contínua (pois é combinação linear de funções contínuas). Logo, a função possui um ponto de mínimo global, ou seja, existe tal que
, para qualquer .
Mas é contínua e coerciva, então também existe tal que
Por outro lado, se vale (2), então é contínua e C compacto. Analogamente, é contínua e compacto, donde tem-se algum tal que
Em ambos os casos, dada uma sequência tal que e , defina-se por . Logo,
Sendo que a primeira desigualdade se deve ao fato de ser um minimizador, por construção, e a segunda segue por que é decrescente. Portanto, .
Além disso, tem-se as seguintes desigualdades:
Logo, somando os membros correspondentes, obtem-se:
ou seja,
Portanto,
Por outro lado, , sendo primeira desigualdade válida por ser não negativa e positivo, e a segunda devida à própria definição de . Logo, .
Se a primeira das hipóteses acontece, segue da coercividade e dessa última desigualdade que . Então é uma sequência limitada.
Se ocorre a segunda, então é coerciva, mas foi mostrado que , consequentemente . Sendo coerciva, conclui-se novamente que é uma sequência limitada.
Portanto, em qualquer caso, possui algum ponto de acumulação.
Seja um ponto de acumulação de . Então existe tal que . Logicamente, . Pela continuidade de e sabendo que , se deduz que . Mas já havia sido verificado que , então segue a igualdade .
A sequência é crescente. Seja (por que razão ele existe?). Como , tem-se . Portanto, . Logo , ou seja, .
Como é contínua, , e este valor é nulo se, e somente se, .
Logo, , donde . Assim, tem-se , ou seja, é solução de (P).
Exercício
Dado o problema (P), considere (isso não quer dizer que o problema tenha solução). suponha-se que e são funções contínuas e que seja não vazio, ou seja, que é factível. Tome como , onde denota a parte positiva de , como de costume. Considere ainda dada por e, para cada , seja
Nessas condições, provar que:
é uma função de penalidade exterior
Se então
Se são covexas, então é convexa.
Se são diferenciáveis, então é diferenciável em , e
Se e e se é uma sequência tal que e então é solução de (P).
Este método também é conhecido como método de barreira. Ele consiste em trabalhar com funções de penalidade tais que e qualquer que seja a sequência para a qual , se tem que a função de penalidade tende a .
Um dos autores deste material sugeriu a adição de uma imagem para ilustrar uma sequência de pontos que tende a um ponto da fronteira de um conjunto C, de preferência junto com o gráfico de uma função de penalidade deste novo tipo.
Considere o seguinte problema de programação diferenciável não linear sem restrições:
onde é de classe .
Observação: Como não é necessariamente convexa, a matriz pode não ser definida positiva, apesar de ser simétrica. Neste caso, o método de Newton ou suas variantes (direções conjugadas, quase Newton, etc) não servem.
O primeiro método de região de confiança (em inglês, Trust region method), foi introduzido por Powel em 1970 (qual artigo?) mas oficialmente introduzido por Dennis em 1978 (artigo?). Ele consiste no seguinte:
A cada iteração, se constrói um modelo quadrático e uma região de confiança
este princípio pode ser considerado como uma extensão da busca de Armijo unidimensional.
Para entender a geometria do método de região de confiança, é bom lembrar a geometria da busca de Armijo unidimensional.
Seja uma direção de descida de uma função a partir do ponto . Então .
Agora, considerando , definida por , tem-se:
. Assim, . Se , então .
Exercício
Mostrar que sempre existe tal que .
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
A busca de Armijo consiste em tomar .
Se
Mas como , então existe algum tal que vale . A tal ponto, chama-se ponto de Armijo.
Introduzindo as seguinte notação
(modelo linear para a função )
(redução predita por este modelo)
(redução real no valor da função)
a pergunta é:
Quando um ponto vai ser ponto de Armijo com essa notação?
Tem-se:
Logo, se segue que é um ponto de Armijo.
Observações: Note que a essência da busca linear de Armijo é construir um modelo linear e um intervalo compacto , sendo e o ponto inicial da busca e logo procurar o ponto de Armijo em .
O método de região de confiança será uma generalização da busca de Armijo, consistindo da construção de um modelo quadrático e uma região , chamada de região de confiança, e nessa região calcular o novo iterando.
Primeiro passo: Escolha , , , e .
Passo iterativo : Enquanto , construa o modelo quadrático:
Calcule , solução de
Tome e
Se , fazer
Senão , e
Comentários: No algoritmo anterior, quando se tem um passo falho, a região de confiança sempre diminui. Seria bom incluir casos bons, onde a região deve crescer.
Primeiro passo: Escolha , , , , , e .
Passo iterativo : Enquanto , construa o modelo quadrático:
Continue = 1
Enquanto (Continue = 1)
Calcule , solução de
Tome e
Se , fazer
Se , ; Continue = 0
k = k+1
Senão
Conforme foi explicado, o método das regiões de confiança constrói um modelo quadrático da forma:
onde, no método, e . Em tal modelo, tem-se
um vetor não nulo;
uma matriz simétrica (que pode não ser definida positiva)
O problema quadrático é
com .
Este é o problema que será tratado a seguir.
Exercício
Provar que sempre tem solução.
Resolução
Esboço: Como é uma função contínua e o conjunto onde se quer minimizar tal função é uma bola, em dimensão finita, trata-se de minimizar uma função contínua em um compacto. Esse é um problema que tem solução, pelo teorema de Weierstrass.
O exercício anterior garante que o método está bem definido, quer dizer, todas as etapas podem ser realizadas.
Este tipo de problema é muito frequente em ciências experimentais. Para ter um exemplo em mente durante a discussão que será feita mais adiante, considere as seguintes informações:
Segundo dados disponibilizados pelo IBGE, o Produto Interno Bruto per capita na cidade de São Paulo, no período de 2002 a 2005, foi (em reais): 17734, 19669, 20943 e 24083, respectivamente.
Com base nessas informações, como poderia ser feita uma previsão do valor correspondente ao ano seguinte (2006)?
Uma escolha possível seria supor que a cada ano o PIB aumenta uma aproximadamente constante, ou seja, usar um modelo linear para obter tal estimativa (que possivelmente será bem grosseira). Intuitivamente, bastaria analisar os dados disponíveis e a partir deles deduzir qual é o aumento que ocorre a cada ano. Depois, a previsão para 2006 seria aproximadamente igual à de 2005 somada com aquele aumento anual.
Esta idéia poderia até funcionar para o caso deste exemplo, mas o que fazer se a quantidade de dados disponíveis sobre algum fenômeno (ou alguma situação) for significativamente maior?
A melhor escolha, sem dúvida, é fazer uso de um computador para obter o modelo que melhor descreve o "comportamento" dos dados experimentais.
Em geral, os problemas de mínimos quadrados consistem em identificar os valores de determinados parâmetros, de modo que se satisfaçam certas equações . No contexto do exemplo anterior, se procura um modelo linear para os dados, ou seja, uma função que os descreva da melhor forma possível. Assim, os parâmetros a considerar são e . Os valores ideais para essas variáveis seriam aqueles que verificassem as seguintes equações:
Note que a partir dessas equações poderiam ser definidas as funções como:
É de se esperar que o sistema de equações obtido a pouco não admitirá uma solução exata, pois se tem mais equações do que variáveis.
Isso geralmente acontece, pois é comum haver uma quantidade de equações bem maior que o número de parâmetros a identificar. Em particular, quando todas as equações são lineares em suas variáveis, dificilmente existirá uma solução exata para o sistema linear resultante, pois este terá mais equações do que incógnitas (como no exemplo). Em geral, não é possível encontrar parâmetros que satisfaçam exatamente todas as equações. Por isso, costuma-se tentar identificar os parâmetros que "melhor se aproximam" de uma solução exata, em algum sentido.
Uma forma de obter uma solução aproximada (uma "quase-solução") resulta da seguinte observação: o valor de cada função em uma solução exata deveria ser zero. Se tal exigência é restritiva demais, e com ela não é possível encontrar qualquer solução, uma possibilidade seria exigir um pouco menos. Por exemplo, poderia ser exigido apenas que o valor de , para seja, em geral, pequeno. Uma das formas de capturar essa idéia em termos mais precisos é dizer que se pretende minimizar a soma dos quadrados dos valores de cada . Em símbolos, o problema passaria a ser:
Neste caso, para cada índice , a função é afim linear, ou seja:
onde e para cada . Deste modo, pode-se definir uma função como
de modo que
Motivando a introdução da seguinte notação:
Assim,
Logo, buscar uma solução exata é o mesmo que procurar uma solução para o seguinte sistema linear:
E uma solução aproximada poderia ser buscada a partir do seguinte problema de minimização:
Exercício
Verifique que se houver uma solução exata, ela também será um minimizador de . A recíproca é verdadeira?
Resolução
Primeiramente, observe que para qualquer tem-se
Isso significa que é uma cota inferior para os valores assumidos por esta soma de quadrados.
Além disso, se é uma solução exata, então para cada índice tem-se:
e consequentemente
Então, em a soma dos quadrados assume seu valor mínimo.
Não vale a recíproca, pois se para um certo a soma dos quadrados assumir um valor positivo , então
implica que existe algum tal que
Isto significa que não satisfaz a equação de índice , e portanto não pode ser uma solução exata.
Analisando a função objetivo do problema de minimização anterior, tem-se:
Logo, como é simétrica e semi-definida positiva, tem-se convexa. Isso implica que a condição necessária de primeira ordem é também suficiente. Assim, qualquer ponto tal que é solução do problema aproximado.
Calculando o gradiente da função objetivo tem-se:
Deste modo, a solução do problema é obtida resolvendo o sistema
Considere dado um conjunto de pontos do plano , por exemplo , representando dados obtidos experimentalmente.
Perguntas:
1. Qual é a função afim linear que melhor se aproxima dos dados experimentais?
Resolução
As funções afim lineares no plano são aquelas que possuem a forma . Então os parâmetros a identificar são e .
Como são as funções ? Lembrando que tais funções teriam imagem igual a zero em uma solução exata, pode-se tomar
Assim,
A expressão final pode ser simplificada adotando a seguinte notação
De fato, nesses termos tem-se
2. Qual é a função quadrática que melhor se aproxima dos dados experimentais?
Resolução
As funções quadráticas possuem a forma . Então os parâmetros a identificar são , e .
Pode-se tomar .
Procedendo como antes, tem-se
onde
Exercício
Explorar o exemplo anterior com dados concretos, implementando um dos três métodos de gradientes conjugados.
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Observações
Conforme se aumenta o grau do polinômio que faz a aproximação dos dados, as colunas de têm elementos elevados a potências cada vez maiores, fazendo com que os autovalores de sejam cada vez mais dispersos. Com isso, torna-se mal condicionada.
Exercício
É possível, usando o problema de mínimos quadrados, verificar o postulado de Euclides que diz que "por dois pontos distintos passa uma única reta"?
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Exercício
Usando o problema de mínimos quadrados, é possível inferir que "por três pontos distintos passa uma única curva quadrática"?
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Para entender a essência do método de Newton, primeiro considere que o problema a ser resolvido é
sendo , e portanto de classe . A idéia de Newton é usar o desenvolvimento até segunda ordem da série de Taylor da função em cada ponto iterado. Isto é, se o iterado é , então:
Então a condição de Newton é que em cada iteração a Hessiana deve ser definida positiva.
Calculando o gradiente da função , segue:
Se é o (único) minimizador de , então
donde
Sendo definida positiva, tal matriz é também inversível. Portanto:
Início: Tome
Se , pare: é ponto crítico.
Senão, Calcule , solução de
Faça e
Iteração: Se , pare: é ponto crítico.
Senão, calcular , solução de
Faça e
Voltando ao problema original, de mínimos quadrados, se tinha:
Calculando o gradiente desta função, resulta:
Considera-se definida por
Deste modo, a Jacobiana de verifica:
pois o produto de uma matriz por um vetor tem como resultado um vetor que é a combinação linear das colunas da matriz, com coeficientes que são as coordenadas do vetor.
Além disso, tem-se
Seja
Sabe-se que uma matriz é definida positiva se para qualquer . Fazendo , tem-se:
Para que seja definida positiva, é necessário que ( deve gerar todo o espaço), neste caso, se diz que é de posto máximo.
Início: Tome
Se , pare: é ponto crítico.
Senão, Calcule , solução de
, onde
Faça e
Iteração: Se , pare: é ponto crítico.
Senão, calcular , solução de
Faça e
A idéia de Levemberg-Marquardt foi perturbar a matriz , considerando , para algum pequeno.
Início: Tome
Se , pare: é ponto crítico.
Senão, Calcule , solução de
, onde
Faça e
Iteração: Se , pare: é ponto crítico.
Senão, calcular , solução de
Faça e
Exercício
Enumere as diferenças que existem nos seguintes algoritmos:
Newton
Gauss-Newton
Levenberg-Marquardt
Resolução
Newton
Desenvolvendo em série de Taylor e exigindo que a matriz hessiana de seja definida positiva o método de Newton usa .
Gauss-Newton
Em alguns casos a matriz hessiana de pode ser bem complicada. Nesses casos então a idéia do método de Gauss-Newton é usar uma boa aproximação para essa matriz.
Podemos escrever
.
Usando Taylor em temos:
onde é a jacobiana de .
Substituindo na temos
Calculando o gradiente e depois a segunda derivada temos:
e
Denotando , então o método de Gauss-Newton escolhe tal que
.
Levenberg-Marquardt
A idéia do método de Levenberg-Marquardt é pertubar a matriz um pouco, considerando com pequeno.
Portanto o método de Levenberg-Marquardt escolhe tal que
Neste capítulo o objetivo é desenvolver algumas ideias e provar o teorema de Karush–Kuhn–Tucker (também chamado simplesmente de teorema KKT) que será utilizado no capítulo seguinte para explorar os métodos duais.
O teorema KKT é bem útil para resolver problemas do tipo
Em outras palavras, a propriedade que caracteriza um cone é que este tipo de conjunto contém todos os múltiplos não nulos de qualquer de seus elementos.
Definição
Dado um subconjunto , o cone polar de é o conjunto definido por
.
Observações:
é um cone: Se tem-se que . Logo, para qualquer , vale . Disto segue que , mostrando que é um cone.
Sempre se tem que (Verifique).
Na segunda propriedade a igualdade pode não ocorrer (exemplo?). Para o objetivo deste texto, o ideal seria que a igualdade valesse. Mas será que isso ocorre para algum conjunto? A resposta é sim e, conforme o próximo lema, basta que seja um cone convexo fechado.
Este módulo tem a seguinte tarefa pendente: Incluir a definição de projeção antes deste ponto, pois ela será usada durante a demonstração
Lema (Farkas)
Se um cone convexo fechado, então .
Demonstração
Seja e . Sabendo que a projeção de um ponto sobre um conjunto convexo é única, será mostrado que e então ficará provada a inclusão . Disto seguirá a igualdade entre os dois conjuntos, já que é sempre um subconjunto de .
Pelo teorema da projeção (ver Izmailov & Solodov (2007)), tem-se que . Usando o fato de que é cone, segue que e e substituindo isto na equação acima obtem-se
e .
Dessas desigualdades, conclui-se que .
De , tem-se que .
Usando a definição de cone polar, isso implica que .
Uma vez que , significa que .
Desses fatos acima se conclui que
Isso mostra que .
Definição
Dado , se diz que é uma direção viável em , com respeito a , quando existe tal que
.
O conjunto de todas as direções viáveis em , com respeito ao conjunto , será denotado por .
Esse conjunto é o cone das direções viáveis em , com respeito a .
Definição
Uma direção é uma direção de descida da função em , se existe tal que
.
O conjunto das direções de descida será denotado por .
Um vetor é chamado direção tangente em a partir de quando ou ou tal que
e .
Observações
O conjunto de todas as direções tangentes no ponto , é denominado cone tangente, e denotado por .
Se , então também pode ser descrito como
Exercício
Verifique que é de fato um cone (e portanto merece ser chamado de "cone tangente").
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Para permitir a compreensão da importância da função lagrangiana em otimização, é preciso ter em mente os principais resultados que garantem a otimalidade de uma solução para o problema . Nas próximas seções será apresentado um breve resumo das condições de otimalidade, dividindo-as em dois casos:
Seja função de classe no conjunto . Se é um minimizador local de no conjunto convexo e fechado , então:
Demonstração
Seja uma solução de , e fixe um ponto arbitrário . Denote por a restrição da função sobre o segmento de reta que passa por e por , ou seja,
, com .
Note que .
Como é um minimizador de em , tem-se:
, para todo
Logo,
, ou seja,
Mas pela regra da cadeia,
, então .
Como era arbitrário, o resultado está demonstrado.
Observação
A condição significa que os vetores e formam um ângulo reto ou agudo (menor ou igual a 90 graus), conforme indicado na figura a seguir:
Em um ponto de mínimo, sempre forma ângulo menor ou igual a 90 graus com os vetores do tipo , onde é um ponto de mínimo da função no conjunto viável e é um ponto qualquer deste conjunto.
No caso específico, com e , é a derivada direcional de na direção . Quando tal número é não negativo, intuitivamente a função cresce naquela direção.
Quando é um conjunto convexo e fechado, a existência de uma solução para o problema é garantida pela seguinte proposição:
Proposição
Se , é convexa e
então é um minimizador global de no conjunto (isto é, é solução de ).
Demonstração
Pela convexidade de , tem-se que:
Logo,
Portanto, , ou seja, é um minimizador de em .
Até aqui, não é exigido que qualquer das funções ou sejam diferenciáveis. Isto será utilizado mais adiante, nos algoritmos.
A próxima proposição fornece uma caracterização dos minimizadores, em termos do conceito de projeção.
Lembre-se que a projeção de um ponto sobre o conjunto , denotada por , satisfaz . Na verdade, vale:
O vetor forma ângulo menor que 90 graus com o vetor , pois é a projeção de sobre o conjunto .
Proposição
Seja um número real fixado.
Se é um minimizador local de em , então
Se é convexa e , então é um minimizador global de em .
Demonstração
(1)
Como é um minimizador local de em , então
Observe que essa desigualdade equivale à
ou ainda
Tomando e , tem-se a equivalência com:
que equivale a dizer que , ou seja:
(2)
Reciprocamente, supor que , conforme a argumentação anterior, equivale a dizer que
Usando a hipótese de que é convexa, segue da proposição anterior que é um minimizador global de em .
Para tratar este caso, é preciso utilizar o conceito de cone tangente. O conjunto contínua o mesmo, ou seja, , embora não seja mais suposto que ele é convexo. Mesmo assim, ainda será fechado, pois as funções e que o definem são contínuas.
Teorema
Se é um minimizador local de em , então .
Se é convexo, é convexa e , então é minimizador global de em .
Este teorema pode ser demonstrado de forma análoga a que foi feita anteriormente.
Demonstração
Esta demonstração é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Seja definido como:
.
Pela segunda propriedade do cone tangente, tem-se:
. Logo,
Em outras palavras, se é dado um conjunto e depois se restringe tal conjunto para , através do acréscimo de restrições inativas em um ponto , os cones tangentes aos dois conjuntos (no ponto ) coincidem.
Definição
Toda condição que implica que é chamada de condição de qualificação das restrições.
Note que aqui aparece a lagrangiana, pois a primeira condição é equivalente a:
O essencial para a existência de é que .
Teorema
Suponha-se que , e são funções de classe em uma vizinhança de , que e são convexas e que são afim-lineares. são funções de classe . Se existem e tais que:
A partir deste teorema são construídos alguns algoritmos.
Este módulo tem a seguinte tarefa pendente: Confrontar as informações presentes nestes últimos teoremas com algum livro. Parece estar precisando de pequenas correções.
Considere o seguinte problema:
Sabe-se que dada por
.
Agora, tem-se as KKT:
Teorema
Supondo que e são de classe em uma vizinhança de e que , se é um minimizador local de em , então tal que de modo que:
Sejam e dois subconjuntos arbitrários e considere uma aplicação
. Então
Demonstração
Sabe-se que
,
quaisquer que sejam . Então, calculando o ínfimo em ambos os membros (com relação aos valores de ), e considerando que pode ser ilimitado inferiormente, tem-se para qualquer :
Assim, calculando o supremo (com relação aos valores de ), segue das desigualdades anteriores:
Exercício
Verifique que:
Demonstração
Esta demonstração é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Defina-se a função:
, dada por
e também
, dada por
Conforme o exercício anterior, tem-se então
Observando a relação entre essas funções, é natural considerar dois problemas de otimização:
e
Comentários
As funções e são conhecidas na literatura como funções em dualidade (ou mais frequentemente, funções duais);
O problema é conhecido como problema primal, enquanto é chamado de problema dual;
Fazendo e , segue-se do exercício anterior que ;
A diferença é chamada de brecha de dualidade, ou salto de dualidade (do inglês, skip duality);
Exercício
Verifique que:
Resolução
Se tem-se que e .
Substituindo na lagrangeana tem-se que e tomando , se vê que o supremo dos valores é atingido, tendo como valor.
Por outro lado, se existe um índice tal que e/ou .
No primeiro caso, seja e
, onde .
Com esta escolha, a lagrangiana será
.
Tomando o limite quando tem-se que .
Para o outro caso a prova é análoga.
Exercício
Verifique que consiste de maximizar uma função côncava em um poliedro. Lembre-se:
Uma função é côncava quando for convexa.
Um poliedro é qualquer intersecção finita de semiespaços fechados.
Resolução
Primeiro será mostrado que :, dada por é uma função côncava. Para isso, basta mostrar que para cada vale
.
Chamando e tem-se:
Quanto ao conjunto ser um poliedro, isso segue do fato de e serem interseções finitas de semiespaços fechados.
Primeiramente, é preciso identificar quais são as funções e envolvidas:
A função objetivo é aquela que se pretende minimizar, ou seja, ;
Como aparecem apenas restrições de desigualdade, não há qualquer função ;
Reescrevendo as desigualdades como e , conclúi-se que as funções são:
e .
Neste caso, a lagrangiana é:
, dado por
Em seguida, é preciso calcular e :
, é dada por
E, conforme um dos exercícios anteriores (ou através de uma breve análise dos supremos envolvidos na expressão anterior), tem-se:
Analogamente, tem-se:
, dada por
Observe que em relação a , tem-se uma função fortemente convexa, que portanto possui um único minimizador. Além disso, é diferenciável, donde o seu único minimizador é dado pela equação:
ou seja,
donde
Portanto,
Assim, os problemas em dualidade são:
e
Pelo primeiro item do exercício, tem-se que a minimização do problema é equivalente à minimização do problema original.
Por outro lado, através da lagrangiana, obtem-se além do problema primal , um problema dual , cuja estrutura é muito melhor que a do original (pois pelo outro exercício, consiste da maximização de uma função côncava em um poliedro), e que servirá para encontrar o mínimo do problema primal (e consequentemente, do original).
Considerando , , e , se é uma solução do problema dual, considere o seguinte problema:
que no caso do exemplo reduz-se a
A solução deste problema é obtida resolvendo , sendo portanto . Note que esta é a solução do problema primal (e consequentemente do problema original ).
Será apenas uma coincidência? Ou ainda, em que situações a solução deste último problema será também solução do problema original?
A resposta será dada pelo próximo teorema. Acompanhe.
Teorema (dualidade lagrangiana convexa)
Suponha-se que são de classe e convexas, e que as funções são afim lineares e . Nestas condições:
Se o problema tem solução, então e os problemas e têm solução.
Se tem solução, e é solução de , então as soluções de são as soluções de , onde
que também são as soluções de .
Antes da demonstração, vale a pena imaginar a seguinte aplicação da segunda parte do teorema: Se por alguma razão não se sabe resolver o problema original , pode-se optar por resolver (um problema concavo em um poliedro), e depois resolver (que é um problema convexo sem restrições). Em outras palavras, é possível trocar um problema difícil por dois problemas mais fáceis, e .
Agora a demonstração do teorema:
Demonstração
(1) Como tem solução, seja uma solução de . Pelo teorema de KKT (que se aplica pois as funções são de classe e se tem a qualificação das restrições), segue a existência de e , tais que:
Como são funções convexas e afim lineares, então a função lagrangiana é convexa em (pela forma de ). Isto significa que:
.
Usando (1), conclúi-se uma das duas desigualdades que definem um ponto de sela em :
.
Considerando que é solução de , tal ponto satisfaz as restrições e . Então, usando , segue que:
pois e .
Mas, por KKT, . Além disso, .
Logo:
Assim,
quaisquer que sejam , e . Mas isso implica, por definição, que é um ponto de sela de .
Logo, , é solução do problema primal e é solução do problema dual
(2)Seja solução de (que existe, pelo item 1). Sabe-se pelo item anterior que o problema primal tem solução e que .
Seja solução de . Então, é ponto de sela de , logo valem as desigualdades:
.
Uma vez que está fixo e a segunda desigualdade vale para qualquer , conclui-se que é solução do problema
As soluções deste problema são soluções de e, consequentemente, do problema original.
Exercício
Verificar se existe salto de dualidade nos problemas em dualidade para o seguinte problema de minimização:
Exercício
Juntamente com o problema do exercício anterior, considere o seguinte problema:
Os problemas são equivalentes? (no sentido de que têm as mesmas funções objetivo e o mesmo conjunto de restrições) O que acontece com relação às condições de KKT?
Apesar de não ser convexa, é válido o resultado do teorema? Para que serve KKT? É possível resolver o problema dual e usar a resposta para resolver o primal?
Exercício
Experimente escolher e uma transformação linear, e um poliedro (intersecção finita de semi-espaços). É difícil de resolver o problema primal. Tente resolver o dual, usando os métodos conhecidos.
A seguir será apresentada uma proposição que responde a uma pergunta deixada anteriormente:
Proposição
Considere o problema a lagrangiana e os problemas em dualidade e e soluções de .
Se é solução do problema
(o conjunto dos pontos que satisfazem as restrições) e , então é também uma solução do problema .
Tal proposição fornece um roteiro para quem precisa resolver o problema relativamente difícil:
Primeiramente, resolve-se ;
Depois, constrói-se o problema e encontra-se uma solução para o mesmo;
Finalmente, se satisfaz as últimas condições da proposição, ele é também uma solução de .
Demonstração
Se é uma solução de , . Então, pela definição de , tem-se:
Como é solução de , então:
ou seja,
Portanto,
Por outro lado, como , tem-se e .
Por hipótese, , então
Logo,
.
Então para tem-se que e . Consequentemente,
quaisquer que sejam , ou seja,
,
quaisquer que sejam .
Portanto, é ponto de sela de , e assim, é solução primal (solução de ), e em consequência, solução de .
Neste ponto, pode-se sintetizar a estratégia geral para a resolução de problemas de otimização utilizando esquemas de dualidade.
Considere o problema
onde são funções de classe , e seja a lagrangiana definido por
.
Convenciona-se que:
é a variável primal;
é a variável dual;
Nesse sentido, "o é o dual de " (não confundir com o significado que essa expressão teria na análise funcional. Ver nota sobre a terminologia), ou seja:
é onde "mora" a variável primal ;
é onde "mora" a variável dual ;
Definem-se então as funções e da seguinte maneira:
, dada por
e
, dada por
A partir destas duas funções, formulam-se os seguintes problemas duais:
e
É possível verificar que equivale ao problema original e que consiste da maximização de uma função côncava em um poliedro (convexo).
Dado qualquer problema , seu dual é um problema côncavo (isto é, a função objetivo é côncava), tal que os pontos satisfazendo o conjunto de restrições formam um poliedro convexo.
Apesar da controvérsia filosófica existente acerca do nome destes conceitos (coisa que poderia muito bem vir a ser alterada no futuro), a moral da história é que "transforma-se um problema geralmente difícil (sem estrutura) em um problema mais fácil (cheio de estrutura)".
Na subárea da matemática denominada Análise Funcional, quando se tem um espaço topológico , costuma-se chamar de dual topológico ao conjunto .
Aparentemente, os conceitos de dual da otimização e da análise funcional não tem relação um com o outro.
Um dos primeiros a falar de dualidade (espaços duais) foi o francês Fenchel, mas foi fortemente criticado por Urruty e Lemaréchal, pois os dois conceitos de dualidade não estão relacionados. Também o francês Brezis concordou que há um problema a ser resolvido com a nomenclatura, e um dos conceitos deveria deixar de ser chamado assim.
Considere um problema típico da programação linear como:
onde são dados , , , , , , e . Por simplicidade, pode-se ainda adotar a seguinte notação:
Nesta seção será mostrado como a "bonita teoria dos métodos duais" se aplica a esse tipo de problema.
Primeiramente, calcula-se a lagrangiana:
Note que:
As variáveis primais são e ;
As variáveis duais são , e ;
Agora é preciso identificar as funções e correspondentes a este problema. Conforme anteriormente, tem-se:
, dada por
e
, dada por
Logo, considerando que , o problema dual consiste no seguinte:
Exercício
Verificar que é uma solução de
se, e somente se, é uma solução de
Resolução
Seja uma solução de . Então, por definição, tem-se para todo que
mas isto equivale a
ou seja, é uma solução de .
Exercício
Verificar que:
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Um empresário que produz cerveja dispões de 240 kg de milho, 5 kg de lúpulo e 596 kg de Malta. Para produzir um barril de cerveja preta requer 2,5 kg de milho, 0,125 kg de lúpulo e 17,5 kg de malta. Enquanto que para produzir um barril de cerveja branca, se precisa de 7,5 kg de milho, 0,125 kg de lúpulo e 10 kg de malta. Por barril de cerveja branca vendido, o empresário recebe 130 reais, enquanto por um barril de cerveja preta, recebe 230 reais. Achar o modelo matemático para otimizar o ganho do empresário.
Resolução
Primeiramente, é preciso identificar quais são as variáveis do problema, e quais são os dados. Pode-se adotar a seguinte notação para as quantidades dos dois tipos de cerveja:
: Indica a quantidade (em litros) de cerveja preta;
: Indica a quantidade (em litros) de cerveja branca;
O ganho do empresário, que é o que se pretende maximizar, pode ser obtido pela fórmula:
Por hora, considere que são aceitáveis os valores de e serem reais (não apenas inteiros positivos, mas também "números quebrados" como , , etc).
Como o estoque de cada ingrediente é limitado, tem-se restrições que devem ser consideradas. Matematicamente tais restrições podem ser expressas assim:
Pode-se simplificar a escrita das restrições e também da função objetivo utilizando a seguinte notação:
Nesses termos, o problema de otimização a ser resolvido é:
ou apenas,
onde é o conjunto definido pelo conjunto de restrições:
Tal problema tem solução pois a função objetivo é linear (contínua) e o conjunto de restrições forma um conjunto compacto.
Para este problema, a lagrangiana é dado por
Donde
Então, o problema dual é dado por
que é equivalente a
ou, escrevendo novamente em termos dos valores numéricos,
Na década de 30, 40 e 50 havia diversos livros que tratavam cada problema de programação linear individualmente, deduzindo vez após vez os seus duais, e disso extraindo certas "regras" que eram então sugeridas ao leitor na forma "se o problema for desse tipo, use tal regra, se for daquele tipo, use esta outra, e se for deste outro tipo, use esta regra". Um dos primeiros autores que começou a trabalhar os problemas sob um novo ponto de vista, mais generalizado, foi Werner Oettio (grafia?) . Seguindo-se por George Dantzig (conhecido como inventor do método simplex), Eugen Blumb (grafia?) e Jean-Pierre Crouzeix.
Este módulo tem a seguinte tarefa pendente: Identificar e corrigir a grafia correta dos nomes dos pesquisadores mostrados acima; Encontrar fontes para comprovar a informação deste parágrafo.
onde é um poliedro (interseção finita de semi-espaços), , e é uma matriz simétrica positiva definida.
Note que este problema tem solução, uma vez que o problema irrestrito correspondente tem solução (já que é uma matriz simétrica positiva definida, a função é limitada inferiormente, e como é fechado, a função objetivo assume seu valor mínimo em , por Wolfe).
Mesmo para , os problemas de programação linear já são difíceis de resolver "à mão". É preciso utilizar alguma técnica mais sofisticada.
Para dar continuidade ao exemplo, considere que o poliedro é dado por
com e .
Agora será aplicado o esquema de dualidade. A lagrangiana é
além disso,
e a última igualdade vale pois a função é fortemente convexa.
Considerando , se deduz que
.
Logo,
Observe que, sendo os autovalores de positivos, o mesmo vale obrigatoriamente para . Assim, como a expressão de envolve , tal função é fortemente côncava (conforme já era esperado para tal função).
Baseado nestas deduções, o problema dual é
ou seja,
Usualmente este tipo de problema é resolvido por meio do método do gradiente projetado.
Primeiro passo:
Escolha e fixe .
Passo iterativo : Enquanto
Agora, é interessante observar como se faz para projetar um ponto em .
Exercício
Dado , mostre que
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Agora, substituindo tal solução na lagrangiana, obtem-se o problema:
que é um problema quadrático sem restrições. Neste caso, basta igualar o gradiente a zero para determinar uma solução:
Donde e . De acordo com a teoria desenvolvida, a solução do problema é também solução do problema original, pois o produto é igual a zero (ver condições da proposição).
Encontrar a solução do seguinte problema de programação linear:
sendo
Resolução
Primeiramente observe que , então não é possível obter uma interpretação geométrica do problema. Será usado o esquema de dualidade lagrangiana:
Identificar a lagrangiana
Identificar a função
Identificar o problema dual
que equivale a
ou simplesmente
Agora, se tem um problema em , e portanto, pode-se ter uma interpretação geométrica para o mesmo:
Este módulo tem a seguinte tarefa pendente: Incluir ilustração do conjunto dos pontos que verificam as restrições do problema dual, bem como algumas curvas de nível da função objetivo (as mais relevantes).
As inequações que definem o conjunto viável são:
Tal conjunto é um pentágono (irregular, mas convexo), logo o valor máximo de é assumido quando for um dos cinco vértices. Através de simples verificação, comprova-se que o ponto de máximo é . Conforme a teoria, este ponto é uma solução do problema dual .
Como é um problema diferenciável e convexo (as condições de KKT são necessárias e suficientes), o dual terá solução e as duas juntas compõe um ponto de sela de .
Considere as condições de KKT:
, ou seja,
, ou seja,
, ou seja,
Note que, a partir de 2 e 3, conclui-se que 4 só é possível quando .
Para se obter , basta lembrar que em se tem:
(comprovando 1)
Logo,
comprovando a propriedade (2).
Como valem as propriedades (3) e (5), tem-se:
Donde . Resta usar a informação da propriedade (4) para obter e . O sistema pode ser escrito como:
Logo, e .
Se , e satisfazem todas as propriedades, então é solução do problema , pois todas as condições de KKT são necessárias e suficientes.
Ao resolver o problema , poderia ter sido escolhido em vez de . Será que isso influenciaria o resultado final?
Acompanhe como ficaria a resolução desta maneira:
Resolução
;Identificar a lagrangiana
Identificar a função
Identificar o problema dual
que equivale a
ou simplesmente
Novamente, chega-se até um problema em , que pode ser interpretado de forma geométrica.
Este módulo tem a seguinte tarefa pendente: Incluir ilustração do conjunto dos pontos que verificam as restrições deste problema dual, bem como algumas curvas de nível da função objetivo (as mais relevantes).
As inequações que definem o conjunto viável são:
Este conjunto também é um pentágono, de modo que o valor mínimo de é assumido quando for um dos cinco vértices. Através de simples verificação, comprova-se que o ponto de mínimo, ou seja uma solução do problema dual , é .
Nas condições de KKT, a única mudança é na propriedade (1), que se torna:
Resta ainda saber quem é e quem é :
como antes.
Como ao obter e chegou-se ao mesmo resultado de antes, o ponto continuará sendo o mesmo.
Exercício
Formule como um problema de minimização com restrições o problema de projetar ortogonalmente o ponto sobre o conjunto . Depois, calcule explicitamente a função lagrangiana e o problema dual.
Resolução
Matematicamente resolver esse problema é resolver
Definimos a lagrangeana como
Como a função é quadrática , podemos calcular o gradiente e igualar a zero:
Donde, e
Substituindo na função temos:
O problema dual fica então:
Que é equivalente a:
Exercício
No exercício anterior, se é a variável dual relacionada a variável primal e é a variável dual relacionada a variável primal , então verifique se é solução dual e se a lagrangiana tem pontos de sela. Em caso afirmativo, calcule um ponto de sela, caso contrário, argumente porque a lagrangiana não tem pontos de sela.
Resolução
Olhando o problema
observamos que é um problema com restrições.
Podemos usar as equações de KKT para resolve-lo.
Definimos a lagrangeana como
Agora usando o teorema de KKT devemos ter:
Calculando o gradiente temos
E portanto e .
Olhando nas equações acima obtemos , , e .
Portanto é a solução dual.
Voltando na lagrangiana do problema original e substituindo os multiplicadores de Lagrange obtemos um problema sem restrições:
Calculando o gradiente temos:
Portanto é a solução primal.
Logo é um candidato a ponto de sela.
Para verificar que ele é ponto de sela, basta ver se não há salto de dualidade. Mas isso não ocorre já que o valor ótimo do primal é e o valor ótimo do dual também é .
Sabe-se que se for aplicado o método da lagrangiana, será considerada a função:
dada por
.
e também
, dada por
A grande dificuldade seria saber quando o valor de é finito. Uma idéia seria modificar um pouco a lagrangiana (aumentando-a, com um termo extra), da seguinte maneira:
Com isso, seria necessário garantir que a idéia de fato resolve o problema. Por este motivo, é preciso desenvolver alguns resultados teóricos. Para fazer a análise deste método, um primeiro resultado importante é o seguinte:
Seja uma matriz simétrica e . As seguintes afirmações são equivalentes:
Se , com , então ;
Existe tal que a matriz é definida positiva;
Existe tal que a matriz é definida positiva para todo .
Demonstração
Primeiramente, será mostrado que a afirmação (2) é equivalente à afirmação (3).
Obviamente, (3) implica em (2).
Por outro lado, supondo que se tem (2), existe algum , tal que a matriz é definida positiva. Logo, para concluir a outra implicação, basta notar que para qualquer vale:
Assim, (2) também implica (3).
Agora, será mostrado que de (2) se conclui (1). De fato, se , para algum , então:
Finalmente, será garantido que se vale (1) então vale (3) (ver também página 25, de Izmailov & Solodov (2007)). Isso será mostrado por contradição, ou seja, supondo que vale (1) e que mesmo assim, não seja válido (3). Se disso seguir uma contradição, a implicação desejada é verdadeira.
Supondo que para todo tal que , tem-se , e que fosse falsa a afirmação (3), existiria para cada algum e algum de modo que
Neste caso, dividindo por , e denotando , segue que para cada , existe algum e algum , com , tais que
Como todos os estão na esfera unitária, que é compacta, a sequência tem algum ponto de acumulação, por exemplo . Passando o limite em , e considerando apenas a subsequência de que converge para , tem-se
(pois )
e
Neste caso,
só é possível se , ou seja, se . Logo,
contradizendo a hipótese (1).
Exercício
Prove a seguinte variante do lema anterior:
Seja uma matriz simétrica e semi-definida positiva, e . As seguintes afirmações são equivalentes:
Se , com , então ;
Existe tal que a matriz é definida positiva;
Para todo , a matriz é definida positiva.
A partir de agora, o problema será:
onde se supõe que são funções de classe e que para todo , o conjunto é compacto (em inglês costuma-se usar a expressão inf-compact para descrever tais funções).
Sabe-se que a lagrangiana associada ao problema é:
dada por
.
e ainda, em uma notação mais sintética, considerando a função dada por:
definida por
tem-se a lagrangiana expressa da seguinte maneira:
Para o método da lagrangiana aumentada serão assumidas as seguintes hipóteses:
Se é solução, então existe tal que ;
Para todo , o jacobiano de satizfaz:
Note que a segunda hipótese tem exatamente a mesma forma de uma das condições que aparece no lema de Finsler-Debreu.
Definição
Dado , se define a lagrangiana aumentada para o problema como:
dada por
Observe que é justamente a aparição do termo sendo somado à lagrangiana que justifica o nome lagrangiana aumentada.
Esse conceito possui algumas interpretações:
Exercício
Verifique que a lagrangiana aumentada é justamente a lagrangiana do problema penalizado, ou seja, de
Demonstração
Basta notar que dentro do conjunto viável as funções objetivos são iguais.
Exercício
Verifique que a função dual (o ínfimo da lagrangiana aumentada em relação à primeira componente), dada por
, com
para satisfaz
onde é solução de
Demonstração
E a segunda desigualdade
.
Exercício
Verifique que é compacto, qualquer que seja e .
Resolução
A resolução deste exercício é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
Proposição
Se é solução de , então existe algum , algum e alguma vizinhança de tais que é fortemente convexa com parâmetro .
Demonstração
Conforme o lema de Finsler-Debreu, a hipótese (2), segundo a qual para todo , o jacobiano de satizfaz:
equivale a dizer que existe algum tal que é definida positiva.
Mas a Hessiana de é dada por . Logo, a hipótese equivale a dizer que é definida positiva.
Considere agora a função definida por
Logo, para qualquer , tomando , tem-se
Pela continuidade da função , existe uma vizinhança de tal que para todo ponto , e qualquer que seja . Além disso, tal vizinhança pode ser tomada aberta, convexa e suficientemente pequena para que .
Assim, tomando o ínfimo, pode-se definir como
Então
quaisquer que sejam e .
Portanto,
ou seja, os auto-valores de são todos positivos.
Para concluir que é fortemente convexa, basta recordar-se de dois fatos:
Uma função de classe é convexa se, e somente se, é semidefinida positiva;
Uma função é fortemente convexa se, e somente se, existe uma constante tal que é convexa, ou seja, .
Com isso, é fortemente convexa pois
Isso significa que há um único mínimo local para tal função, e que consequentemente ele é um mínimo global. Das hipóteses 1 e 2 colocadas no início da discussão sobre a lagrangiana aumentada, segue que é fortemente convexa em .
Com essas condições, mostrou-se que em um ponto que seja solução, a lagrangiana aumentada é fortemente convexa.
Antes de apresentar o algoritmo, será fixada mais uma notação:
Início: Tome e .
Iteração: Calcule , solução de .
Se , pare: .
Senão, faça
Este é um dos algoritmos mais usados e mais eficientes para problemas de programação não linear. A garantia de convergência segue dos próximos teoremas.
Teorema
Sejam , e como na proposição anterior. Se é uma vizinhança de , existe algum tal que:
e
Observações:
denota as soluções do problema;
A igualdade significa que não há salto de dualidade.
Já foi mostrado que a função é fortemente convexa em uma vizinhança. Logo, os minimizadores devem estar em tal vizinhança.
A prova é um pouco técnica, e usa as condições de KKT, mostrando que o cone linearizado é igual ao cone tangente.
Prova
Esta prova é deixada a cargo do leitor. Sinta-se livre para melhorar a qualidade deste texto, incluindo-a na versão online deste material.
O segundo teorema é:
Teorema
Se é suficientemente grande e suficientemente pequeno, então:
é limitada
Observações:
A propriedade 2 praticamente segue do fato de não haver salto de dualidade.
Justificativa
Fica a cargo do leitor justificar este fato. Sinta-se livre para melhorar a qualidade deste texto, incluindo a justificativa na versão online deste material.
Com esses resultados, tem-se a garantia de que o algoritmo realmente converge para uma solução, desde que os parâmetros sejam tomados adequadamente. A questão que ainda permanece é como identificar os valores adequados de e de para que tal convergência ocorra.
Exercício
Argumente porque as hipóteses 1, 2 e 3 garantem que a iteração do algoritmo da Lagrangiana aumentada para problemas de minimização com restrições de igualdade tem uma única solução, sendo:
Todas as funções são de classe e a função objetivo tem todos os seus subníveis compactos.
Se é solução do problema, então existe tal que o gradiente da Lagrangiana não aumentada com respeito a variável primal se anula em .
A hessiana da Lagrangiana não aumentada com respeito a variável primal é definida positiva sob a variedade ortogonal de todos os gradientes no ponto das restrições.
Nesta página estarão indicadas as convenções adotadas neste wikilivro sobre otimização, no que diz respeito a sua formatação.
Recomenda-se a leitura do mesmo, por todos que pretendem contribuir com a melhoria desde texto.
As definições aparecem em caixas com essa aparência.
Observações
Geralmente um termo importante aparece pela primeira vez em uma definição.
Devido à sua importância, é bom destacar a definição do restante do texto.
No momento, a forma de destacar uma definição neste wikilivro é a inclusão de bordas duplas em torno do texto da definição, como no exemplo acima. Para facilitar essa tarefa, utiliza-se a predefinição {{Definição}}.
O conceito que está sendo definido costuma ser colocado em negrito, sendo que o texto da explicação tem sido alinhado a esquerda.
Faltam capítulos neste índice. Ampliando-o você ajudará a melhorar o Wikilivros.
Nesta página estão listados os conceitos abordados neste livro em ordem alfabética.
O nome de cada conceito possui um link para a página onde o mesmo é definido. Outras ocorrências importantes do conceito são indicadas pelos links numerados, logo após o link principal.




![{\displaystyle t\in \left[0,1\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fd270c3bd356bcd89e081db8a147db4ac9552d8)

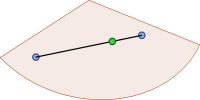 Este é um conjunto convexo, pois todo segmento com extremidades no conjunto está totalmente contido no conjunto.
Este é um conjunto convexo, pois todo segmento com extremidades no conjunto está totalmente contido no conjunto. Este é um conjunto côncavo, pois existe um segmento com extremidades no conjunto que não está totalmente contido no conjunto.
Este é um conjunto côncavo, pois existe um segmento com extremidades no conjunto que não está totalmente contido no conjunto.


![{\displaystyle \forall t\in \left[0,1\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/710780acdb88127978532c76ffa317c7b45c7d5f)
































































































































































































































![{\displaystyle \Gamma =\Gamma _{1}\cup \left\{A\subset \mathbb {R} \cup \{\infty \}:\exists a\in \mathbb {R} ,A=\left]a,\infty \right]\right\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1714b9f65c53fef59fd69fcaa4fdb0428af11dd2)






















































![{\displaystyle H(x)=\sum _{i=1}^{p}[g_{i}^{+}(x)]^{2}+\sum _{j=1}^{q}[h_{j}(x)]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2e51af33f420b19b30310319bc2e0167c828ba34)















































































![{\displaystyle [0,t]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/37d2d2fa44908c699e2b7b7b9e92befc8283f264)



































![{\displaystyle \min _{x\in \mathbb {R} ^{n}}\sum _{i=1}^{p}\left[h_{i}(x)\right]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31c65c0dccda26b6c814e23c07fe3feb3edbe0eb)










![{\displaystyle \sum _{i=1}^{p}\left[h_{i}(x)\right]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/131785084391e0caf697c648b7e8b27953c8e22c)
![{\displaystyle \sum _{i=1}^{p}\left[h_{i}({\bar {x}})\right]^{2}\geq 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bb2b95348e4fd37a9cba97d9d9b72bd3abd1d30d)


![{\displaystyle \sum _{i=1}^{p}\left[h_{i}({\bar {x}})\right]^{2}=\sum _{i=1}^{p}0^{2}=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cde3e4232eb105d33817e83109d697cc9e0860a1)


![{\displaystyle \sum _{i=1}^{p}\left[h_{i}({\bar {x}})\right]^{2}=\epsilon >0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7d7519b5dc71ccd7d369658e92340d53c59a7939)






















![{\displaystyle f={\frac {1}{2}}\sum _{j=1}^{p}[h_{j}]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d8f3fe6e1ebe44c594125615efa1a5a377000b44)








![{\displaystyle x^{*}={\bar {x}}-\left[\nabla ^{2}f({\bar {x}})\right]^{-1}\nabla f({\bar {x}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65d5e7ce18c97bc0920de31d09c5dd24d6d1eda5)
![{\displaystyle x_{k+1}=x_{k}-\left[\nabla ^{2}f(x_{k})\right]^{-1}\nabla f(x_{k})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70ece61409bcdab05cb09433ee4dfcae51783720)





![{\displaystyle f(x)={\frac {1}{2}}\sum _{i=1}^{p}\left[h_{i}(x)\right]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0ebe363eac1b7b7878a343733dd696c9fbfd802c)


![{\displaystyle \nabla f(x)=\left[J_{H}(x)\right]H(x)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1981dd53fef487cb06c9112714d7065d7261e380)






![{\displaystyle x^{\top }\nabla h_{i}(x)\nabla h_{i}(x)^{\top }x=\left[\nabla h_{i}(x)^{\top }x\right]^{2}\geq 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/debb996bd3a9b547879dac97c408d3255cb28015)










![{\displaystyle d_{k}=-[\nabla ^{2}f(x_{k})]^{-1}\nabla f(x_{k})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/efa459e960557b31e43cd7dc4c7c2a37874a0f79)
![{\displaystyle f(x)={\frac {1}{2}}\sum _{i=1}^{p}[h_{i}(x)]^{2}={\frac {1}{2}}\|h(x)\|^{2}={\frac {1}{2}}h(x)^{\top }h(x)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a8d924c7d01070456ca1f925ff72c3601df9eb33)



![{\displaystyle {\begin{aligned}f({\bar {x}})&={\frac {1}{2}}h({\bar {x}})^{\top }h({\bar {x}})\\&={\frac {1}{2}}(h(x)+J(x)({\bar {x}}-x))^{\top }(h(x)+J(x)({\bar {x}}-x))\\&={\frac {1}{2}}[(h(x)^{\top }h(x)+2h(x)^{\top }(J(x)({\bar {x}}-x))+(J(x)({\bar {x}}-x))^{\top }(J(x)({\bar {x}}-x))]\\&=f(x)+h(x)^{\top }(J(x)({\bar {x}}-x))+(J(x)({\bar {x}}-x))^{\top }(J(x)({\bar {x}}-x))\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/84fc46bb08241432d8c29d3b44ae12c5374a364f)





































![{\displaystyle x+td\in C,\ \forall t\in [0,\epsilon ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/42160b30f043ed6b454d9c62417ec90bad473589)

![{\displaystyle f(x+td)<f(x),\ \forall t\in (0,\epsilon ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/38badef3296b3da0b153682a48476c8b0a272d18)





![{\displaystyle \forall t\in (0,\epsilon ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/60b51b81d0e2ae02a9aa399303f93385085c3d53)










![{\displaystyle \nabla f(x)^{\top }d+{\frac {o(t)}{t}}<0,\ \forall t\in (0,\epsilon ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c9a58c713fc0565aff73a531b1aff352b644c503)

![{\displaystyle f(x+td)<f(x)\ \forall t\in (0,\epsilon ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e11f8eb8731384e66d34fba0267ab5e6c8407f9b)






















































![{\displaystyle t\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31a5c18739ff04858eecc8fec2f53912c348e0e5)
































































































































































































































































![{\displaystyle {\begin{aligned}\beta ({\bar {u}},{\bar {v}})&=\inf _{x\in \mathbb {R} ^{n}}l(x,ta+(1-t)b,tc+(1-t)d)\\&=\inf _{x\in \mathbb {R} ^{n}}f(x)+(ta+(1-t)b)^{\top }g(x)+(tc+(1-t)d)^{\top }h(x)\\&=\inf _{x\in \mathbb {R} ^{n}}f(x)+ta^{\top }g(x)+(1-t)b^{\top }g(x)+tc^{\top }h(x)+(1-t)d^{\top }h(x)\\&=\inf _{x\in \mathbb {R} ^{n}}tf(x)+(1-t)f(x)+ta^{\top }g(x)+(1-t)b^{\top }g(x)+tc^{\top }h(x)+(1-t)d^{\top }h(x)\\&=\inf _{x\in \mathbb {R} ^{n}}t[f(x)+a^{\top }g(x)+c^{\top }h(x)]+(1-t)[f(x)+b^{\top }g(x)+d^{\top }h(x)]\\&=\inf _{x\in \mathbb {R} ^{n}}tl(x,a,c)+(1-t)l(x,b,d)\\&\geq \inf _{x\in \mathbb {R} ^{n}}tl(x,a,c)+\inf _{x\in \mathbb {R} ^{n}}(1-t)l(x,b,d)\\&=t\inf _{x\in \mathbb {R} ^{n}}l(x,a,c)+(1-t)\inf _{x\in \mathbb {R} ^{n}}l(x,b,d)\\&=t\beta (a,c)+(1-t)\beta (b,d).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/434f94214c721abea1b49027c86d23a09e6cdda7)











![{\displaystyle \alpha (x)=\sup _{\begin{smallmatrix}u_{1}\geq 0\\u_{2}\geq 0\end{smallmatrix}}[x^{2}+u_{1}(1-x)+u_{2}(x-2)]=x^{2}+\sup _{u_{1}\geq 0}[u_{1}(1-x)]+\sup _{u_{2}\geq 0}[u_{2}(x-2)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9082a1a4303bb18a33f94ea92a7ce881fd704ed6)
![{\displaystyle \alpha (x)=\left\{{\begin{matrix}x^{2}&,{\text{ se }}x\in [1,2]\\+\infty &,{\text{ se }}x\not \in [1,2]\end{matrix}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6439ceff6745a32d909c0b7036f317d6d7726133)

![{\displaystyle \beta (u_{1},u_{2})=\inf _{x\in \mathbb {R} ^{n}}[x^{2}+u_{1}(1-x)+u_{2}(x-2)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a98376c97397bf81c9b1fb4a087f4270c5347ad2)































![{\displaystyle {\begin{aligned}\beta (u,v)&={\frac {1}{4}}([u_{1}^{2}+u_{2}^{2}-2u_{1}u_{2}]+[4u_{1}-2u_{1}^{2}+2u_{1}u_{2}]+[2u_{1}u_{2}-2u_{2}^{2}-8u_{2}])\\&={\frac {-1}{4}}(u_{1}^{2}+u_{2}^{2}-2u_{1}u_{2}-4u_{1}+8u_{2})\\&={\frac {-1}{4}}((u_{1}-u_{2})^{2}-4(u_{1}-u_{2}))-u_{2}\\&={\frac {-1}{4}}((u_{1}-u_{2})^{2}-4(u_{1}-u_{2})+4)+1-u_{2}\\&={\frac {-1}{4}}(u_{1}-u_{2}-2)^{2}+1-u_{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6736fe63d7f9bf147b002019b991a95de3c9aa5b)






































































![{\displaystyle {\begin{aligned}l(x,y,u,v,w)&=[a^{\top }x+b^{\top }y]+u^{\top }[c-Mx-Ny]+v^{\top }[d-Px-Qy]+w^{\top }[-x]\\&=[a-M^{\top }u-P^{\top }v-w]^{\top }x+[b-N^{\top }u-Q^{\top }v]^{\top }y+[c^{\top }u+d^{\top }v]\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e9795bc33819ea6ded2faee23c6342d088aaa91d)


![{\displaystyle {\begin{aligned}\beta (u,v)&=\inf _{\begin{smallmatrix}x\in \mathbb {R} ^{n}\\y\in \mathbb {R} ^{m}\end{smallmatrix}}l(x,y,u,v,w)\\&=\inf _{\begin{smallmatrix}x\in \mathbb {R} ^{n}\\y\in \mathbb {R} ^{m}\end{smallmatrix}}[a-M^{\top }u-P^{\top }v-w]^{\top }x+[b-N^{\top }u-Q^{\top }v]^{\top }y+[c^{\top }u+d^{\top }v]\\&=[c^{\top }u+d^{\top }v]+\inf _{x\in \mathbb {R} ^{n}}[a-M^{\top }u-P^{\top }v-w]^{\top }x+\inf _{y\in \mathbb {R} ^{m}}[b-N^{\top }u-Q^{\top }v]^{\top }y\\&=\left\{{\begin{array}{rcl}c^{\top }u+d^{\top }v&,&{\text{ se }}\left\{{\begin{array}{rcl}a-M^{\top }u-P^{\top }v-w&=&0\\b-N^{\top }u-Q^{\top }v&=&0\\u\geq 0;\,w\geq 0&&\end{array}}\right.\\-\infty &,&{\text{ em outros casos}}\end{array}}\right.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4d20bf7eed8c149991ae2bdb6a1a670f7e73c65)






![{\displaystyle \inf _{x\in C}f(x)=-\sup _{x\in C}[-f(x)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/78c491f5e9259284908c4c5105782e8571b9e64d)




![{\displaystyle {\begin{aligned}\beta (u,v)&=\inf _{x\in \mathbb {R} ^{n}}l(x,u,v)\\&=\inf _{x\in \mathbb {R} ^{n}}[c^{\top }x-u^{\top }x+v^{\top }(b-Ax)]\\&=b^{\top }v+\inf _{x\in \mathbb {R} ^{n}}[c-u-A^{\top }v]^{\top }x\\&=\left\{{\begin{array}{rcl}b^{\top }v&,&{\text{ se }}c-u-A^{\top }v=0\\-\infty &,&{\text{ em outros casos}}\end{array}}\right.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6aa29a9fa7044b4e870a0f8b6a1eee1bf94a2ac2)




![{\displaystyle {\begin{aligned}\beta (y)&=\inf _{v\in \mathbb {R} ^{m}}l(v,y)\\&=\inf _{v\in \mathbb {R} ^{m}}[-b^{\top }v+y^{\top }(A^{\top }v-c)]\\&=-c^{\top }y+\inf _{v\in \mathbb {R} ^{m}}[(Ay-b)^{\top }v]\\&=\left\{{\begin{array}{rcl}-c^{\top }y&,&{\text{ se }}Ay-b=0\\-\infty &,&{\text{ em outros casos}}\end{array}}\right.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64b3e0e47b720debae6e525aff4d36c42bc3c9b7)













![{\displaystyle {\begin{aligned}\beta (u_{1},u_{2})&=\inf _{x\in \mathbb {R} ^{2}}l(x,u_{1},u_{2})\\&=\inf _{x\in \mathbb {R} ^{2}}[-c^{\top }x+u_{1}^{\top }(Ax-b)+u_{2}^{\top }(-x)]\\&=-b^{\top }u_{1}+\inf _{x\in \mathbb {R} ^{2}}[(A^{\top }u_{1}-c-u_{2})^{\top }x]\\&=\left\{{\begin{array}{rcl}-b^{\top }u_{1}&,&{\text{ se }}A^{\top }u_{1}-c-u_{2}=0\\-\infty &,&{\text{ em outros casos}}\end{array}}\right.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/27250eb024fcfe8c2e68b50168724881e65ab3ec)













![{\displaystyle {\begin{aligned}\beta (u,v)&=\inf _{x\in \mathbb {R} ^{n}}l(x,u,v)\\&=\min _{x\in \mathbb {R} ^{n}}l(x,u,v)\\&=\min _{x\in \mathbb {R} ^{n}}[{\frac {1}{2}}x^{\top }Qx+q^{\top }x+\alpha +u^{\top }(b-Ax)+v^{\top }(-x)]\\&=\min _{x\in \mathbb {R} ^{n}}[{\frac {1}{2}}x^{\top }Qx+(q-v-A^{\top }u)^{\top }x+u^{\top }b+\alpha ]\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fc3b26f3818cb072ed0ff02a6f2d0d197e78dfe)


![{\displaystyle {\begin{aligned}\beta (u,v)&={\frac {1}{2}}\left[Q^{-1}(A^{\top }u+v-q)\right]^{\top }Q\left[Q^{-1}(A^{\top }u+v-q)\right]+(q-v-A^{\top }u)^{\top }\left[Q^{-1}(A^{\top }u+v-q)\right]+u^{\top }b+\alpha \\&={\frac {1}{2}}(A^{\top }u+v-q)^{\top }Q^{-1}(A^{\top }u+v-q)-(A^{\top }u+v-q)^{\top }Q^{-1}(A^{\top }u+v-q)+u^{\top }b+\alpha \\&={\frac {-1}{2}}(A^{\top }u+v-q)^{\top }Q^{-1}(A^{\top }u+v-q)+u^{\top }b+\alpha \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9e1e44a9bfbc6d4aa51eee2654faf5e605253179)


















![{\displaystyle (P)\left\{{\begin{matrix}\min {\frac {1}{2}}\left[(x-1)^{2}+(y-2)^{2}\right]\\x\geq 0;y\geq 0\\x+y=1\end{matrix}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d144caecdd943e7fd612ef700be25e1fd18f5e22)
![{\displaystyle l(x,y,u,v,w)={\frac {1}{2}}\left[(x-1)^{2}+(y-2)^{2}\right]-ux-vy+w(1-x-y)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b8746439bd51c747f4e607d636f436f749dec212)
![{\displaystyle {\begin{aligned}\beta (u,v,w)&=\inf _{\begin{smallmatrix}x\in \mathbb {R} \\y\in \mathbb {R} \end{smallmatrix}}l(x,y,u,v,w)\\&=\inf _{\begin{smallmatrix}x\in \mathbb {R} \\y\in \mathbb {R} \end{smallmatrix}}\left[{\frac {1}{2}}\left[(x-1)^{2}+(y-2)^{2}\right]-ux-vy+w(1-x-y)\right]\\&=\inf _{\begin{smallmatrix}x\in \mathbb {R} \\y\in \mathbb {R} \end{smallmatrix}}\left[{\frac {1}{2}}\left[(x-1)^{2}+(y-2)^{2}\right]-(u+w)x-(v+w)y+w\right]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/052f7b8f409d7d4c2db6e665766d6a820856ca6f)



![{\displaystyle {\begin{aligned}\beta (u,v,w)&={\frac {1}{2}}\left[\left((u+w+1)-1\right)^{2}+\left((v+w+2)-2\right)^{2}\right]-(u+w)(u+w+1)-(v+w)(v+w+2)+w\\&={\frac {1}{2}}\left[(u+w)^{2}+(v+w)^{2}\right]-(u+w)(u+w+1)-(v+w)(v+w+2)+w\\&={\frac {-1}{2}}\left[(u+w)^{2}+(v+w)^{2}\right]-(u+w)-2(v+w)+w\\&={\frac {-1}{2}}\left[(u+w)^{2}+(v+w)^{2}\right]-u-2v-2w\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0d17baabd72efebb074f80c05af6d0f1a2fcadfa)

![{\displaystyle (D)\left\{{\begin{matrix}\min {\frac {1}{2}}\left[(u+w)^{2}+(v+w)^{2}\right]+u+2(v+w)\\u\geq 0;\,v\geq 0;\,w\in \mathbb {R} ^{m}\\\end{matrix}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/88059a5bb181cb90f094214106d5e5f200a70649)






![{\displaystyle (P_{{\bar {u}},{\bar {v}},{\bar {w}}})\left\{{\begin{matrix}\min {\frac {1}{2}}\left[(x-1)^{2}+(y-2)^{2}+x+y-1\right]\\x\in \mathbb {R} ;\,y\in \mathbb {R} \end{matrix}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/89baa1521eeb9fcd71c7dcbb03f7decbfcd0778e)











![{\displaystyle {\begin{aligned}\beta (u,v)&=\inf _{x\in \mathbb {R} ^{5}}l(x,u,v)\\&=\inf _{x\in \mathbb {R} ^{5}}[c^{\top }x-u^{\top }x+v^{\top }(b-Ax)]\\&=\inf _{x\in \mathbb {R} ^{5}}b^{\top }v+(c-u-A^{\top }v)^{\top }x\\&=\left\{{\begin{array}{rcl}b^{\top }v&,&{\text{ se }}c-u-A^{\top }v=0\\-\infty &,&{\text{ em outros casos}}\end{array}}\right.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/201890738663e2481680d82aa8ba93c8324fe597)





























![{\displaystyle {\begin{aligned}\beta (u,v)&=\inf _{x\in \mathbb {R} ^{5}}l(x,u,v)\\&=\inf _{x\in \mathbb {R} ^{5}}[c^{\top }x-u^{\top }x+v^{\top }(Ax-b)]\\&=\inf _{x\in \mathbb {R} ^{5}}-b^{\top }v+(c-u+A^{\top }v)^{\top }x\\&=\left\{{\begin{array}{rcl}-b^{\top }v&,&{\text{ se }}c-u+A^{\top }v=0\\-\infty &,&{\text{ em outros casos}}\end{array}}\right.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5e7d864b5f6d196acb889804e0cad857659dcb8e)








![{\displaystyle {\begin{cases}{\text{min}}{\frac {1}{2}}[(x+5)^{2}+(y-2)^{2}]\\x\geq 0\ y\geq 0\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b841db4ed1dcd9732f08f1feafa0c1c5acc1d9a8)
![{\displaystyle l(x,y,u,v)={\frac {1}{2}}[(x+5)^{2}+(y-2)^{2}]+u(-x)+v(-y)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9ac6224a1e39c15beb3fd0717d18b1fa9094ba77)

![{\displaystyle \beta (u,v)=\inf _{\begin{smallmatrix}x\in \mathbb {R} \\y\in \mathbb {R} \end{smallmatrix}}[{\frac {1}{2}}[(x+5)^{2}+(y-2)^{2}]-ux-vy]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e9c5876ef92fb5f4c1d340e65eae3f0d60b3567)




![{\displaystyle \beta (u,v)={\frac {1}{2}}[(u-5+5)^{2}+(v+2-2)^{2}]-u(u-5)-v(v+2)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70488a8e628701ae3c294697084654da87c1cc8c)
![{\displaystyle \beta (u,v)={\frac {1}{2}}[u^{2}+v^{2}]-u^{2}+5u-v^{2}-2v)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/14741b6807981e6a8a0a05f665977e559eb5884e)
![{\displaystyle \beta (u,v)=-[{\frac {1}{2}}(u^{2}+v^{2})-5u+2v)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e193f29895cf96fa1d45af955226f1cacd6e0063)
![{\displaystyle {\begin{cases}{\text{max}}-[{\frac {1}{2}}(u^{2}+v^{2})-5u+2v]\\u\geq 0\ v\geq 0\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/667abea79ac2247940a2b5158fb5e78f0223f465)

















![{\displaystyle {\begin{cases}{\text{min}}\ {\frac {1}{2}}[(x+5)^{2}+(y-2)^{2}]+5(-x)\\x,y\in \mathbb {R} \end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f5449ef78e4a750af717193b6dfa3cae186a774b)





















































![{\displaystyle {\begin{aligned}\beta _{\rho }(v)&=\inf _{x\in \mathbb {R} ^{n}}l_{\rho }(x,v)\\&=\inf _{x\in \mathbb {R} ^{n}}[f(x)+H(x)^{\top }v+{\frac {\rho }{2}}H(x)^{\top }H(x)]\\&\leq \inf _{x\in \mathbb {R} ^{n}}[f(x)+H(x)^{\top }v+{\frac {\delta }{2}}H(x)^{\top }H(x)]\\&=\inf _{x\in \mathbb {R} ^{n}}l_{\delta }(x,v)\\&=\beta _{\delta }(v)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/510d9848b9ec003b95f32153c926e82fb20c60ec)




















![{\displaystyle d^{\top }\left[\nabla _{x}^{2}l_{\rho _{0}}(x,{\bar {u}})\right]d\geq \delta _{0}\|d\|^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e0dc529c58b0c0a92681dd54e4af48d6cd9b292)





![{\displaystyle d^{\top }\left[\nabla _{x}^{2}l_{\rho _{0}}(x,{\bar {u}})\right]d-\delta _{0}\|d\|^{2}\geq 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d818ee502253f71d5f3485d5df365de3a29f34ae)
















